Trabalhar com o Microsoft Fabric lakehouses
Agora que você entende os principais recursos de um lago do Microsoft Fabric, vamos explorar como trabalhar com um.
Crie e explore uma casa no lago
Ao criar uma nova lakehouse, você tem três itens de dados diferentes criados automaticamente em seu espaço de trabalho.
- A casa do lago contém atalhos, pastas, arquivos e tabelas.
- O modelo semântico (padrão) fornece uma fonte de dados fácil para desenvolvedores de relatórios do Power BI.
- O ponto de extremidade de análise SQL permite acesso somente leitura a dados de consulta com SQL.
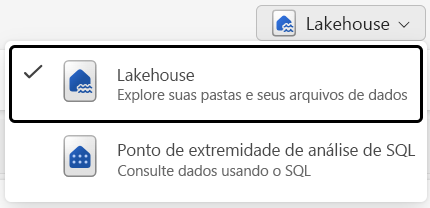
Você pode trabalhar com os dados na casa do lago em dois modos:
- Lakehouse permite que você adicione e interaja com tabelas, arquivos e pastas no Lakehouse.
- O ponto de extremidade de análise SQL permite que você use SQL para consultar as tabelas no lakehouse e gerenciar seu modelo semântico relacional.
Ingerir dados em uma casa de lago
Ingerir dados em sua casa de lago é o primeiro passo em seu processo de ETL. Use qualquer um dos seguintes métodos para trazer dados para sua casa do lago.
- Upload: Carregue arquivos locais.
- Dataflows Gen2: Importe e transforme dados usando o Power Query.
- Notebooks: use o Apache Spark para ingerir, transformar e carregar dados.
- Pipelines do Data Factory: use a atividade Copiar dados.
Esses dados podem ser carregados diretamente em arquivos ou tabelas. Considere seu padrão de carregamento de dados ao ingerir dados para determinar se você deve carregar todos os dados brutos como arquivos antes de processar ou usar tabelas de preparo.
As definições de trabalho do Spark também podem ser usadas para enviar trabalhos em lote/streaming para clusters do Spark. Ao carregar os arquivos binários a partir da saída de compilação de diferentes linguagens (por exemplo, .jar de Java), você pode aplicar diferentes lógicas de transformação aos dados hospedados em um lakehouse. Além do arquivo binário, você pode personalizar ainda mais o comportamento do trabalho carregando mais bibliotecas e argumentos de linha de comando.
Nota
Para obter mais informações, consulte a documentação Criar uma definição de tarefa do Apache Spark.
Acessar dados usando atalhos
Outra maneira de acessar e usar dados no Fabric é usar atalhos. Os atalhos permitem que você integre dados em sua casa do lago, mantendo-os armazenados em armazenamento externo.
Os atalhos são úteis quando você precisa obter dados que estão em uma conta de armazenamento diferente ou até mesmo em um provedor de nuvem diferente. Dentro do seu lakehouse, você pode criar atalhos que apontam para diferentes contas de armazenamento e outros itens do Fabric, como data warehouses, bancos de dados KQL e outros lakehouses.
As permissões e credenciais dos dados de origem são gerenciadas pela OneLake. Ao acessar dados por meio de um atalho para outro local do OneLake, a identidade do usuário chamador será utilizada para autorizar o acesso aos dados no caminho de destino do atalho. O usuário deve ter permissões no local de destino para ler os dados.
Os atalhos podem ser criados em casas de lago e bancos de dados KQL, e aparecem como uma pasta no lago. Isso permite que o Spark, o SQL, a inteligência em tempo real e o Analysis Services utilizem atalhos ao consultar dados.
Nota
Para obter mais informações sobre como usar atalhos, consulte a documentação de atalhos do OneLake na documentação do Microsoft Fabric.