Introdução à Base de Dados do Azure para PostgreSQL
O Banco de Dados do Azure para PostgreSQL está disponível em versões multisservidor.
Como desenvolvedor de banco de dados com muitos anos de experiência em executar e gerenciar instalações locais do PostgreSQL, você deseja explorar como o Banco de Dados do Azure para PostgreSQL dá suporte e dimensiona seus recursos.
Nesta unidade, você explorará os preços, o suporte à versão, a replicação e as opções de dimensionamento do Banco de Dados do Azure para PostgreSQL.
Base de Dados do Azure para PostgreSQL
O serviço Banco de Dados do Azure para PostgreSQL é uma implementação da versão da comunidade do PostgreSQL. O serviço fornece os recursos comuns usados por sistemas PostgreSQL típicos, incluindo suporte geoespacial e pesquisa de texto completo.
A Microsoft adaptou o PostgreSQL para a plataforma Azure e está estreitamente integrado com muitos serviços do Azure. O serviço Banco de Dados do Azure para PostgreSQL é totalmente gerenciado pela Microsoft. A Microsoft lida com atualizações e patches para o software e fornece um SLA de 99,99% de disponibilidade. Isso significa que você pode apenas se concentrar nos bancos de dados e aplicativos em execução, usando o serviço.
Você pode implantar vários bancos de dados em cada instância desse serviço.
Escalões de preço
Ao criar uma instância do serviço Banco de Dados do Azure para PostgreSQL, você especifica os recursos de computação e armazenamento que deseja alocar selecionando uma camada de preço. Um nível de preço combina o número de núcleos de processador virtual, a quantidade de armazenamento disponível e várias opções de backup. Quanto mais recursos alocar, maior será o custo.
O serviço Banco de Dados do Azure para PostgreSQL usa o armazenamento para armazenar seus arquivos de banco de dados, arquivos temporários, logs de transações e os logs do servidor. Opcionalmente, você pode especificar que deseja que o armazenamento disponível seja aumentado quando você se aproximar da capacidade atual. Se você não selecionar essa opção, os servidores que ficarem sem armazenamento continuarão em execução, mas funcionarão como somente leitura.
O portal do Azure agrupa as camadas de preços em três grandes intervalos:
- Basic, que é adequado para sistemas pequenos e ambientes de desenvolvimento, mas tem desempenho de E/S variável.
- Uso geral, que fornece desempenho previsível, até 6000 IOPS, dependendo do número de núcleos do processador e do espaço de armazenamento disponível.
- Memória otimizada, que usa até 32 núcleos de processador virtual otimizados para memória e também fornece desempenho previsível de até 6000 IOPS.
A Microsoft também tem uma opção de armazenamento grande na visualização, que pode provisionar até 16 TB de armazenamento e suportar até 20.000 IOPS.
Você pode ajustar o número de núcleos de processador e armazenamento necessários. Você pode aumentar e diminuir a escala dos recursos de processamento — não é possível reduzir o armazenamento, apenas aumentar — e alternar entre os níveis de preços de uso geral e memória otimizada, conforme necessário, depois de criar seus bancos de dados. Você só paga pelo que precisa.

Nota
Se você alterar o número de núcleos de processador, o Azure criará um novo servidor com essa alocação de computação. Quando o servidor está em execução, as conexões de cliente são alternadas para o novo servidor. Este interruptor pode demorar até um minuto. Durante esse intervalo, nenhuma nova conexão pode ser feita, e quaisquer transações a bordo serão revertidas.
Se você alterar apenas o tamanho de armazenamento das opções de backup, não haverá interrupção no serviço.
A camada de preços e os recursos de processamento alocados determinam o número máximo de conexões simultâneas que o serviço suportará. Por exemplo, se você selecionar a camada de preço de uso geral e alocar 64 núcleos virtuais, o serviço suportará 1900 conexões simultâneas. A camada básica, com dois núcleos virtuais, lida com até 100 conexões simultâneas. O próprio Azure requer cinco dessas conexões para monitorar o servidor. Se você exceder o número de conexões disponíveis, os clientes receberão o erro FATAL: desculpe, muitos clientes já.
