Rastreamento de incidentes
Os incidentes têm um ciclo de vida. Para responder de forma mais eficaz, você precisa ser capaz de acompanhar a evolução do incidente em si, e a evolução da sua resposta a ele, desde o início desse ciclo de vida.
Avalie o que sabe
Uma boa maneira de avaliar seu procedimento de rastreamento de incidentes usando um incidente específico é fazer a si mesmo uma série de perguntas:
- Quando teve conhecimento do problema? Se o seu objetivo é reduzir o tempo necessário para se recuperar de incidentes, você precisa começar a capturar informações a partir do momento em que toma conhecimento dos problemas.
- Como teve conhecimento do problema? O seu sistema de monitorização alertou-o sobre o incidente? Você ouviu falar sobre isso pela primeira vez de seus clientes reclamando, diretamente ou nas redes sociais?
- Se você está apenas descobrindo o problema, você é o primeiro a saber? Em caso afirmativo, quem deve notificar? Em caso negativo, quem mais tem conhecimento do problema?
- Se os outros estão cientes, o que (se alguma coisa) está sendo feito a respeito? Todo mundo está assumindo que alguém está investigando isso, ou alguém começou a tomar medidas para resolvê-lo?
- Quão ruim é? Podemos não ter qualquer noção de gravidade ou impacto, e não há lugar para descobrirmos o quão ruim o problema realmente é e quem é afetado.
Estas podem ser perguntas difíceis de responder se nada estiver a ser registado.
Padronizar onde as informações de incidentes serão rastreadas
Há muitos lugares possíveis que você pode manter e compartilhar sua lista de incidentes (ativos ou não) e todas as informações atuais sobre esses incidentes. Estes podem ser tão simples como uma área de ficheiros partilhada com documentos do Word e tão complexos como software e serviços altamente especializados de rastreio de incidentes. Entre esses dois extremos estão os sistemas de emissão de bilhetes e rastreamento de trabalho que pode utilizar para esta tarefa. O sistema que escolher é, na verdade, menos importante do que a forma como o utiliza. Não importa qual sistema você usa, todos que possam ter alguma conexão com incidentes (engenheiros, suporte ao cliente, gerenciamento, relações públicas, jurídico e assim por diante) precisam saber onde encontrar o sistema, como levantar um incidente e como acessar os dados quando apropriado. Uma maneira segura de falhar com o rastreamento de incidentes é fazer com que as pessoas que ele suportará não saibam como chegar ao sistema ("qual foi a URL do nosso sistema novamente?") quando precisarem.
Neste módulo, usaremos a funcionalidade de item de trabalho do Azure DevOps para nosso sistema de rastreamento de exemplo.
Criar uma ponte de conversação
Para responder a algumas das perguntas da seção Avaliar o que você sabe anterior e iniciar o processo de resposta a incidentes, você deve ter uma maneira de se comunicar com outras pessoas sobre o incidente. Idealmente, este será algum tipo de meio eletrônico de "colaboração em equipe" para conversação, embora as pontes telefônicas também funcionem. Teleconferências/pontes telefônicas são menos preferidas, porque é mais difícil revisar retroativamente a comunicação do incidente (daí o papel "Scribe" mencionado anteriormente).
Seja qual for o meio escolhido, você deve ter certeza de criar um canal exclusivo que seja estritamente limitado à discussão sobre esse incidente e nada mais. É importante manter discussões irrelevantes fora desse canal, porque você precisa ser capaz de pegar os dados e analisá-los posteriormente em sua revisão pós-incidente.
Neste módulo, usaremos o Microsoft Teams como nosso método de comunicação de incidentes.
Automatize o lançamento do rastreamento de incidentes
Então, vamos rever as peças que reunimos até agora. Temos um:
- Lista das pessoas de plantão (e um rodízio definido para elas).
- Função que podemos atribuir às pessoas que trabalham em um incidente.
