O que são modelos linguísticos?
Os aplicativos de IA generativa são alimentados por modelos de linguagem, que são um tipo especializado de modelo de aprendizado de máquina que você pode usar para executar tarefas de processamento de linguagem natural (NLP), incluindo:
- Determinar o sentimento ou de outra forma classificar o texto em linguagem natural.
- Texto resumido.
- Comparação de várias fontes de texto para semelhança semântica.
- Geração de nova linguagem natural.
Embora os princípios matemáticos por trás desses modelos de linguagem possam ser complexos, uma compreensão básica da arquitetura usada para implementá-los pode ajudá-lo a obter uma compreensão conceitual de como eles funcionam.
Modelos de transformadores
Os modelos de aprendizagem automática para processamento de linguagem natural evoluíram ao longo de muitos anos. Os modelos de linguagem de grande porte de ponta de hoje são baseados na arquitetura transformer , que se baseia e estende algumas técnicas que foram comprovadamente bem-sucedidas na modelagem de vocabulários para suportar tarefas de PNL - e, em particular, na geração de linguagem. Os modelos transformadores são treinados com grandes volumes de texto, permitindo-lhes representar as relações semânticas entre palavras e usar essas relações para determinar prováveis sequências de texto que façam sentido. Modelos de transformadores com um vocabulário suficientemente grande são capazes de gerar respostas de linguagem que são difíceis de distinguir das respostas humanas.
A arquitetura do modelo do transformador consiste em dois componentes, ou blocos:
- Um bloco codificador que cria representações semânticas do vocabulário de treinamento.
- Um bloco decodificador que gera novas sequências de linguagem.
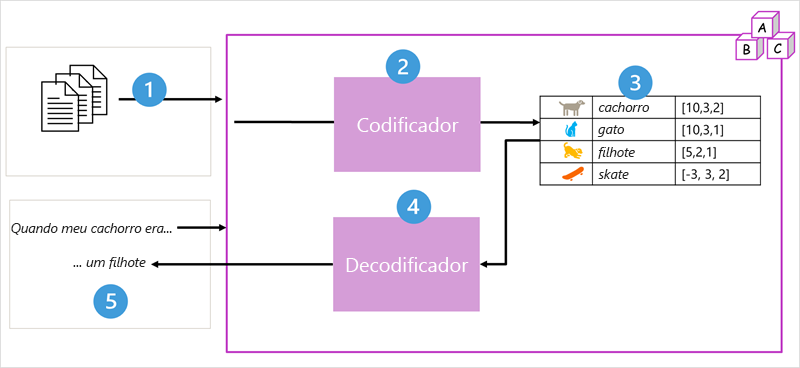
- O modelo é treinado com um grande volume de texto em linguagem natural, muitas vezes proveniente da internet ou de outras fontes públicas de texto.
- As sequências de texto são divididas em tokens (por exemplo, palavras individuais) e o bloco codificador processa essas sequências de token usando uma técnica chamada atenção para determinar relações entre tokens (por exemplo, quais tokens influenciam a presença de outros tokens em uma sequência, tokens diferentes que são comumente usados no mesmo contexto e assim por diante).
- A saída do codificador é uma coleção de vetores (matrizes numéricas de vários valores) em que cada elemento do vetor representa um atributo semântico dos tokens. Esses vetores são chamados de incorporações.
- O bloco decodificador funciona em uma nova sequência de tokens de texto e usa as incorporações geradas pelo codificador para gerar uma saída de linguagem natural apropriada.
- Por exemplo, dada uma sequência de entrada como "Quando meu cão estava", o modelo pode usar a técnica de atenção para analisar os tokens de entrada e os atributos semânticos codificados nas incorporações para prever uma conclusão apropriada da frase, como "um filhote".
Na prática, as implementações específicas da arquitetura variam – por exemplo, o modelo Bidirecional Encoder Representations from Transformers (BERT) desenvolvido pelo Google para suportar seu mecanismo de busca usa apenas o bloco codificador, enquanto o modelo Generative Pretrained Transformer (GPT) desenvolvido pela OpenAI usa apenas o bloco decodificador.
Embora uma explicação completa de todos os aspetos dos modelos de transformadores esteja além do escopo deste módulo, uma explicação de alguns dos elementos-chave em um transformador pode ajudá-lo a ter uma noção de como eles suportam IA generativa.
Tokenização
O primeiro passo no treinamento de um modelo de transformador é decompor o texto de treinamento em tokens - em outras palavras, identificar cada valor de texto único. Por uma questão de simplicidade, você pode pensar em cada palavra distinta no texto de treinamento como um token (embora, na realidade, os tokens possam ser gerados para palavras parciais, ou combinações de palavras e pontuação).