Os preços podem mudar. Visite a página de preços do Banco de Dados do Azure para PostgreSQL para obter as informações mais recentes.
Parâmetros do servidor
Em uma instalação local do PostgreSQL, você define parâmetros de configuração do servidor no arquivo postgresql.conf . Use o Banco de Dados do Azure para PostgreSQL para modificar parâmetros de configuração por meio da página Parâmetros do servidor. Nem todos os parâmetros para uma instalação local do PostgreSQL são relevantes para o Banco de Dados do Azure para PostgreSQL, portanto, a página Parâmetros do Servidor lista apenas os parâmetros apropriados para o Azure.

As alterações aos parâmetros marcados como Dinâmico entram em vigor imediatamente. Os parâmetros estáticos exigem uma reinicialização do servidor. Reinicie o servidor usando o botão Reiniciar na página Visão geral no portal:

Elevada disponibilidade
A Base de Dados do Azure para PostgreSQL é um serviço altamente disponível. Contém mecanismos incorporados de deteção de falha e ativação pós-falha. Se um nó de processamento parar devido a um problema de hardware ou software, um novo nó será trocado para substituí-lo. Todas as conexões que atualmente usam esse nó serão descartadas, mas abertas automaticamente no novo nó. Todas as transações que estão sendo executadas pelo nó com falha serão revertidas. Por esse motivo, você deve sempre garantir que os clientes estejam configurados para detetar e repetir operações com falha.
Versões suportadas do PostgreSQL
O serviço Banco de Dados do Azure para PostgreSQL atualmente dá suporte ao PostgreSQL versão 11, de volta à versão 9.5. Você especifica qual versão do PostgreSQL usar ao criar uma instância do serviço. A Microsoft pretende atualizar o serviço à medida que novas versões do PostgreSQL se tornam disponíveis, e manterá a compatibilidade com as duas versões principais anteriores.
O Azure gerencia automaticamente as atualizações para seus bancos de dados entre versões secundárias do PostgreSQL, mas não versões principais. Por exemplo, se você tiver um banco de dados que usa o PostgreSQL versão 10, o Azure poderá atualizar automaticamente o banco de dados para a versão 10.1. Se quiser mudar para a versão 11, você deve exportar seus dados dos bancos de dados na instância de serviço atual, criar uma nova instância do Banco de Dados do Azure para serviço PostgreSQL e importar seus dados para essa nova instância.
Coordenador e nós de trabalho
Os dados são fragmentados e distribuídos entre nós de trabalho. O mecanismo de consulta no coordenador pode paralelizar consultas complexas, direcionando o processamento para os nós de trabalho apropriados. Os nós de trabalho são selecionados de acordo com os fragmentos que armazenam os dados que estão sendo processados. Em seguida, o coordenador acumula os resultados dos nós de trabalho antes de enviá-los de volta ao cliente. Consultas mais diretas podem ser executadas usando apenas um único nó de trabalho. Os clientes também se conectam ao coordenador e nunca se comunicam diretamente com um nó de trabalho.
Você pode dimensionar o número de nós de trabalho para cima e para baixo em seu serviço, conforme necessário.
Distribuição de dados
Você distribui dados entre nós de trabalho criando tabelas distribuídas . Uma tabela distribuída é dividida em fragmentos e cada fragmento é alocado para armazenamento em um nó de trabalho. Você indica como dividir os dados definindo uma coluna como a coluna de distribuição . Os dados são fragmentados com base nos valores dos dados nesta coluna. Ao criar uma tabela distribuída, é importante selecionar a coluna de distribuição com cuidado; Você deve usar uma coluna com um grande número de valores distintos que normalmente seriam usados para agrupar linhas relacionadas. Por exemplo, em uma tabela para um sistema de comércio eletrônico que armazena informações sobre os pedidos dos clientes, o ID do cliente pode ser uma coluna de distribuição razoável. Todos os pedidos para um determinado cliente serão mantidos no mesmo fragmento, mas os pedidos para todos os clientes serão distribuídos em estilhaços.