- No local específico onde vamos declarar o incidente e rastreá-lo.
- Canal único para as pessoas que trabalham nesse incidente se comunicarem sobre ele.
Você pode e deve automatizar a criação e o gerenciamento de todas essas coisas na máxima extensão possível. Quando um problema urgente surge, você não quer ter que lembrar todas as etapas necessárias para levantar um incidente, trazer as pessoas certas e rastreá-lo. Tudo o que realmente queres fazer é ser capaz de pressionar o botão "iniciar" para que o trabalho possa começar imediatamente a resolver o problema.
Usar aplicativos lógicos para automação sem código
Uma maneira de automatizar sua resposta inicial é usando aplicativos lógicos, que podem simplificar o trabalho de agendamento, automação e orquestração de tarefas, processos de negócios e fluxos de trabalho.
O Logic Apps é um serviço de nuvem do Azure para criar soluções de integração. Ele usa conectores para criar fluxos de trabalho automatizados. Acionadores iniciam a Aplicação Lógica quando ocorre um evento específico ou quando os dados satisfazem os critérios especificados. Ações são as operações que são executadas no fluxo de trabalho da Aplicação Lógica.
Para nosso exemplo, usaremos os seguintes conectores do Aplicativo Lógico para rastreamento de incidentes:
- Azure Boards (uma parte do Azure DevOps), que pode usar para criar e acompanhar problemas/incidentes.
- Armazenamento do Azure, onde podes guardar e recuperar informações sobre quem está de plantão para que possas atribuir as pessoas adequadas para responder ao incidente. Em nosso exemplo, usaremos o Armazenamento de Tabela do Azure porque