Descrever o streaming estruturado do Spark
O streaming estruturado Spark é uma plataforma popular para processamento na memória. Tem um paradigma unificado para batch e streaming. Qualquer coisa que você aprenda e use para lote, você pode usar para streaming, por isso é fácil crescer de lotes de seus dados para streaming de seus dados. O Spark Streaming é simplesmente um motor que funciona em cima do Apache Spark.
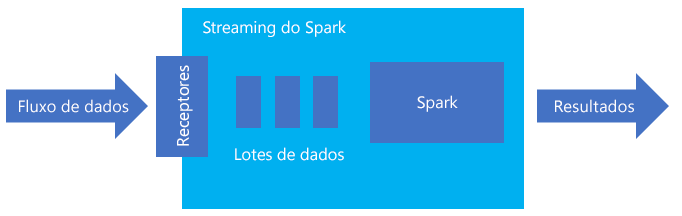
O Streaming Estruturado cria uma consulta de longa execução durante a qual você aplica operações aos dados de entrada, como seleção, projeção, agregação, janelas e junção do DataFrame de streaming com DataFrames de referência. Em seguida, você envia os resultados para o armazenamento de arquivos (Blobs de Armazenamento do Azure ou Armazenamento Data Lake) ou para qualquer armazenamento de dados usando código personalizado (como Banco de Dados SQL ou Power BI). O Streaming Estruturado também fornece saída para o console para depuração local e para uma tabela na memória para que você possa ver os dados gerados para depuração no HDInsight.
Fluxos como tabelas
O streaming estruturado do Spark representa um fluxo de dados como uma tabela que é ilimitada em profundidade, ou seja, a tabela continua a crescer à medida que novos dados chegam. Esta tabela de entrada é processada continuamente por uma consulta de longa execução e os resultados enviados para uma tabela de saída:

No Structured Streaming, os dados chegam ao sistema e são imediatamente ingeridos em uma tabela de entrada. Você escreve consultas (usando as APIs DataFrame e Dataset) que executam operações nessa tabela de entrada. A saída da consulta produz outra tabela, a tabela de resultados. A tabela de resultados contém os resultados da sua consulta, a partir da qual você extrai dados para um armazenamento de dados externo, como um banco de dados relacional. O tempo de quando os dados são processados da tabela de entrada é controlado pelo intervalo de disparo. Por padrão, o intervalo de gatilho é zero, portanto, o Streaming Estruturado tenta processar os dados assim que eles chegam. Na prática, isso significa que, assim que o Streaming Estruturado terminar de processar a execução da consulta anterior, ele iniciará outra execução de processamento em relação a quaisquer dados recém-recebidos. Você pode configurar o gatilho para ser executado em um intervalo, para que os dados de streaming sejam processados em lotes baseados no tempo.
Os dados nas tabelas de resultados podem conter apenas os dados que são novos desde a última vez que a consulta foi processada (modo de acréscimo), ou a tabela pode ser atualizada sempre que há novos dados para que a tabela inclua todos os dados de saída desde o início da consulta de streaming (modo completo).
Modo de acréscimo
No modo de acréscimo, apenas as linhas adicionadas à tabela de resultados desde a última execução de consulta estão presentes na tabela de resultados e são gravadas no armazenamento externo. Por exemplo, a consulta mais simples apenas copia todos os dados da tabela de entrada para a tabela de resultados inalterada. Cada vez que um intervalo de gatilho decorre, os novos dados são processados e as linhas que representam esses novos dados aparecem na tabela de resultados.
Considere um cenário em que você esteja processando dados de preço de ações. Suponha que o primeiro gatilho processou um evento no momento 00:01 para ações MSFT com um valor de 95 dólares. No primeiro gatilho da consulta, apenas a linha com o tempo 00:01 aparece na tabela de resultados. No tempo 00:02 quando outro evento chega, a única nova linha é a linha com tempo 00:02 e, portanto, a tabela de resultados conteria apenas essa linha.
