Autenticação e autorização do sistema de arquivos
Depois de entender o desempenho geral e as características de tráfego da sua carga de trabalho, você precisará considerar os aspetos de segurança. Seus dados podem ser sensíveis, como imagens radiológicas de pacientes. Talvez você queira restringir o acesso aos dados por vários motivos. Poderá querer oferecer a cada um dos seus investigadores um "diretório base" a partir do qual possam carregar dados e realizar análises e simulações HPC.
Ao selecionar seu armazenamento HPC na nuvem, esteja ciente de como ele se integra à sua postura de segurança atual. Compreenda os métodos pelos quais seu sistema de arquivos autentica e autoriza o acesso aos arquivos. Observe se a imposição é local ou remota (ou ambas) e onde a autenticação e a autorização são originadas. Se você usa um sistema de arquivos compartilhado remoto, precisa entender como controlar o acesso usando práticas NAS padrão. Finalmente, se você oferece espaços de trabalho exclusivos para os usuários (diretórios home), entenda como alocar esse espaço.
Nesta unidade, examinamos as considerações de segurança e como elas afetam sua arquitetura de armazenamento.
Visão geral da autenticação e autorização
Autenticação: quando você fornece acesso a sistemas de arquivos, precisa autenticar o solicitante usando alguma credencial confiável. Muitas arquiteturas cliente/servidor emitem desafios para essas credenciais, como contas de usuário ou computador. Essas credenciais são verificadas para garantir que são válidas para o ambiente. Após a autenticação, o solicitante (o usuário ou o computador/processo) é então autorizado. Os protocolos de acesso necessários para seu ambiente podem limitar a autenticação para sua solução. Por exemplo, se você tiver um ambiente Windows, provavelmente está usando o SMB (Server Message Block) como o protocolo de acesso a arquivos de rede. Os requisitos de autenticação SMB não são os mesmos que os requisitos NFS.
Autorização: Permitir que um usuário ou computador acesse um ambiente é uma coisa, mas que nível de acesso? Por exemplo, o usuário A pode ser capaz de ler arquivos em um sistema de arquivos e o usuário B pode ser capaz de ler e gravar arquivos. A autorização pode ir além da leitura e da escrita. Por exemplo, o usuário C pode ser capaz de modificar arquivos, mas não criar novos em um determinado diretório.
O nível de autorização geralmente é expresso como permissões para um determinado arquivo. Estes incluem leitura, escrita e execução.
Usuários e grupos: conceder acesso a um conjunto de recursos pode se tornar complicado quando você tem um grande número de usuários. Também se torna complicado se você pretende conceder diferentes níveis de acesso a vários conjuntos de usuários. O recurso a grupos torna-se então necessário. Você pode atribuir um usuário a um grupo ou conjunto de grupos específico. Em seguida, você pode autorizar o acesso a recursos com base nessa identificação de grupo.
A autenticação e a autorização, em conjunto, representam o acesso ao nível do utilizador, do grupo e ao nível do computador que pretende conceder aos recursos, no nosso caso, aos ficheiros.
O sistema operacional Linux atribui um identificador de usuário (UID) a contas de usuário individuais. O UID é um inteiro. É o que o sistema usa para determinar quais recursos do sistema, incluindo arquivos e pastas, um usuário específico pode acessar.
O sistema operacional Linux usa identificadores de grupo (GIDs) para atribuições de grupo. Um usuário está associado a um único grupo primário. Os usuários podem ser associados a praticamente qualquer número de tarefas de grupo suplementares, até 65.536 na maioria dos sistemas Linux modernos.
Autenticação e autorização local e remota
A autenticação e autorização locais referem-se ao acesso de um sistema de arquivos local por uma conta de usuário/computador que também é local para o computador. Por exemplo, posso criar uma conta de usuário que, em seguida, concedo acesso ao diretório /data localizado no meu sistema de arquivos local. Essa conta de usuário é local, assim como qualquer concessão de acesso ao diretório. Também posso usar a atribuição de grupo para controlar o acesso. A combinação de autorização de usuário e grupo dá a um usuário permissões efetivas sobre um arquivo ou pasta.