ele oferece um armazenamento de "chave-valor" muito simples que facilita o armazenamento de uma lista de engenheiros e seu status de plantão.
- Microsoft Teams, que você pode usar para criar um canal de incidentes novo e exclusivo para acompanhar as conversas de suas equipes de engenharia em tempo real enquanto elas se comunicam sobre incidentes específicos. Isso permite que você preserve as interações em relação à linha do tempo dos eventos mais tarde ao executar uma revisão pós-incidente.
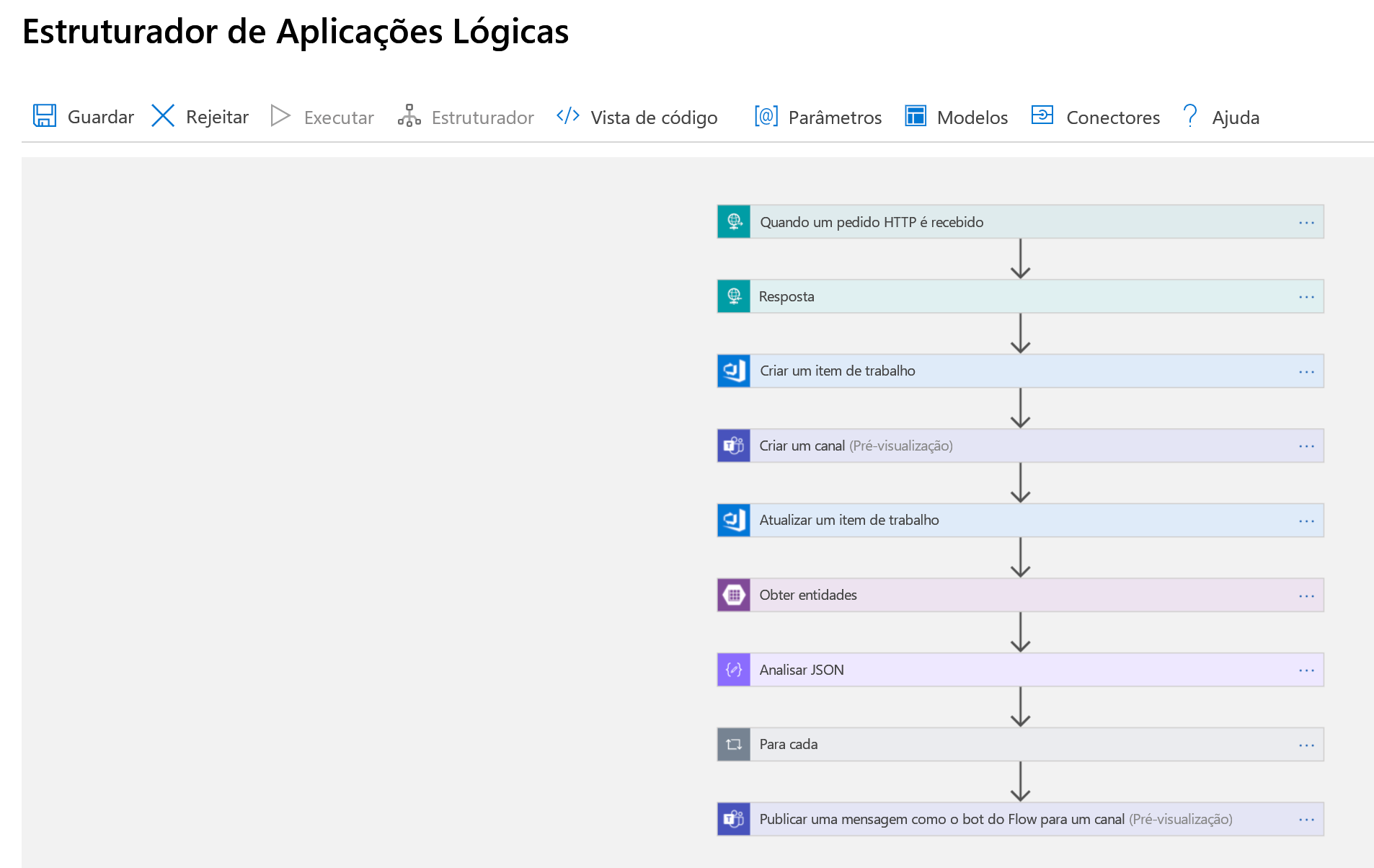
Agora vamos unir tudo isso com um aplicativo lógico. Primeiro, dê uma olhada no aplicativo completo, conforme mostrado no Logic Apps Designer, depois vamos percorrê-lo passo a passo.
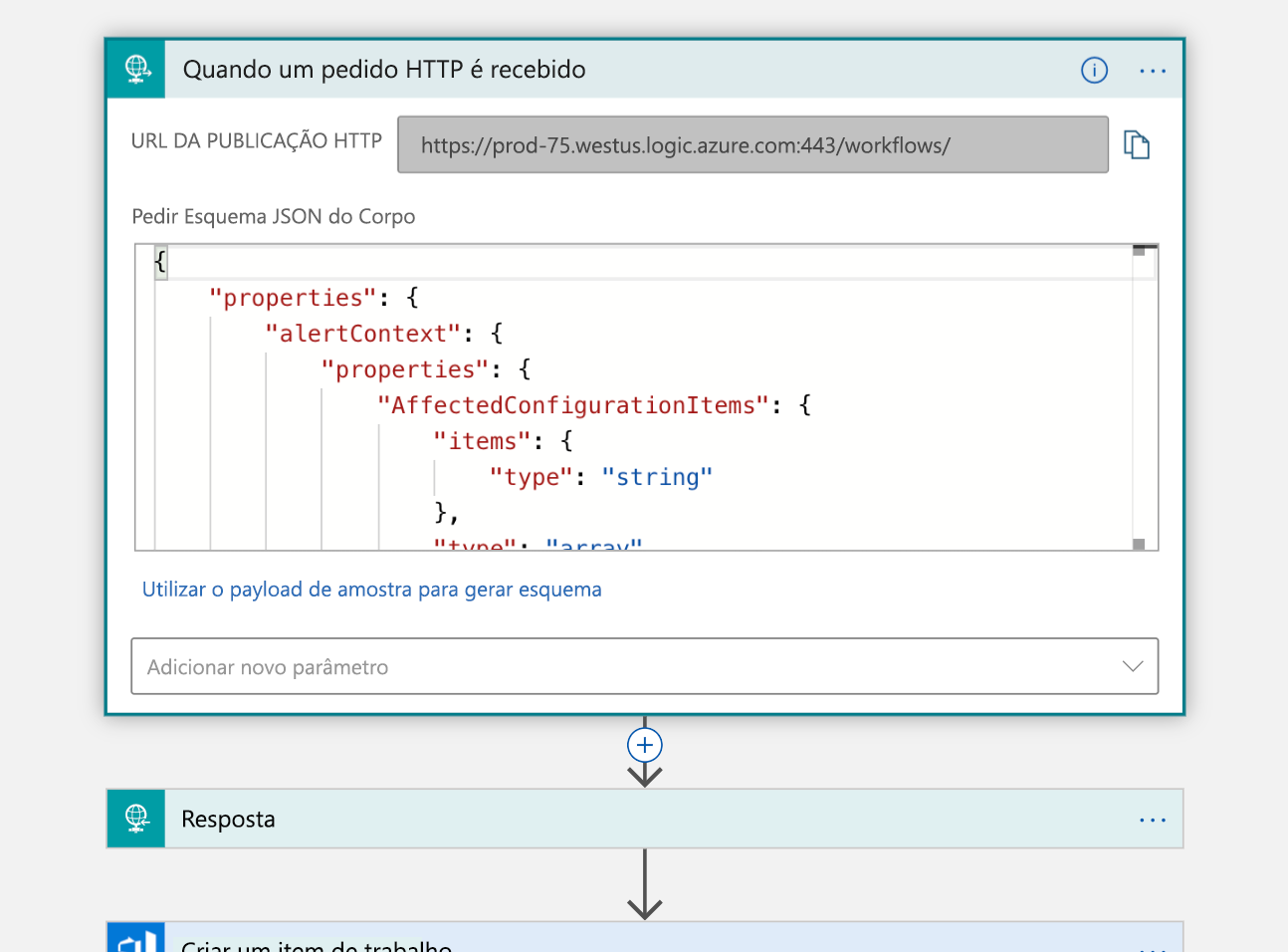