Você também pode criar tabelas de referência . Essas tabelas contêm dados de pesquisa, como nomes de cidades ou códigos de status. Uma tabela de referência é replicada em sua totalidade para cada nó de trabalho. Os dados de uma tabela de referência devem ser relativamente estáticos; Cada alteração requer a atualização de cada cópia da tabela.
Finalmente, você pode criar tabelas locais . Uma tabela local não é fragmentada, mas é armazenada no nó coordenador. Use tabelas locais para manter tabelas pequenas com dados que provavelmente não serão exigidos por junções. Os exemplos incluem os nomes dos usuários e seus detalhes de login.
Replicar dados no Banco de Dados do Azure para PostgreSQL
As réplicas somente leitura são úteis para lidar com cargas de trabalho com uso intensivo de leitura. As conexões de cliente podem ser distribuídas entre réplicas, aliviando a carga em uma única instância do serviço. Se seus clientes estiverem localizados em diferentes regiões do mundo, você usará a replicação entre regiões para posicionar dados próximos a cada conjunto de clientes e reduzir a latência.
Você também pode usar réplicas como parte de um plano de contingência para recuperação de desastres. Se o servidor mestre ficar indisponível, você ainda poderá se conectar a uma réplica.
Nota
Se o mestre for perdido ou excluído, todas as réplicas somente leitura se tornarão servidores de leitura-gravação. No entanto, esses servidores serão independentes uns dos outros, portanto, quaisquer alterações feitas nos dados em um servidor não serão copiadas para os servidores restantes.
Estabelecendo uma réplica
Uma réplica somente leitura contém uma cópia dos bancos de dados mantidos no servidor original — conhecido como mestre. Use o portal do Azure ou a CLI para criar uma réplica de um mestre.

Quando você cria uma réplica somente leitura, o Azure cria uma nova instância do serviço Banco de Dados do Azure para PostgreSQL e copia os bancos de dados do servidor mestre para o novo servidor. A réplica é executada no modo somente leitura. Qualquer tentativa de modificar dados falhará.
Atraso da réplica
A replicação não é síncrona e quaisquer alterações feitas nos dados no servidor mestre podem levar algum tempo para aparecer nas réplicas. Os aplicativos cliente que se conectam a réplicas devem ser capazes de lidar com esse nível de consistência eventual. O Azure Monitor permite controlar o atraso de tempo na replicação usando as métricas Atraso máximo entre réplicas e Atraso de réplica .
Gestão e monitorização
Você pode usar ferramentas familiares, como pgAdmin, para se conectar ao Banco de Dados do Azure para PostgreSQL para gerenciar e monitorar seus bancos de dados. No entanto, algumas funcionalidades voltadas para o servidor, como a realização da cópia de segurança e o restauro do servidor, não estão disponíveis porque o servidor é gerido e mantido pela Microsoft.