Se você olhar para uma saída típica do ls -al comando directory, você pode ver algo assim:
drwxr-xr-x 4 root root 4096 Dec 31 19:43.
drwxr-xr-x 13 root root 4096 Dec 11 05:53 ..
drwxr-xr-x 6 root root 4096 Dec 31 19:43 microsoft
drwxr-xr-x 8 root root 4096 Dec 31 19:43 omi
-rw-r--r-- 1 root root 0 Jan 21 15:10 test.txt
Os drwxr-xr-x caracteres representam o nível de acesso autorizado que os usuários e grupos têm ao arquivo ou diretório. O d indica que a entrada é um diretório. (Se o primeiro valor for -, a entrada é uma entrada de arquivo.) Os caracteres restantes representam a autorização do grupo de permissão de ler (r), escrever (w) e executar (x). Os três primeiros valores indicam o "proprietário" do arquivo ou diretório. Os três segundos valores indicam as permissões de grupo atribuídas ao arquivo ou diretório. Os três valores finais indicam permissões permitidas a todos os outros usuários no sistema.
Eis um exemplo:
-rw-r--r-- 1 root root 0 Jan 21 15:10 test.txt
-Indica que este recurso é um ficheiro.rw-indica que o proprietário tem permissões de leitura e gravação.r--Indica que o grupo atribuído tem apenas permissões de leitura.r--Indica que os usuários restantes têm apenas permissões de leitura.- Observe também que o usuário proprietário e o grupo atribuído são representados pelas duas
rootcolunas.
Um UID e GIDs primários e suplementares representam um usuário autenticado em um computador local. Esses valores são locais para o computador. O que acontece se tiver cinco ou mesmo 50 computadores? Você teria que replicar as atribuições UID e GID em cada um desses computadores. O nível de complexidade em torno do gerenciamento de usuários cresce, assim como a possibilidade de conceder acidentalmente acesso a arquivos ou pastas ao usuário errado.
Acesso remoto a ficheiros através de NFS
A atribuição local de UID e GID funciona bem se você estiver executando tudo como uma única atribuição de usuário/grupo. E se várias partes interessadas estiverem consumindo o cluster HPC que você está executando e cada parte interessada tiver dados confidenciais e vários consumidores dos dados?
A localização de dados em um servidor de arquivos ou ambiente NAS permite o acesso remoto dos dados. Essa abordagem ajuda a reduzir o custo do disco local, garante que os dados estejam atualizados para todos os usuários e reduz o gerenciamento geral de usuários e grupos.