O primeiro passo é lidar com um gatilho, aquela solicitação HTTP que mencionamos. Uma solicitação HTTP POST é feita ao nosso aplicativo lógico que contém uma carga JSON com informações sobre o incidente que desejamos declarar. Analisamos essa carga útil e enviamos de volta uma confirmação que recebemos:
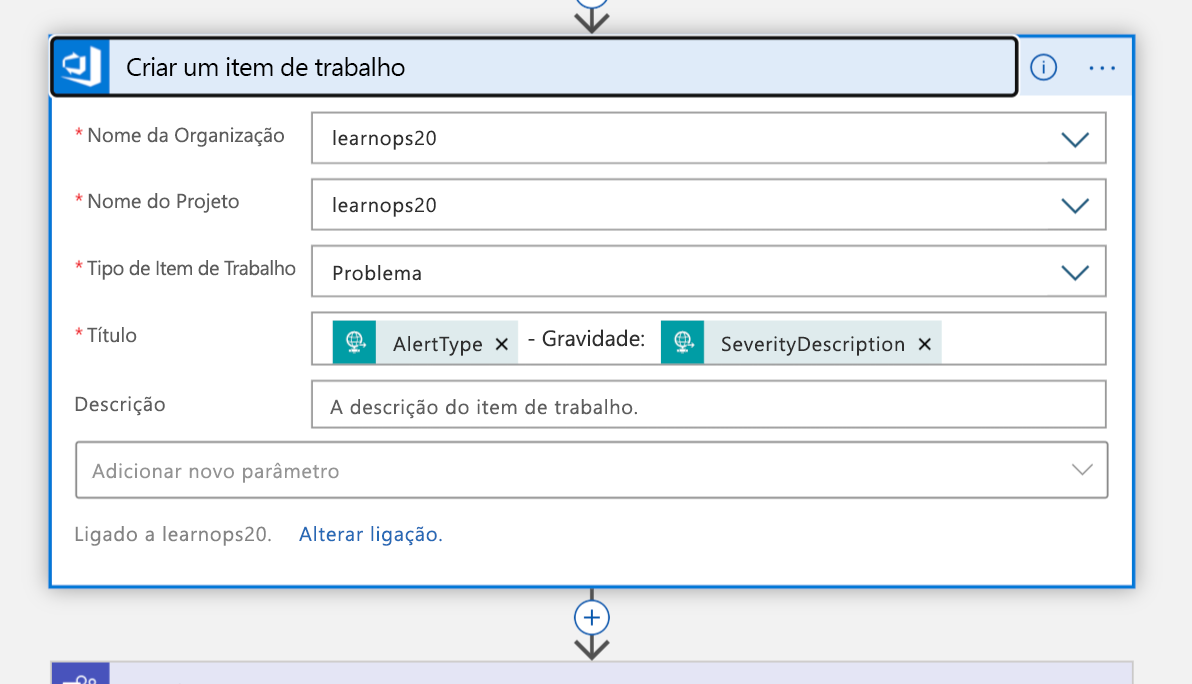
Usando essas informações, criamos um novo item de trabalho em nossa organização do Azure DevOps representando esse incidente.
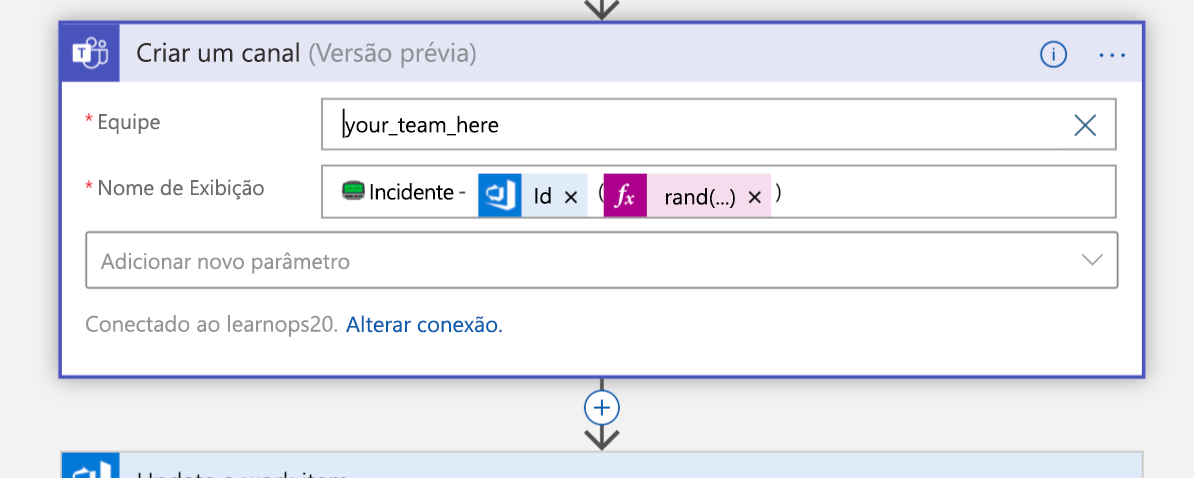
Em seguida, criará um novo canal do Teams para o incidente:
Uma vez que o canal é criado, o item de trabalho que criamos um momento atrás é atualizado com um link para o novo canal. Isso mantém todas as informações no mesmo lugar (o item de trabalho) e permite que as pessoas que olham para ela mais tarde saibam para onde ir se quiserem participar desse canal.