Ferramentas do Azure para monitorar o Banco de Dados do Azure para PostgreSQL
O Azure fornece um conjunto extensivo de serviços que você usa para monitorar o desempenho do servidor e do banco de dados e solucionar problemas. Esses serviços permitem que você veja como o PostgreSQL está utilizando os recursos do Azure que você alocou. Você usa essas informações para avaliar se precisa dimensionar seu sistema, modificar a estrutura de tabelas e índices em seus bancos de dados e visualizar estatísticas de tempo de execução e outros eventos. Os serviços disponíveis incluem:
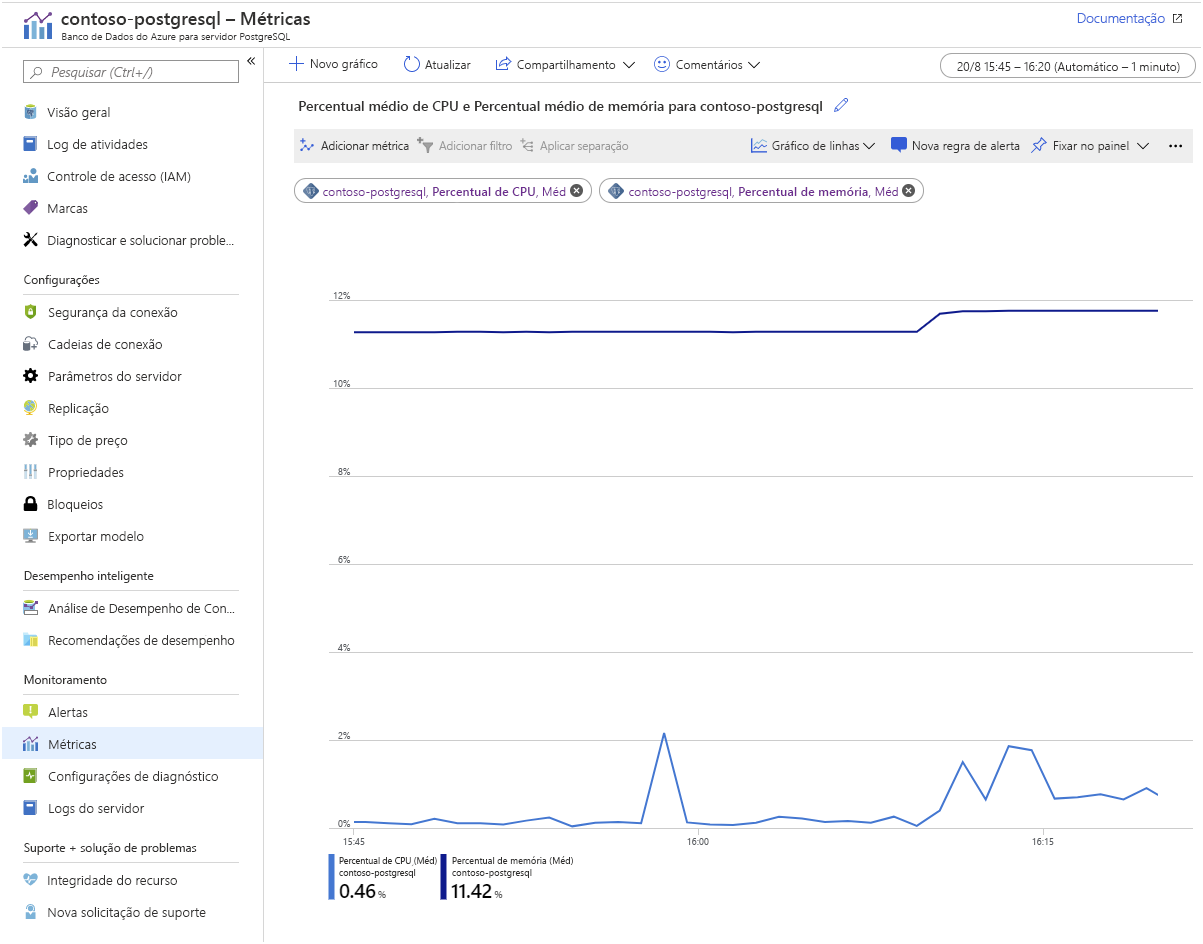
Azure Monitor. O Banco de Dados do Azure para PostgreSQL fornece métricas que permitem controlar itens como utilização de CPU e armazenamento, taxas de E/S, ocupação de memória, número de conexões ativas e atraso de replicação:
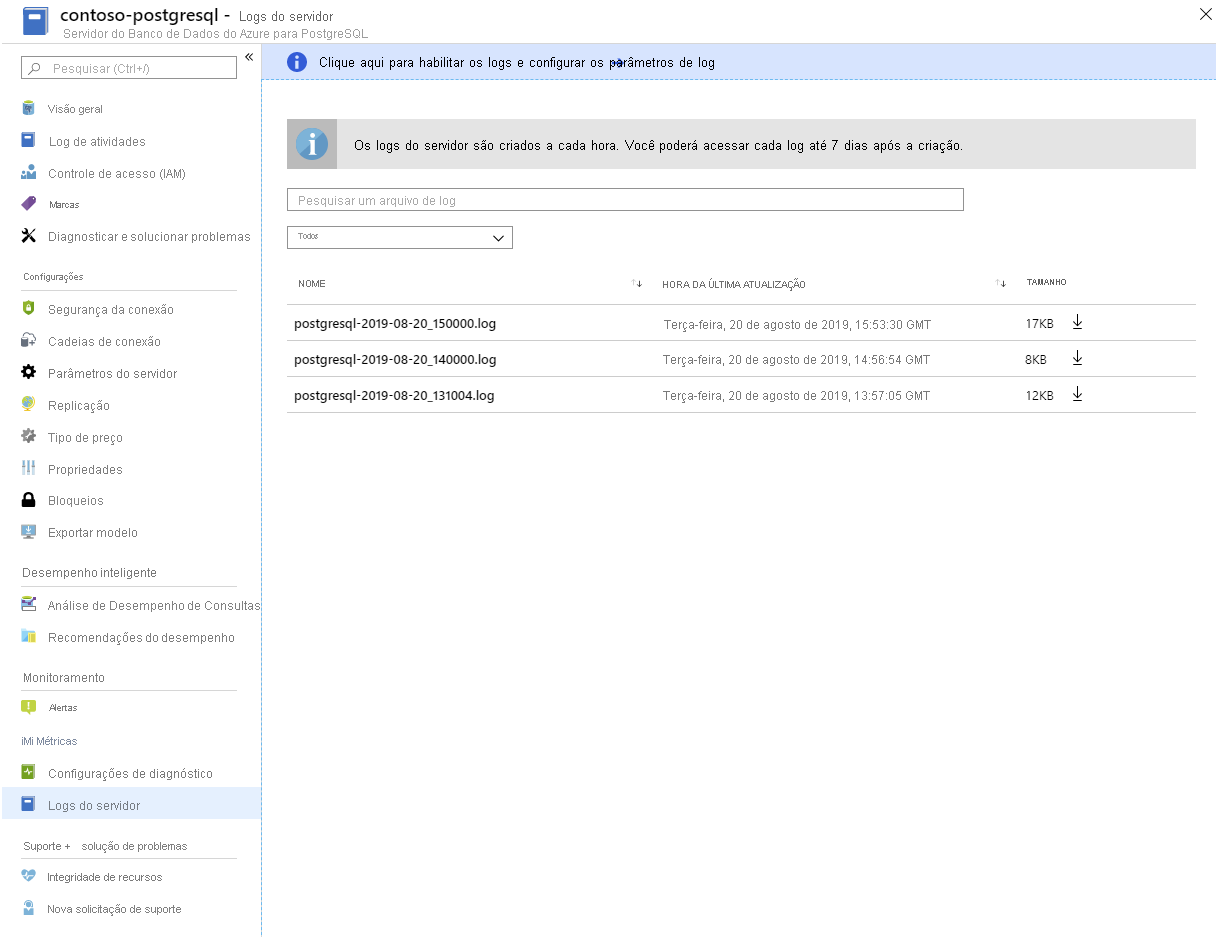
Logs do servidor. O Azure disponibiliza os logs para cada servidor PostgreSQL. Você os baixa do portal do Azure:
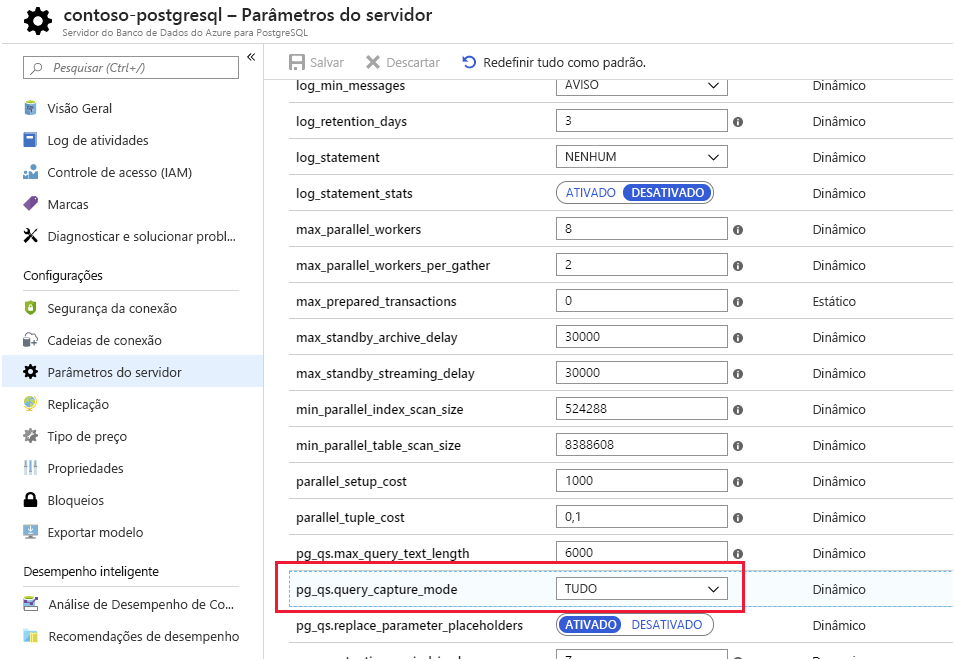
