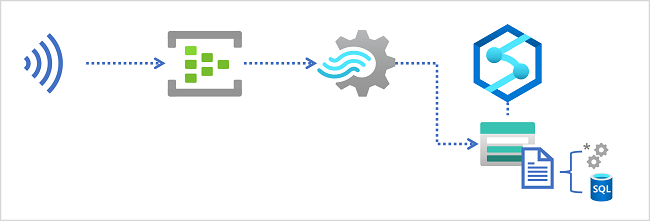
Cenários de ingestão de fluxo
O Azure Synapse Analytics fornece várias maneiras de analisar grandes volumes de dados. Duas das abordagens mais comuns para a análise de dados em larga escala são:
- Data warehouses - bancos de dados relacionais, otimizados para armazenamento distribuído e processamento de consultas . Os dados são armazenados em tabelas e consultados usando SQL.
- Data lakes - armazenamento distribuído de arquivos no qual os dados são armazenados como arquivos que podem ser processados e consultados usando vários tempos de execução, incluindo Apache Spark e SQL.
Data warehouses no Azure Synapse Analytics
O Azure Synapse Analytics fornece pools SQL dedicados que você pode usar para implementar data warehouses relacionais em escala empresarial. Os pools SQL dedicados são baseados em uma instância de processamento paralelo maciço (MPP) do mecanismo de banco de dados relacional do Microsoft SQL Server no qual os dados são armazenados e consultados em tabelas.
Para ingerir dados em tempo real em um data warehouse relacional, sua consulta do Azure Stream Analytics deve gravar seus resultados em uma saída que faça referência à tabela na qual você deseja carregar os dados.
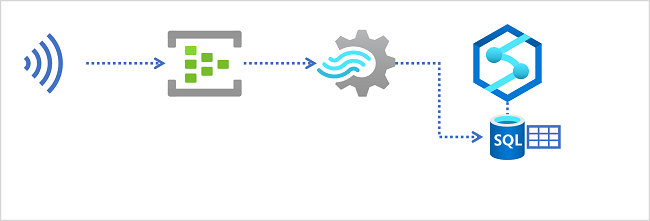
Data lakes no Azure Synapse Analytics
Um espaço de trabalho do Azure Synapse Analytics normalmente inclui pelo menos um serviço de armazenamento que é usado como um data lake. Mais comumente, o data lake é hospedado em uma conta de Armazenamento do Azure usando um contêiner configurado para dar suporte ao Azure Data Lake Storage Gen2. Os arquivos no data lake são organizados hierarquicamente em diretórios (pastas) e podem ser armazenados em vários formatos de arquivo, incluindo texto delimitado (como valores separados por vírgulas ou CSV), Parquet e JSON.
Ao ingerir dados em tempo real em um data lake, sua consulta do Azure Stream Analytics deve gravar seus resultados em uma saída que faça referência ao local no contêiner de armazenamento do Azure Data Lake Gen2 onde você deseja salvar os arquivos de dados. Analistas de dados, engenheiros e cientistas podem processar e consultar os arquivos no data lake executando código em um pool do Apache Spark ou executando consultas SQL usando um pool SQL sem servidor.