O que é machine learning?
O aprendizado de máquina tem suas origens na estatística e na modelagem matemática de dados. A ideia fundamental do aprendizado de máquina é usar dados de observações passadas para prever resultados ou valores desconhecidos. Por exemplo:
- O proprietário de uma sorveteria pode usar um aplicativo que combina vendas históricas e registros meteorológicos para prever quantos sorvetes eles provavelmente venderão em um determinado dia, com base na previsão do tempo.
- Um médico pode usar dados clínicos de pacientes anteriores para executar testes automatizados que preveem se um novo paciente está em risco de diabetes com base em fatores como peso, nível de glicose no sangue e outras medições.
- Um pesquisador na Antártida pode usar observações passadas para automatizar a identificação de diferentes espécies de pinguins (como Adelie, Gentoo ou Chinstrap) com base em medições das nadadeiras, bico e outros atributos físicos de uma ave.
Aprendizagem automática como função
Como o aprendizado de máquina é baseado em matemática e estatística, é comum pensar em modelos de aprendizado de máquina em termos matemáticos. Fundamentalmente, um modelo de aprendizado de máquina é um aplicativo de software que encapsula uma função para calcular um valor de saída com base em um ou mais valores de entrada. O processo de definição dessa função é conhecido como treinamento. Depois que a função for definida, você poderá usá-la para prever novos valores em um processo chamado inferência.
Vamos explorar as etapas envolvidas no treinamento e na inferência.
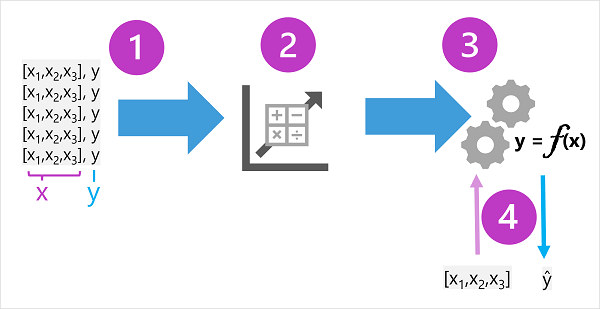
Os dados de treinamento consistem em observações passadas. Na maioria dos casos, as observações incluem os atributos ou características observados da coisa que está sendo observada e o valor conhecido da coisa que você deseja treinar um modelo para prever (conhecido como rótulo).
Em termos matemáticos, muitas vezes você verá os recursos referidos usando o nome da variável abreviada x, e o rótulo referido como y. Normalmente, uma observação consiste em vários valores de feição, então x é na verdade um vetor (uma matriz com vários valores), assim: [x1,x 2,x 3,...].
Para deixar isso mais claro, vamos considerar os exemplos descritos anteriormente:
- No cenário de vendas de sorvetes, nosso objetivo é treinar um modelo que possa prever o número de vendas de sorvetes com base no clima. As medidas meteorológicas para o dia (temperatura, precipitação, velocidade do vento, etc.) seriam as características (x), e o número de sorvetes vendidos em cada dia seria o rótulo (y).
- No cenário médico, o objetivo é prever se um paciente está ou não em risco de diabetes com base em suas medições clínicas. As medidas do paciente (peso, nível de glicose no sangue, etc.) são as características (x), e a probabilidade de diabetes (por exemplo, 1 para em risco, 0 para não em risco) é o rótulo (y).
- No cenário de pesquisa antártica, queremos prever a espécie de um pinguim com base em seus atributos físicos. As principais medidas do pinguim (comprimento de suas nadadeiras, largura de seu bico, e assim por diante) são as características (x), e a espécie (por exemplo, 0 para Adelie, 1 para Gentoo, ou 2 para Chinstrap) é o rótulo (y).
Um algoritmo é aplicado aos dados para tentar determinar uma relação entre os recursos e o rótulo, e generalizar essa relação como um cálculo que pode ser realizado em x para calcular y. O algoritmo específico usado depende do tipo de problema preditivo que você está tentando resolver (mais sobre isso mais tarde), mas o princípio básico é tentar ajustar uma função aos dados, na qual os valores dos recursos podem ser usados para calcular o rótulo.
O resultado do algoritmo é um modelo que encapsula o cálculo derivado pelo algoritmo como uma função - vamos chamá-lo de f. Em notação matemática:
y = f(x)
Agora que a fase de treinamento está concluída, o modelo treinado pode ser usado para inferência. O modelo é essencialmente um programa de software que encapsula a função produzida pelo processo de treinamento. Você pode inserir um conjunto de valores de recurso e receber como saída uma previsão do rótulo correspondente. Como a saída do modelo é uma previsão que foi calculada pela função, e não um valor observado, muitas vezes você verá a saída da função mostrada como ŷ (que é deliciosamente verbalizada como "y-hat").