Repositório de Consultas e Insights de Desempenho de Consulta. O Banco de Dados do Azure para PostgreSQL armazena informações sobre as consultas executadas em bancos de dados no servidor e as salva em um banco de dados chamado azure_sys, no esquema query_store. Você consulta a exibição query_store.qs_view para ver essas informações. Por padrão, o Banco de Dados do Azure para PostgreSQL não captura nenhuma informação de consulta, pois impõe uma pequena sobrecarga, mas você pode habilitar o rastreamento definindo a propriedade de servidor pg_qs.query_capture_mode como ALL ou TOP.
Você também configura o Repositório de Consultas para capturar informações sobre consultas que passam tempo esperando. Uma consulta pode ter que esperar enquanto outra consulta libera um bloqueio em uma tabela, ou porque a consulta está executando muitas E/S, ou porque a memória está ficando curta. Essas informações são exibidas no modo de exibição query_store.runtime_stats_view .
Se preferir visualizar essas estatísticas em vez de executar instruções SQL, use o Query Performance Insight no portal do Azure:

Recomendações de Desempenho. O utilitário Recomendações de Desempenho, também disponível no portal do Azure, examina as consultas que seus aplicativos estão executando. Ele também examina as estruturas no banco de dados e recomenda como organizar seus dados — e se você deve considerar adicionar ou remover índices.




Conectividade do cliente
O Banco de Dados do Azure para PostgreSQL é executado atrás de um firewall. Para acessar seu serviço e banco de dados, você deve adicionar uma regra de firewall para os intervalos de endereços IP a partir dos quais seus clientes se conectam. Se você precisar acessar o serviço de dentro do Azure, como um aplicativo em execução usando os Serviços de Aplicativo do Azure, também deverá habilitar o acesso aos serviços do Azure.
Configurar a firewall
A maneira mais simples de configurar o firewall é usar as configurações de Segurança de Conexão para seu serviço no portal do Azure. Adicione uma regra para cada intervalo de endereços IP do cliente. Você também usa esta página para impor conexões SSL ao seu serviço.

Clique em Adicionar IP do cliente na barra de ferramentas para adicionar o endereço IP do seu computador desktop.