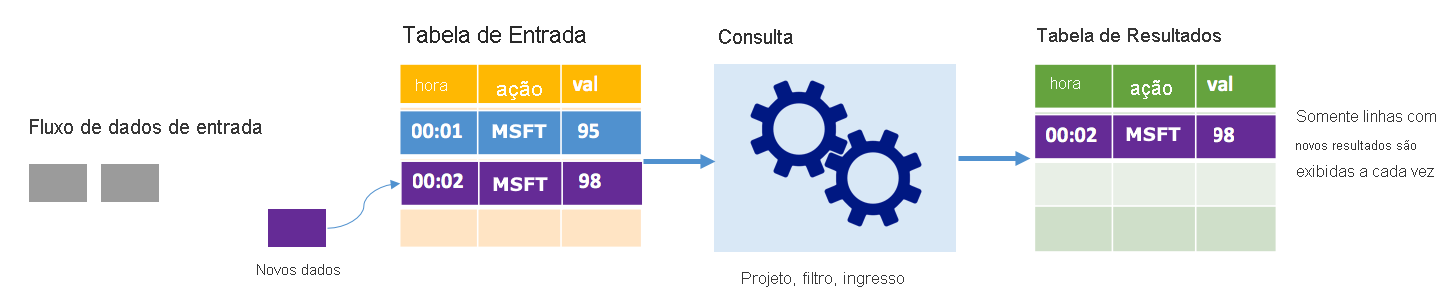
Ao usar o modo de acréscimo, sua consulta estaria aplicando projeções (selecionando as colunas que lhe interessam), filtrando (selecionando apenas linhas que correspondem a determinadas condições) ou unindo (aumentando os dados com dados de uma tabela de pesquisa estática). O modo de acréscimo facilita o envio apenas dos novos pontos de dados relevantes para o armazenamento externo.
Modo completo
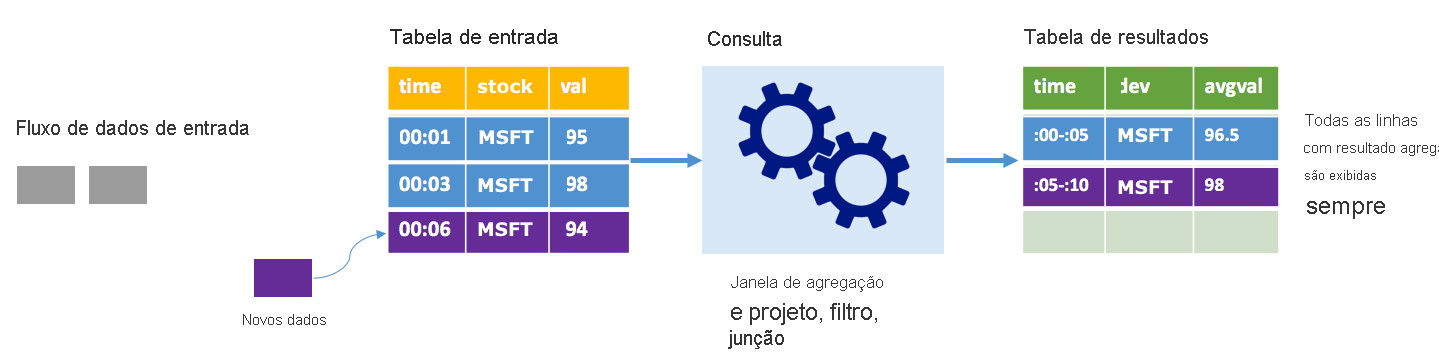
Considere o mesmo cenário, desta vez usando o modo completo. No modo completo, toda a tabela de saída é atualizada em cada gatilho para que a tabela inclua dados não apenas da execução de gatilho mais recente, mas de todas as execuções. Você pode usar o modo completo para copiar os dados inalterados da tabela de entrada para a tabela de resultados. Em cada execução acionada, as novas linhas de resultado aparecem junto com todas as linhas anteriores. A tabela de resultados de saída acabará armazenando todos os dados coletados desde o início da consulta e você acabará ficando sem memória. O modo completo destina-se ao uso com consultas agregadas que resumem os dados recebidos de alguma forma, portanto, em cada disparador, a tabela de resultados é atualizada com um novo resumo.
Suponha que até agora há cinco segundos de dados já processados, e é hora de processar os dados pelo sexto segundo. A tabela de entrada tem eventos para o tempo 00:01 e o tempo 00:03. O objetivo desta consulta de exemplo é fornecer o preço médio da ação a cada cinco segundos. A implementação dessa consulta aplica uma agregação que pega todos os valores que estão dentro de cada janela de 5 segundos, calcula a média do preço das ações e produz uma linha para o preço médio das ações nesse intervalo. No final da primeira janela de 5 segundos, há duas tuplas: (00:01, 1, 95) e (00:03, 1, 98). Assim, para a janela 00:00-00:05 a agregação produz uma tupla com o preço médio das ações de US $ 96,50. Na próxima janela de 5 segundos, há apenas um ponto de dados no momento 00:06, então o preço resultante das ações é de US $ 98. No momento 00:10, usando o modo completo, a tabela de resultados tem as linhas para ambas as janelas 00:00-00:05 e 00:05-00:10 porque a consulta gera todas as linhas agregadas, não apenas as novas. Portanto, a tabela de resultados continua a crescer à medida que novas janelas são adicionadas.
