Lidar com semelhanças entre ambientes usando modelos de pipeline
Quando você implanta suas alterações em vários ambientes, as etapas envolvidas na implantação em cada ambiente são semelhantes ou idênticas. Nesta unidade, você aprenderá a usar modelos de pipeline para evitar a repetição e permitir a reutilização do código do pipeline.
Implantação em vários ambientes
Depois de conversar com seus colegas da equipe do site, você decide sobre o seguinte pipeline para o site da sua empresa de brinquedos:
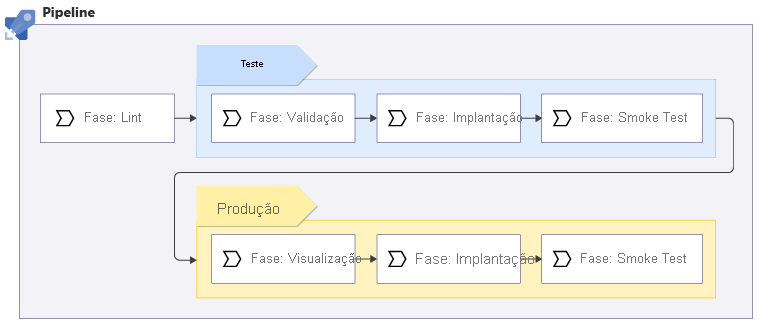
O pipeline executa o linter do Bicep para verificar se o código do Bicep é válido e segue as práticas recomendadas.
O Linting acontece no código Bicep sem precisar se conectar ao Azure, portanto, não importa em quantos ambientes você está implantando. Funciona apenas uma vez.
O pipeline é implantado no ambiente de teste. Esta etapa requer:
- Executando a validação de comprovação do Azure Resource Manager.
- Implantando o código Bicep.
- Executando alguns testes em seu ambiente de teste.
Se qualquer parte do pipeline falhar, todo o pipeline será interrompido para que você possa investigar e resolver o problema. Mas se tudo for bem-sucedido, seu pipeline continuará a ser implantado em seu ambiente de produção:
- O pipeline executa um estágio de visualização, que executa a operação hipotética em seu ambiente de produção para listar as alterações que seriam feitas em seus recursos de produção do Azure. O estágio de visualização também valida sua implantação, portanto, você não precisa executar um estágio de validação separado para seu ambiente de produção.
- O pipeline pausa para validação manual.
- Se a aprovação for recebida, o pipeline executará os testes de implantação e fumaça em seu ambiente de produção.
Alguns desses estágios são repetidos entre seus ambientes de teste e produção, e alguns são executados apenas para ambientes específicos:
| Fase | Ambientes |
|---|---|
| Linho | Nem - o forro não funciona contra um ambiente |
| Validar | Apenas teste |
| Pré-visualizar | Apenas produção |
| Implementar | Ambos os ambientes |
| Teste de fumaça | Ambos os ambientes |
Quando precisar repetir etapas em seu pipeline, você pode tentar copiar e colar suas definições de etapa. No entanto, é melhor evitar essa prática. É fácil cometer erros sutis acidentalmente ou que as coisas saiam de sincronia quando você duplica o código do seu pipeline. E no futuro, quando você precisar fazer uma alteração nas etapas, você tem que se lembrar de aplicar a mudança em vários lugares.
Modelos de pipeline
Os modelos de pipeline permitem criar seções reutilizáveis de definições de pipeline. Os modelos podem definir etapas, trabalhos ou até mesmo estágios inteiros. Você pode usar modelos para reutilizar partes de um pipeline várias vezes dentro de um único pipeline ou até mesmo em vários pipelines. Você também pode criar um modelo para um conjunto de variáveis que deseja reutilizar em vários pipelines.
Um modelo é simplesmente um arquivo YAML que contém seu conteúdo reutilizável. Um modelo simples para uma definição de etapa pode ter esta aparência e ser salvo em um arquivo chamado script.yml:
steps:
- script: |
echo Hello world!
Você pode usar um modelo em seu pipeline usando a template palavra-chave no local onde normalmente definiria a etapa individual:
jobs:
- job: Job1
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
Modelos aninhados
Você também pode aninhar modelos em outros modelos. Suponha que o arquivo anterior foi nomeado jobs.yml e você cria um arquivo chamado azure-pipelines.yml que reutiliza o modelo de trabalho em vários estágios de pipeline:
trigger:
branches:
include:
- main
pool:
vmImage: ubuntu-latest
stages:
- stage: Stage1
jobs:
- template: jobs.yml
- stage: Stage2
jobs:
- template: jobs.yml
Ao aninhar modelos ou reutilizá-los várias vezes em um único pipeline, você precisa ter cuidado para não usar acidentalmente o mesmo nome para vários recursos de pipeline. Por exemplo, cada trabalho dentro de um estágio precisa de seu próprio identificador. Portanto, se você definir o identificador de trabalho em um modelo, não poderá reutilizá-lo várias vezes no mesmo estágio.