Se você configurou réplicas somente leitura, deverá adicionar uma regra de firewall a cada uma delas para torná-las acessíveis aos clientes.
Bibliotecas de conexão do cliente
Se você estiver escrevendo seus próprios aplicativos cliente, deverá usar o driver de banco de dados apropriado para se conectar a um banco de dados PostgreSQL. Muitas dessas bibliotecas dependem da linguagem de programação. São mantidos por terceiros independentes. O Banco de Dados do Azure para PostgreSQL dá suporte a bibliotecas de cliente para Python, PHP, Node.js, Java, Ruby, Go, C# (.NET), ODBC, C e C++.
Lógica de repetição do cliente
Como mencionado anteriormente, alguns eventos, como failover durante a recuperação de alta disponibilidade e escalonamento dos recursos da CPU, podem causar uma breve perda de conectividade. Quaisquer transações em andamento serão revertidas. O Banco de Dados do Azure para PostgreSQL redireciona automaticamente um cliente conectado para um nó de trabalho, mas todas as operações executadas pelo cliente naquele momento retornarão um erro. Deve tratar esta ocorrência como uma exceção transitória. O código do aplicativo deve estar preparado para capturar essas exceções e repeti-las.
Recursos do PostgreSQL com suporte no Banco de Dados do Azure para PostgreSQL
O Banco de Dados do Azure para PostgreSQL dá suporte à maioria dos recursos comumente usados por bancos de dados PostgreSQL, mas há algumas exceções. Se você precisar de um recurso sem suporte, precisará retrabalhar o banco de dados e o código do aplicativo para remover essa dependência ou considerar a execução do PostgreSQL em uma máquina virtual. Neste último caso, você terá que assumir a responsabilidade pelo gerenciamento e manutenção do servidor.
Extensões suportadas na Base de Dados do Azure para PostgreSQL
Muitas funcionalidades do PostgreSQL são encapsuladas em extensões. As extensões são pacotes de objetos SQL e código armazenados no servidor — eles podem ser carregados em um banco de dados usando o CREATE EXTENSION comando. O Banco de Dados do Azure para PostgreSQL atualmente fornece muitas extensões comumente usadas para:
- Tipos de dados
- Funções
- Pesquisa de texto completo
- Índices (bloom, btree_gist e btree_gin)
- A linguagem plpgsql
- PostGIS
- Muitas funções administrativas
Você usa os pacotes dblink e postgres_fdw para conectar um servidor PostgreSQL a outro — isso permite que o código em um servidor acesse dados mantidos em outro. No Banco de Dados do Azure para PostgreSQL, você só pode se conectar entre servidores criados usando o Banco de Dados do Azure para PostgreSQL. Não é possível criar conexões de saída para servidores PostgreSQL hospedados em outro lugar, como no local ou em uma máquina virtual.
Nota
A lista de extensões suportadas está continuamente em revisão e pode ser alterada. Você gerará uma lista das extensões suportadas com a consulta a seguir. Observe que você não pode criar suas próprias extensões personalizadas e carregá-las no Banco de Dados do Azure para PostgreSQL:
SELECT * FROM pg_available_extensions;
O Banco de Dados do Azure para PostgreSQL inclui o banco de dados TimescaleDB como uma extensão opcional. Esta base de dados contém funções analíticas orientadas para o tempo e outras funcionalidades que suportam cargas de trabalho de séries cronológicas. Para usar esse banco de dados, selecione a opção TIMESCALEDB no parâmetro shared_preload_libraries server e reinicie o servidor.
Suporte a idiomas para procedimentos armazenados e gatilhos
O suporte para idiomas diferentes do plpgsql normalmente requer que você compile seu procedimento armazenado ou código de gatilho separadamente e carregue a biblioteca compilada para o servidor. Principalmente por motivos de segurança, você não pode fazer isso com o Banco de Dados do Azure para PostgreSQL. Se você tiver código escrito em outros idiomas, você terá que portá-lo para plpgsql.