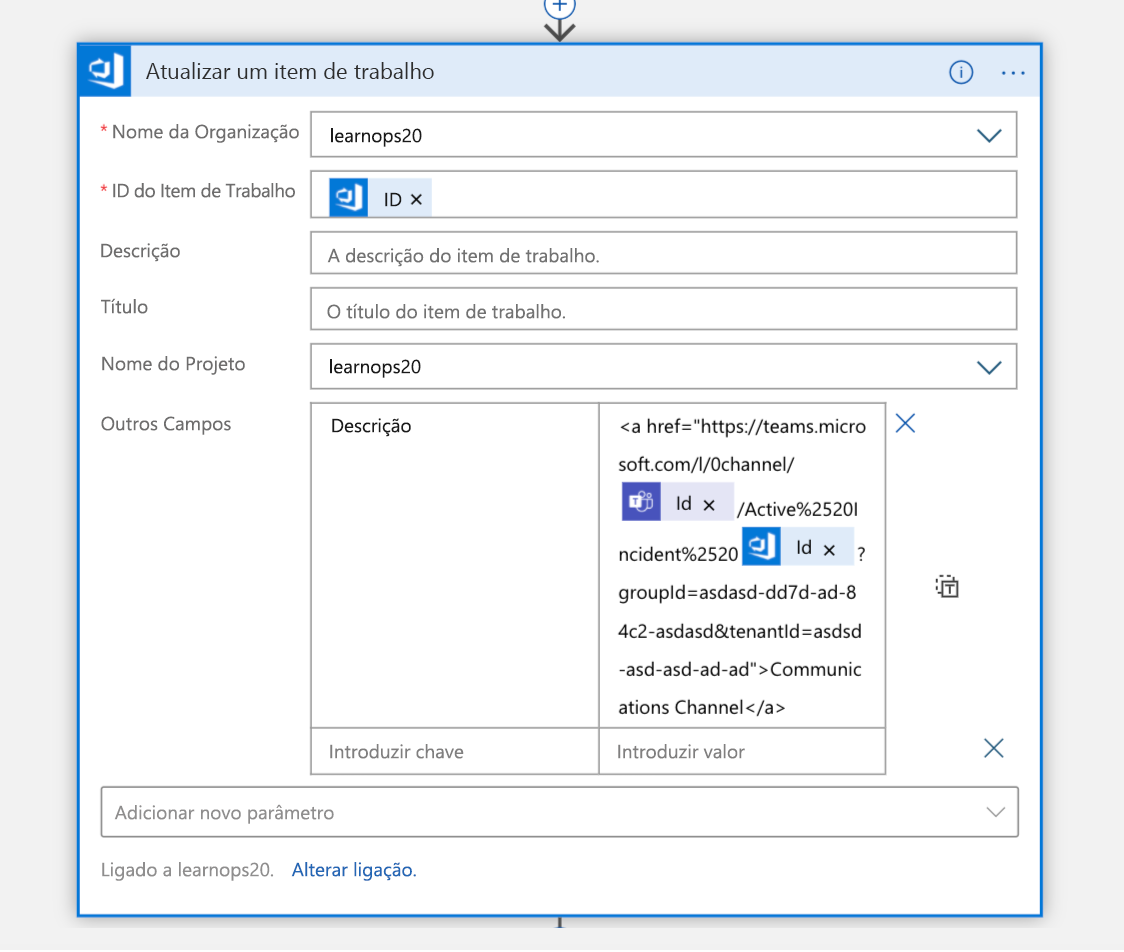
Agora, é hora de trazer a pessoa de plantão para a cena. Realizamos uma pesquisa no Armazenamento de Tabela do Azure para o endereço de email do engenheiro listado como estando de plantão. Isso retorna uma resposta JSON, que analisamos.