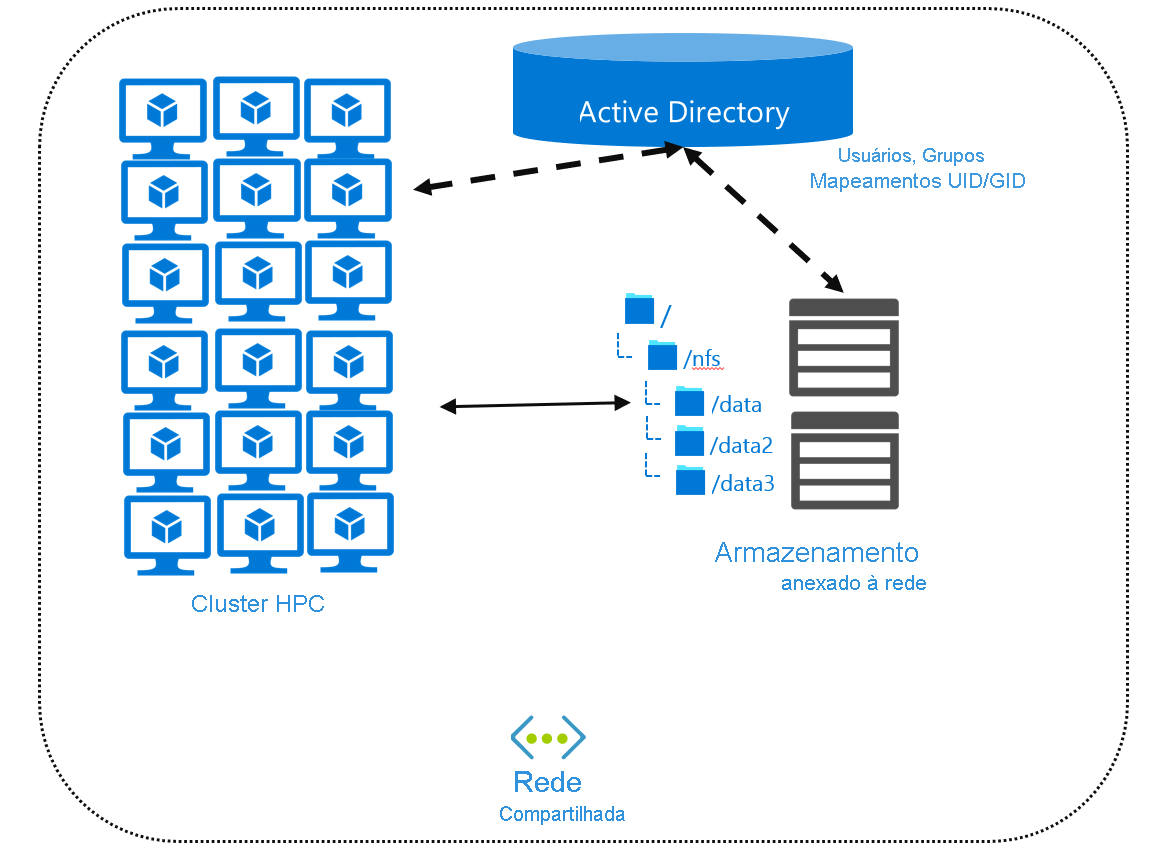
Se você localizar arquivos centralmente, talvez precise de um serviço de diretório que contenha a configuração de usuário e grupo. Os serviços de diretório, como o Ative Directory ou o Lightweight Directory Access Protocol (LDAP), permitem criar um mapeamento de usuário/grupo que todos os sistemas remotos podem usar. Você configura seus computadores remotos e seu ambiente NAS como clientes do serviço de diretório. Você também pode usar mapeamentos do Ative Directory entre suas contas de usuário do Windows e uma combinação específica de UID e GID.
O método típico para acessar arquivos remotamente é usar um sistema de arquivos de rede como NFS ou SMB, ou um sistema de arquivos paralelo como o Lustre. Esses protocolos definem a API de cliente e servidor para acessar dados. Discutimos as operações NFS na unidade "Considerações sobre o desempenho do sistema de arquivos". Discutiremos detalhadamente o uso do NFS na próxima unidade.
Nota
Um serviço de diretório não é necessário quando você usa NFS. Mas se você não usar um, o gerenciamento de UID e GID ainda será difícil se você tiver um grande número de usuários e sistemas.
Diretórios base
Digamos que você tenha um ambiente de HPC que vários pesquisadores estão usando, mas seus dados exclusivos devem ser mantidos separados. Digamos que esses pesquisadores estão continuamente modificando e adicionando aos seus próprios dados. Fornecer aos pesquisadores seus próprios diretórios domésticos é uma maneira eficiente de segregar seus dados.
Cada pesquisador manipularia as permissões dentro do diretório inicial, para que eles pudessem colaborar se quisessem.
Um dos principais desafios neste ambiente é o espaço de armazenamento. Digamos que você tenha um ambiente NAS de 500 TB. O que impede um pesquisador de usar tudo?
Você pode atribuir uma cota a um diretório individual. A quota reflete a quantidade máxima de dados permitida. Depois que a cota é atingida, ele pode rejeitar mais dados ou avisar os administradores que o pesquisador excedeu o limite. Por exemplo, se você tiver um sistema NAS, poderá atribuir uma cota a cada pesquisador. E se você isolar o acesso dos pesquisadores ao diretório inicial, torna-se fácil configurar e monitorar seu uso.