Quando você trabalha com conjuntos complexos de pipelines de implantação, pode ser útil criar um repositório Git dedicado para seus modelos de pipeline compartilhados. Em seguida, você pode reutilizar o mesmo repositório em vários pipelines, mesmo que sejam para projetos diferentes. Fornecemos um link para mais informações no resumo.
Parâmetros do modelo de pipeline
Os parâmetros de modelo de pipeline tornam seus arquivos de modelo mais fáceis de reutilizar, porque você pode permitir pequenas diferenças em seus modelos sempre que usá-los.
Ao criar um modelo de pipeline, você pode indicar seus parâmetros na parte superior do arquivo:
parameters:
- name: environmentType
type: string
default: 'Test'
- name: serviceConnectionName
type: string
Você pode definir quantos parâmetros precisar. Mas, assim como os parâmetros do Bíceps, tente não usar demais os parâmetros do modelo de pipeline. Você deve facilitar a reutilização do modelo por outra pessoa sem precisar especificar muitas configurações.
Cada parâmetro de modelo de pipeline tem três propriedades:
- O nome do parâmetro, que você usa para se referir ao parâmetro em seus arquivos de modelo.
- O tipo do parâmetro. Os parâmetros suportam vários tipos diferentes de dados, incluindo string, número e booleano. Você também pode definir modelos mais complexos que aceitam objetos estruturados.
- O valor padrão do parâmetro, que é opcional. Se você não especificar um valor padrão, um valor deverá ser fornecido quando o modelo de pipeline for usado.
No exemplo, o pipeline define um parâmetro string chamado environmentType, que tem um valor padrão de Test, e um parâmetro obrigatório chamado serviceConnectionName.
No modelo de pipeline, você usa uma sintaxe especial para se referir ao valor do parâmetro. Use a ${{parameters.YOUR_PARAMETER_NAME}} macro, como neste exemplo:
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
Você passa o valor dos parâmetros para um modelo de pipeline usando a parameters palavra-chave, como neste exemplo:
steps:
- template: script.yml
parameters:
environmentType: Test
- template: script.yml
parameters:
environmentType: Production
Você também pode usar parâmetros ao atribuir identificadores aos seus trabalhos e estágios em modelos de pipeline. Essa técnica ajuda quando você precisa reutilizar o mesmo modelo várias vezes em seu pipeline, assim:
parameters:
- name: environmentType
type: string
default: 'Test'
jobs:
- job: Job1-${{parameters.environmentType}}
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2-${{parameters.environmentType}}
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
Condições
Você pode usar condições de pipeline para especificar se uma etapa, um trabalho ou até mesmo um estágio deve ser executado, dependendo de uma regra especificada. Você pode combinar parâmetros de modelo e condições de pipeline para personalizar seu processo de implantação para muitas situações diferentes.
Por exemplo, imagine que você defina um modelo de pipeline que execute etapas de script. Você planeja reutilizar o modelo para cada um dos seus ambientes. Ao implantar seu ambiente de produção, você deseja executar outra etapa. Veja como você pode conseguir isso usando a if macro e o eq operador (igual):
parameters:
- name: environmentType
type: string
default: 'Test'
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
- ${{ if eq(parameters.environmentType, 'Production') }}:
- script: |
echo This step only runs for production deployments.
A condição aqui se traduz em: se o valor do parâmetro environmentType for igual a Production, execute as etapas a seguir.
Gorjeta
Preste atenção ao recuo do arquivo YAML ao usar condições como no exemplo. As etapas às quais a condição se aplica precisam ser recuadas por um nível extra.
Você também pode especificar a condition propriedade em um estágio, trabalho ou etapa. Veja um exemplo que mostra como você pode usar o ne operador (não igual) para especificar uma condição, como se o valor do parâmetro environmentType não for igual a Production, e execute as seguintes etapas:
- script: |
echo This step only runs for non-production deployments.
condition: ne('${{ parameters.environmentType }}', 'Production')
Embora as condições sejam uma maneira de adicionar flexibilidade ao seu pipeline, tente não usar muitas delas. Eles complicam seu pipeline e dificultam a compreensão de seu fluxo. Se houver muitas condições em seu modelo de pipeline, o modelo pode não ser a melhor solução para o fluxo de trabalho que você planeja executar, e talvez seja necessário reprojetar seu pipeline.
Além disso, considere usar comentários YAML para explicar as condições que você usa e quaisquer outros aspetos do seu pipeline que possam precisar de mais explicações. Os comentários ajudam a tornar seu pipeline fácil de entender e trabalhar no futuro. Há exemplos de comentários YAML nos exercícios ao longo deste módulo.