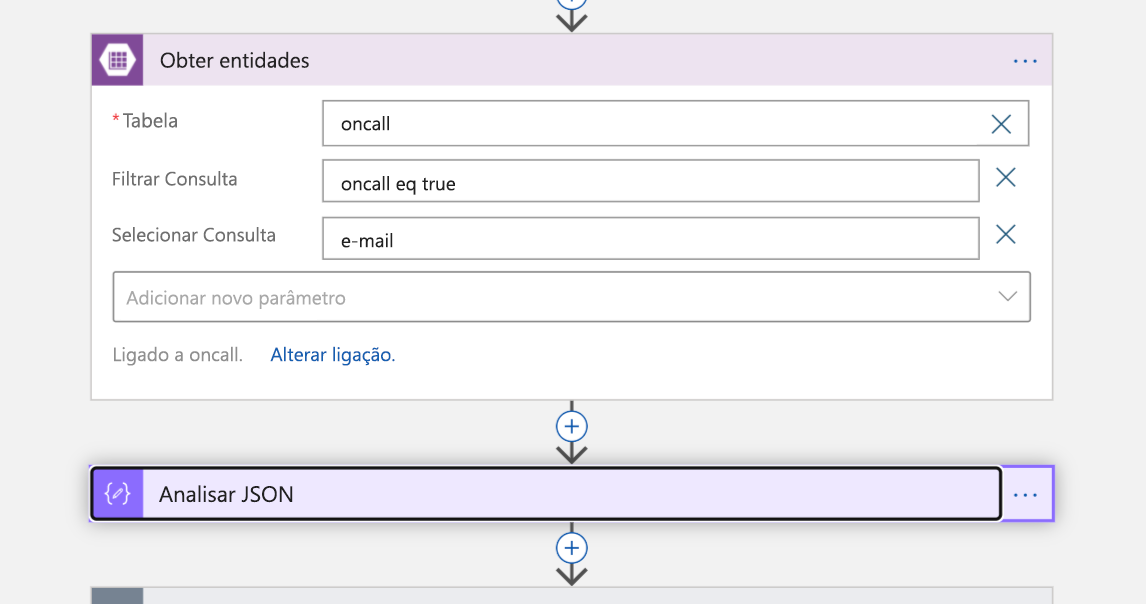
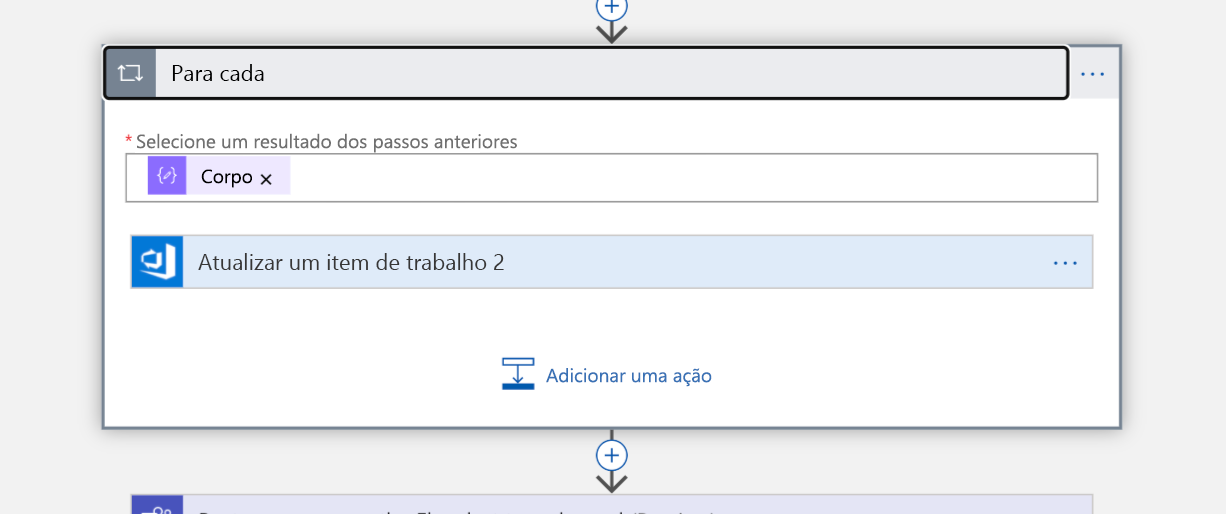
Como nossa consulta retornará uma lista, precisamos iterar sobre cada item dessa lista na próxima etapa. Atribuímos o item de trabalho a cada pessoa (eles agora são "proprietários" do incidente).