Nem todas as consultas que usam o modo completo fazem com que a tabela cresça sem limites. Considere no exemplo anterior que, em vez de calcular a média do preço das ações por janela, ele calculou a média por ação. A tabela de resultados contém um número fixo de linhas (uma por ação) com o preço médio das ações em todos os pontos de dados recebidos desse dispositivo. À medida que novos preços de ações são recebidos, a tabela de resultados é atualizada para que as médias na tabela estejam sempre atualizadas.
Quais são os benefícios do streaming estruturado do Spark?
Estando no setor financeiro, o timing das transações é muito importante. Por exemplo, em uma negociação de ações, a diferença entre quando a negociação de ações acontece no mercado de ações, ou quando você recebe a transação, ou quando os dados são lidos todos os assuntos. Para as instituições financeiras, elas dependem desses dados críticos e do momento associado a eles.
Hora do evento, dados atrasados e marca d'água
O streaming estruturado do Spark sabe a diferença entre a hora de um evento e a hora em que o evento foi processado pelo sistema. Cada evento é uma linha na tabela e a hora do evento é um valor de coluna na linha. Isso permite que as agregações baseadas em janela (por exemplo, o número de eventos a cada minuto) sejam apenas um agrupamento e agregação na coluna de tempo do evento – cada janela de tempo é um grupo e cada linha pode pertencer a várias janelas/grupos. Portanto, essas consultas de agregação baseadas em janela de tempo de evento podem ser definidas consistentemente em um conjunto de dados estático, bem como em um fluxo de dados, tornando a vida de um engenheiro de dados muito mais fácil.
Além disso, este modelo lida naturalmente com dados que chegaram mais tarde do que o esperado com base no seu tempo de evento. O Spark tem controle total sobre a atualização de agregados antigos quando há dados atrasados, bem como sobre a limpeza de agregados antigos para limitar o tamanho dos dados de estado intermediário. Além disso, desde o Spark 2.1, o Spark suporta marca d'água, que permite especificar o limite de dados atrasados e permite que o mecanismo limpe o estado antigo.
Flexibilidade para carregar dados recentes ou todos os dados
Conforme discutido na unidade anterior, você pode optar por usar o modo Acrescentar ou o modo Concluir ao trabalhar com streaming estruturado do Spark, para que sua tabela de resultados inclua apenas os dados mais recentes ou todos os dados.
Suporta a mudança de microlotes para processamento contínuo
Ao alterar o tipo de gatilho de uma consulta do Spark, você pode passar do processamento de microlotes para o processamento contínuo sem outras alterações na estrutura. Aqui estão os diferentes tipos de gatilhos que o Spark suporta.
- Não especificado, este é o padrão. Se nenhum gatilho for definido explicitamente, a consulta será executada em microlotes e processada continuamente.
- Microlote de intervalo fixo. A consulta é iniciada em intervalos recorrentes definidos pelo usuário. Se nenhum novo dado for recebido, nenhum processo de microlote será executado.
- Microlote único. A consulta executa um único microlote e, em seguida, para. Isso é útil se você quiser processar todos os dados desde o microlote anterior e pode fornecer economia de custos para trabalhos que não precisam ser executados continuamente.
- Contínuo com um intervalo de ponto de verificação fixo. A consulta é executada em um novo modo de processamento contínuo de baixa latência que permite latência de ponta a ponta baixa (~1 ms) com garantias de tolerância a falhas pelo menos uma vez. Isso é semelhante ao padrão, que pode alcançar garantias exatas uma vez, mas só atinge latências de ~100ms, na melhor das hipóteses.
Combinando trabalhos em lote e streaming
Além de simplificar a mudança de trabalhos em lote para trabalhos de streaming, você também pode combinar trabalhos em lote e streaming. Isso é especialmente útil quando você deseja usar dados históricos de longo prazo para prever tendências futuras enquanto processa informações em tempo real. Para ações, você pode querer olhar para o preço da ação nos últimos 5 anos, além do preço atual, para prever as mudanças feitas em torno de anúncios de receita anual ou trimestral.
Janelas de tempo de evento
Você pode querer capturar dados em janelas, como um preço de estoque alto e um preço de estoque baixo dentro de uma janela de um dia, ou uma janela de um minuto – seja qual for o intervalo que você decidir, e o streaming estruturado do Spark também suporta isso. Janelas sobrepostas também são suportadas.
Ponto de verificação para recuperação de falhas
Em caso de falha ou desligamento intencional, você pode recuperar o progresso e o estado anteriores de uma consulta anterior e continuar de onde parou. Isso é feito usando logs de checkpoint e write-ahead. Você pode configurar uma consulta com um local de ponto de verificação, e a consulta salvará todas as informações de progresso (ou seja, intervalo de deslocamentos processados em cada gatilho) e as agregações em execução no local do ponto de verificação. Esse local de ponto de verificação deve ser um caminho em um sistema de arquivos compatível com HDFS e pode ser definido como uma opção no DataStreamWriter ao iniciar uma consulta.