Compreender os fundamentos do armazém de dados
O processo de construção de um armazém de dados moderno normalmente consiste em:
- Ingestão de dados - mover dados de sistemas de origem para um armazém de dados.
- Armazenamento de dados - armazenando os dados em um formato otimizado para análise.
- Processamento de dados - transformar os dados em um formato pronto para consumo por ferramentas analíticas.
- Análise e entrega de dados - analisar os dados para obter insights e fornecer esses insights para o negócio.
O Microsoft Fabric permite que engenheiros e analistas de dados ingeram, armazenem, transformem e visualizem dados em uma única ferramenta com uma experiência low-code e tradicional.
Compreender a experiência de data warehouse do Fabric
O data warehouse do Fabric é um data warehouse relacional que suporta todos os recursos transacionais do T-SQL que você esperaria de um data warehouse corporativo. É um data warehouse totalmente gerenciado, escalável e altamente disponível que pode ser usado para armazenar e consultar dados no Lakehouse. Usando o data warehouse, você tem total controle sobre a criação de tabelas, carregamento, transformação e consulta de dados usando o portal Fabric ou comandos T-SQL. Você pode usar SQL para consultar e analisar os dados ou usar o Spark para processar os dados e criar modelos de aprendizado de máquina.
Os armazéns de dados no Fabric facilitam a colaboração entre engenheiros de dados e analistas de dados, trabalhando juntos na mesma experiência. Os engenheiros de dados criam uma camada relacional sobre os dados no Lakehouse, onde os analistas podem usar o T-SQL e o Power BI para explorar os dados.
Projetar um data warehouse
Como todos os bancos de dados relacionais, o data warehouse do Fabric contém tabelas para armazenar seus dados para análise posterior. Mais comumente, essas tabelas são organizadas em um esquema otimizado para modelagem multidimensional. Nesta abordagem, os dados numéricos relacionados com eventos (por exemplo, ordens de venda) são agrupados por diferentes atributos (por exemplo, data, cliente, loja). Por exemplo, você pode analisar o valor total pago por ordens de venda que ocorreram em uma data específica ou em uma loja específica.
Tabelas em um data warehouse
As tabelas em um data warehouse são normalmente organizadas de forma a oferecer suporte à análise eficiente e eficaz de grandes quantidades de dados. Esta organização é muitas vezes referida como modelagem dimensional, que envolve a estruturação de tabelas em tabelas de fatos e tabelas de dimensão.
As tabelas de fatos contêm os dados numéricos que você deseja analisar. As tabelas de fatos normalmente têm um grande número de linhas e são a principal fonte de dados para análise. Por exemplo, uma tabela de fatos pode conter o valor total pago por ordens de venda que ocorreram em uma data específica ou em uma loja específica.
As tabelas de dimensões contêm informações descritivas sobre os dados nas tabelas de fatos. As tabelas de dimensão normalmente têm um pequeno número de linhas e são usadas para fornecer contexto para os dados nas tabelas de fatos. Por exemplo, uma tabela de dimensões pode conter informações sobre os clientes que colocaram ordens de venda.
Além das colunas de atributo, uma tabela de dimensões contém uma coluna de chave exclusiva que identifica exclusivamente cada linha da tabela. Na verdade, é comum que uma tabela de dimensões inclua duas colunas principais:
- Uma chave substituta é um identificador exclusivo para cada linha na tabela de dimensões. Geralmente, é um valor inteiro que é gerado automaticamente pelo sistema de gerenciamento de banco de dados quando uma nova linha é inserida na tabela.
- Uma chave alternativa geralmente é uma chave natural ou comercial que identifica uma instância específica de uma entidade no sistema de origem transacional - como um código de produto ou um ID de cliente.
Você precisa de chaves substitutas e alternativas em um data warehouse, porque elas servem a finalidades diferentes. As chaves substitutas são específicas do armazém de dados e ajudam a manter a consistência e a precisão dos dados. As chaves alternativas, por outro lado, são específicas do sistema de origem e ajudam a manter a rastreabilidade entre o data warehouse e o sistema de origem.