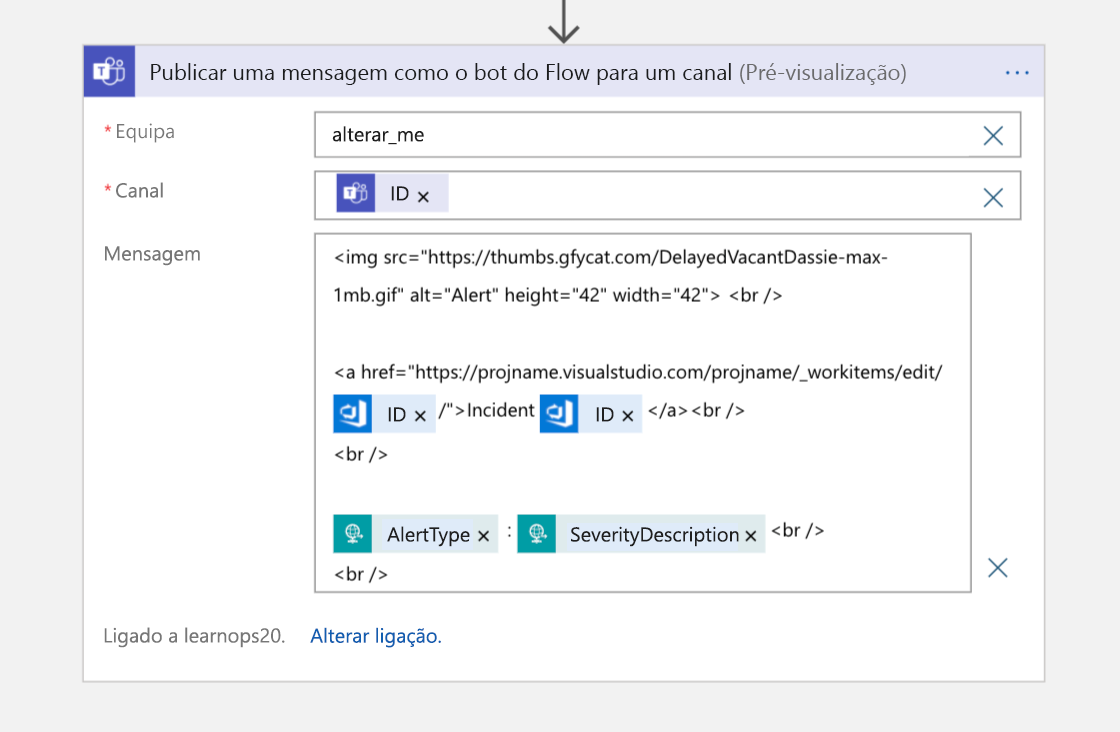
Em seguida, como etapa final, enviamos uma mensagem para o canal do Teams com uma ligação de retorno para o item de trabalho, para as pessoas que entram no canal e querem saber onde as informações oficiais sobre esse incidente estão armazenadas.
Esse é apenas um exemplo de como podemos automatizar a configuração dos mecanismos de rastreamento e comunicação de incidentes. Na próxima unidade, vamos nos aprofundar um pouco mais nos aspetos da comunicação em torno de um incidente.