Por exemplo, considere a seguinte frase:
I heard a dog bark loudly at a cat
Para tokenizar esse texto, você pode identificar cada palavra discreta e atribuir IDs de token a elas. Por exemplo:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
A frase agora pode ser representada com os tokens: {1 2 3 4 5 6 7 3 8}. Da mesma forma, a frase "Eu ouvi um gato" poderia ser representada como {1 2 3 8}.
À medida que você continua a treinar o modelo, cada novo token no texto de treinamento é adicionado ao vocabulário com IDs de token apropriados:
- miado (9)
- skate (10)
- e assim por diante...
Com um conjunto suficientemente grande de texto de treinamento, um vocabulário de muitos milhares de tokens poderia ser compilado.
Incorporações
Embora possa ser conveniente representar tokens como IDs simples - essencialmente criando um índice para todas as palavras do vocabulário, eles não nos dizem nada sobre o significado das palavras ou as relações entre elas. Para criar um vocabulário que encapsula relações semânticas entre os tokens, definimos vetores contextuais, conhecidos como incorporações, para eles. Vetores são representações numéricas de vários valores de informação, por exemplo [10, 3, 1] em que cada elemento numérico representa um atributo particular da informação. Para tokens de idioma, cada elemento do vetor de um token representa algum atributo semântico do token. As categorias específicas para os elementos dos vetores em um modelo de linguagem são determinadas durante o treinamento com base na frequência com que as palavras são usadas juntas ou em contextos semelhantes.
Os vetores representam linhas no espaço multidimensional, descrevendo a direção e a distância ao longo de vários eixos (você pode impressionar seus amigos matemáticos chamando essas amplitude e magnitude). Pode ser útil pensar nos elementos em um vetor de incorporação para um token como representando etapas ao longo de um caminho no espaço multidimensional. Por exemplo, um vetor com três elementos representa um caminho no espaço tridimensional no qual os valores dos elementos indicam as unidades viajadas para frente/trás, esquerda/direita e para cima/baixo. No geral, o vetor descreve a direção e a distância do caminho da origem ao fim.
Os elementos dos tokens no espaço de incorporação representam cada um algum atributo semântico do token, de modo que tokens semanticamente semelhantes devem resultar em vetores que têm uma orientação semelhante – em outras palavras, eles apontam na mesma direção. Uma técnica chamada semelhança cosseno é usada para determinar se dois vetores têm direções semelhantes (independentemente da distância) e, portanto, representam palavras semanticamente ligadas. Como um exemplo simples, suponha que as incorporações para nossos tokens consistam em vetores com três elementos, por exemplo:
- 4 ("cão"): [10,3,2]
- 8 ("gato"): [10,3,1]
- 9 ("filhote"): [5,2,1]
- 10 ("skate"): [-3,3,2]
Podemos plotar esses vetores no espaço tridimensional, assim:
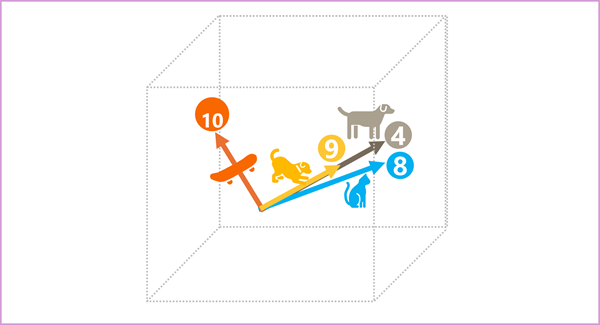
Os vetores de incorporação para "cão" e "filhote" descrevem um caminho ao longo de uma direção quase idêntica, que também é bastante semelhante à direção para "gato". O vetor de incorporação para "skate", no entanto, descreve a jornada em uma direção muito diferente.
Nota
O exemplo anterior mostra um modelo de exemplo simples em que cada incorporação tem apenas três dimensões. Os modelos de linguagem real têm muito mais dimensões.
Há várias maneiras de calcular incorporações apropriadas para um determinado conjunto de tokens, incluindo algoritmos de modelagem de linguagem como Word2Vec ou o bloco codificador em um modelo de transformador .
Atenção
Os blocos codificador e decodificador em um modelo de transformador incluem várias camadas que formam a rede neural para o modelo. Não precisamos entrar nos detalhes de todas essas camadas, mas é útil considerar um dos tipos de camadas que é usado em ambos os blocos: camadas de atenção . A atenção é uma técnica usada para examinar uma sequência de fichas de texto e tentar quantificar a força das relações entre elas. Em particular, a autoatenção envolve considerar como outros tokens em torno de um token específico influenciam o significado desse token.
