Introdução
Hoje em dia, muitas organizações trabalham com big data . O enorme volume e variedade de dados e a velocidade de geração de dados exigem ter sistemas que o ajudem a gerenciá-los e controlá-los. No passado, as organizações usavam sistemas de gerenciamento de banco de dados relacional para controlar os dados. No entanto, as organizações agora querem a funcionalidade de software de código aberto combinada com os benefícios das plataformas hospedadas. O Azure HDInsight é o exemplo perfeito desta parceria. O HDInsight permite processar big data em muitos cenários usando dados históricos ou em tempo real.
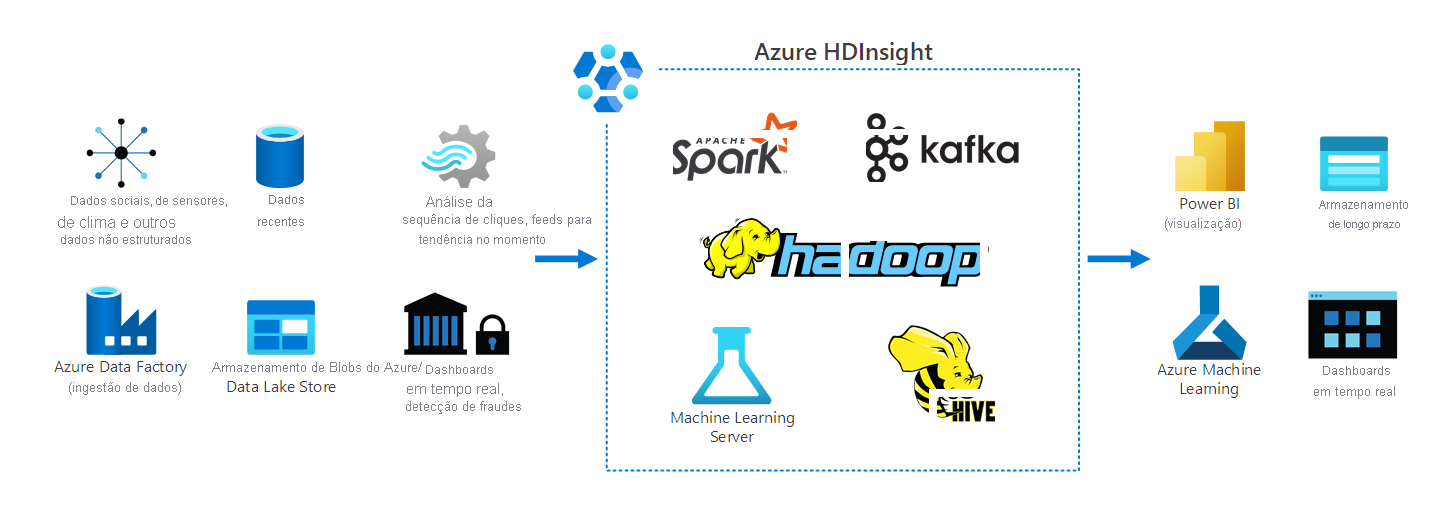
O gráfico a seguir mostra uma visão geral de como você pode usar o HDInsight. Ele descreve várias fontes de dados, incluindo sensores de Internet das Coisas (IoT), bancos de dados e vários armazenamentos de dados do Azure. O HDInsight processa dados desses locais. Em seguida, disponibiliza-o em armazenamento de longo prazo para aplicações em tempo real e análise adicional.
Cenário de exemplo
Vamos imaginar que você trabalhe para uma organização que cria cargas de trabalho que ingerem dados para relatórios históricos e análises avançadas. Talvez você também tenha dados de streaming que exigem análise. Nessa situação, convém considerar o uso do HDInsight. Ele permite a ingestão de todos os dados em um único local do Data Lake. Em seguida, você pode usá-lo para gerenciar as seguintes cargas de trabalho:
- Processamento em lote
- Armazenamento de dados
- Operações de ciência de dados
- Transmissão
O que vamos fazer?
Ao final deste módulo, você poderá avaliar se o HDInsight pode ajudar sua organização a processar big data. Você também poderá descrever como o HDInsight usa estruturas de código aberto populares que suportam muitos cenários de dados.
Qual é o principal objetivo?
O principal objetivo é determinar se o HDInsight é uma escolha adequada para seus requisitos de processamento de big data.