Acesso a arquivos para trabalhos de HPC
O acesso ao armazenamento é uma parte importante do planejamento do desempenho da carga de trabalho de HPC. Você precisa garantir que os dados necessários cheguem às máquinas de cluster HPC no momento certo. Você também precisa garantir que os resultados dessas máquinas individuais sejam salvos rapidamente e estejam disponíveis para análise adicional.
Os ficheiros podem incluir diferentes tipos de dados, incluindo:
- Dados não estruturados, como imagens, documentos ou arquivos de mídia.
- Dados de séries cronológicas de várias fontes.
- Dados de preços (como histórico de preços de ações).
- Ativos usados para análise computacional, como dados genômicos, imagens radiológicas ou simulação meteorológica.
Presume-se que os dados estejam em uma ou mais soluções de armazenamento em seu ambiente local. As arquiteturas de armazenamento neste contexto incluem:
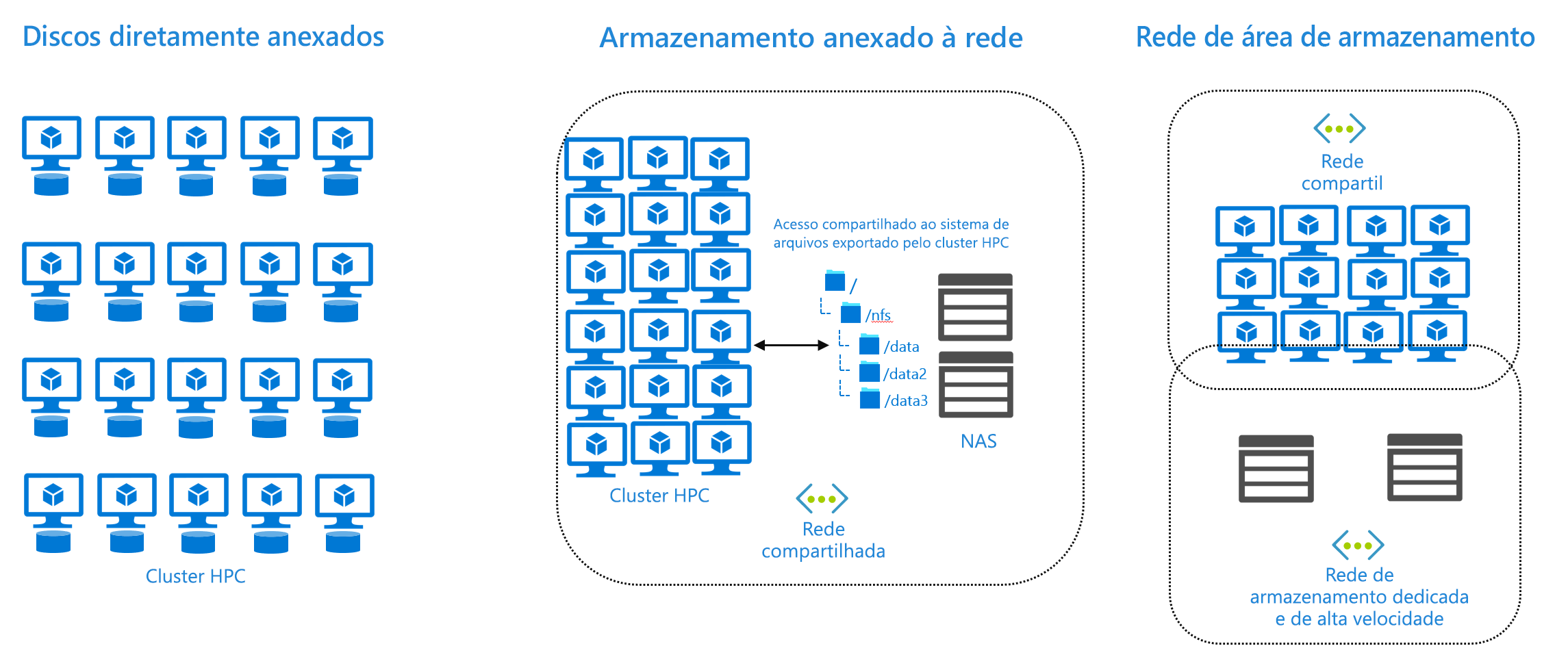
- Discos conectados diretamente. Ou seja, cada máquina no cluster HPC tem seus próprios discos de armazenamento local.
- Soluções de armazenamento conectado à rede (NAS).
- Soluções de SAN (Storage Area Network, rede de armazenamento de dados).
Analistas, artistas, pesquisadores ou cientistas podem criar os dados localmente. Ou, os dados podem ser adquiridos periodicamente de terceiros e depositados em sua solução de armazenamento local.
Tipos de acesso a ficheiros
Os casos gerais de uso de acesso a arquivos que discutimos neste módulo estão limitados a estas atividades:
- Carregar e executar código de trabalho, bibliotecas e/ou cadeias de ferramentas nas máquinas de cluster HPC.
- Leitura de dados de origem para um trabalho. Por exemplo, dados de preços diários, dados genômicos ou dados de satélite.
- Escreve intermediário, ou scratch. Alguns trabalhos exigem que os dados iniciais sejam processados e que a saída desse processamento se torne uma nova entrada para a atividade a jusante.
- Escrever os resultados de um trabalho. Este caso de uso envolve colocar os dados em um local desejável para consumo posterior. Por exemplo, renderizar um vídeo e colocar os resultados renderizados em um volume compartilhado para uso.
Como é que as máquinas HPC obtêm dados do conjunto de trabalho?
As máquinas no cluster HPC acedem aos ficheiros através de um disco diretamente ligado ou através de uma exportação ou partilha de rede. Em ambos os casos, os arquivos são apresentados em um caminho local (por exemplo, /mnt/data).
O código e os scripts que compõem o trabalho HPC real assumem que os arquivos estão acessíveis nesse sistema de arquivos e usam os recursos de acesso a arquivos da máquina para obter os arquivos. Por exemplo, uma máquina executando Linux que precisa acessar um arquivo localizado em um NAS usaria o protocolo NFS (Network File System) e pacotes de cliente NFS instalados como parte do sistema operacional.
Compreender os metadados dos ficheiros
Um arquivo armazena dados reais (por exemplo, uma imagem ou linhas de texto) e informações adicionais conhecidas como metadados. Esses metadados existem dentro dos dados do arquivo ou em um diretório. É importante entender esses metadados no contexto do desempenho do sistema de arquivos HPC.
Metadados são um conjunto de valores que descreve atributos de dados, mas que não fazem parte dos dados. Por exemplo, os metadados informam quando um arquivo foi criado e modificado, quem criou o arquivo e quem tem permissões para acessá-lo.
Quando um arquivo é criado, há operações de metadados que alocam as estruturas e atualizam as entradas de diretório para o arquivo. Essas operações acontecem antes que os dados sejam gravados no arquivo.