Em um bloco de codificador, cada token é cuidadosamente examinado no contexto, e uma codificação apropriada é determinada para sua incorporação vetorial. Os valores vetoriais são baseados na relação entre o token e outros tokens com os quais ele aparece com frequência. Esta abordagem contextualizada significa que a mesma palavra pode ter várias incorporações, dependendo do contexto em que é usada - por exemplo, "a casca de uma árvore" significa algo diferente de "ouvi um cão latir".
Em um bloco decodificador, as camadas de atenção são usadas para prever o próximo token em uma sequência. Para cada token gerado, o modelo tem uma camada de atenção que leva em conta a sequência de tokens até aquele ponto. O modelo considera quais dos tokens são os mais influentes ao considerar qual deve ser o próximo token. Por exemplo, dada a sequência "Eu ouvi um cachorro", a camada de atenção pode atribuir maior peso aos tokens "ouvido" e "cão" ao considerar a próxima palavra na sequência:
Ouvi um cão [latir]
Lembre-se de que a camada de atenção está trabalhando com representações vetoriais numéricas dos tokens, não com o texto real. Em um decodificador, o processo começa com uma sequência de incorporações de token representando o texto a ser concluído. A primeira coisa que acontece é que outra camada de codificação posicional adiciona um valor a cada incorporação para indicar sua posição na sequência:
- [1,5,6,2] (I)
- [2,9,3,1] (ouvido)
- [3,1,1,2] a)
- [4,10,3,2] (cão)
Durante o treinamento, o objetivo é prever o vetor para o token final na sequência com base nos tokens anteriores. A camada de atenção atribui um peso numérico a cada token na sequência até agora. Ele usa esse valor para executar um cálculo nos vetores ponderados que produz uma pontuação de atenção que pode ser usada para calcular um possível vetor para o próximo token. Na prática, uma técnica chamada atenção multi-cabeça usa diferentes elementos das incorporações para calcular vários escores de atenção. Uma rede neural é então usada para avaliar todos os tokens possíveis para determinar o token mais provável com o qual continuar a sequência. O processo continua iterativamente para cada token na sequência, com a sequência de saída até agora sendo usada regressivamente como a entrada para a próxima iteração – essencialmente construindo a saída um token de cada vez.
A animação a seguir mostra uma representação simplificada de como isso funciona – na realidade, os cálculos realizados pela camada de atenção são mais complexos; mas os princípios podem ser simplificados como demonstrado:

- Uma sequência de incorporações de token é alimentada na camada de atenção. Cada token é representado como um vetor de valores numéricos.
- O objetivo em um decodificador é prever o próximo token na sequência, que também será um vetor que se alinha a uma incorporação no vocabulário do modelo.
- A camada de atenção avalia a sequência até agora e atribui pesos a cada token para representar sua influência relativa no próximo token.
- Os pesos podem ser usados para calcular um novo vetor para o próximo token com uma pontuação de atenção. A atenção de várias cabeças usa diferentes elementos nas incorporações para calcular vários tokens alternativos.
- Uma rede neural totalmente conectada usa as pontuações nos vetores calculados para prever o token mais provável de todo o vocabulário.
- A saída prevista é anexada à sequência até agora, que é usada como entrada para a próxima iteração.
Durante o treinamento, a sequência real de tokens é conhecida – apenas mascaramos os que vêm mais tarde na sequência do que a posição do token atualmente sendo considerada. Como em qualquer rede neural, o valor previsto para o vetor token é comparado com o valor real do próximo vetor na sequência, e a perda é calculada. Os pesos são então ajustados incrementalmente para reduzir a perda e melhorar o modelo. Quando usada para inferência (previsão de uma nova sequência de tokens), a camada de atenção treinada aplica pesos que predizem o token mais provável no vocabulário do modelo que está semanticamente alinhado à sequência até agora.
O que tudo isso significa, é que um modelo de transformador como GPT-4 (o modelo por trás do ChatGPT e Bing) é projetado para receber uma entrada de texto (chamada de prompt) e gerar uma saída sintaticamente correta (chamada de conclusão). Com efeito, a "magia" do modelo é que ele tem a capacidade de encadear uma frase coerente. Esta capacidade não implica qualquer "conhecimento" ou "inteligência" por parte do modelo; apenas um vocabulário grande e a capacidade de gerar sequências significativas de palavras. O que torna um modelo de linguagem grande como o GPT-4 tão poderoso, no entanto, é o grande volume de dados com os quais foi treinado (dados públicos e licenciados da Internet) e a complexidade da rede. Isso permite que o modelo gere completações baseadas nas relações entre palavras no vocabulário no qual o modelo foi treinado; muitas vezes gerando uma saída que é indistinguível de uma resposta humana ao mesmo prompt.