Tipos especiais de tabelas de dimensões
Tipos especiais de dimensões fornecem contexto adicional e permitem uma análise de dados mais abrangente.
As dimensões de tempo fornecem informações sobre o período de tempo em que um evento ocorreu. Esta tabela permite que os analistas de dados agreguem dados em intervalos temporais. Por exemplo, uma dimensão de tempo pode incluir colunas para o ano, trimestre, mês e dia em que uma ordem de venda foi colocada.
As dimensões que mudam lentamente são tabelas de dimensões que controlam as alterações nos atributos de dimensão ao longo do tempo, como alterações no endereço de um cliente ou no preço de um produto. Eles são significativos em um data warehouse porque permitem que os usuários analisem e entendam as alterações nos dados ao longo do tempo. Dimensões em mudança lenta garantem que os dados permaneçam atualizados e precisos, o que é imperativo para tomar boas decisões de negócios.
Projetos de esquema de armazém de dados
Na maioria dos bancos de dados transacionais usados em aplicativos de negócios, os dados são normalizados para reduzir a duplicação. Em um data warehouse, no entanto, os dados de dimensão geralmente são desnormalizados para reduzir o número de junções necessárias para consultar os dados.
Muitas vezes, um data warehouse é organizado como um esquema em estrela, no qual uma tabela de fatos está diretamente relacionada às tabelas de dimensão, como mostrado neste exemplo:
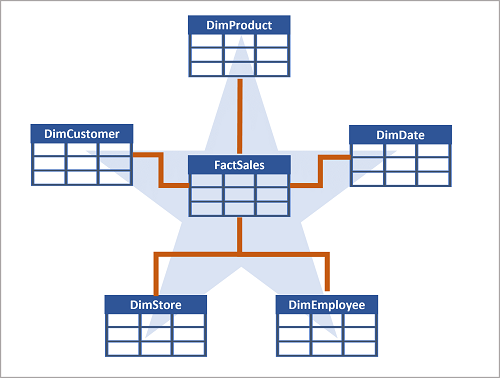
Você pode usar os atributos de algo para agrupar números na tabela de fatos em diferentes níveis. Por exemplo, você pode encontrar a receita total de vendas para uma região inteira ou apenas para um cliente. As informações para cada nível podem ser armazenadas na mesma tabela de dimensão.
Gorjeta
Consulte O que é um esquema em estrela? para obter mais informações sobre como criar esquemas em estrela para o Fabric.
Se houver muitos níveis ou alguma informação for compartilhada por coisas diferentes, pode fazer sentido usar um esquema de floco de neve. Eis um exemplo:
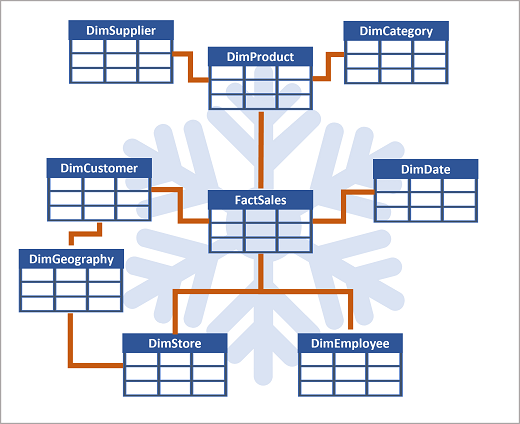
Neste caso, a tabela DimProduct foi dividida (normalizada) para criar tabelas de dimensão separadas para categorias de produtos e fornecedores.
- Cada linha na tabela DimProduct contém valores-chave para as linhas correspondentes nas tabelas DimCategory e DimSupplier.
Uma tabela DimGeography foi adicionada contendo informações sobre onde os clientes e lojas estão localizados.
- Cada linha nas tabelas DimCustomer e DimStore contém um valor de chave para a linha correspondente na tabela DimGeography .