Entender quando ajustar um modelo de linguagem
Antes de começar a ajustar um modelo, você precisa ter uma compreensão clara do que é ajuste fino e quando você deve usá-lo.
Quando quiser desenvolver um aplicativo de chat com o Azure AI Foundry, você pode usar o fluxo de prompt para criar um aplicativo de chat integrado a um modelo de linguagem para gerar respostas. Para melhorar a qualidade das respostas que o modelo gera, você pode tentar várias estratégias. A estratégia mais fácil é aplicar engenharia rápida. Você pode alterar a maneira como formata sua pergunta, mas também pode atualizar a mensagem do sistema que é enviada junto com o prompt para o modelo de idioma.
A engenharia rápida é uma maneira rápida e fácil de melhorar como o modelo age e o que o modelo precisa saber. Quando você quer melhorar ainda mais a qualidade do modelo, existem duas técnicas comuns que são usadas:
- Geração aumentada de recuperação (RAG): aterre seus dados recuperando primeiro o contexto de uma fonte de dados antes de gerar uma resposta.
- Ajuste fino: treine um modelo de linguagem base em um conjunto de dados antes de integrá-lo ao seu aplicativo.
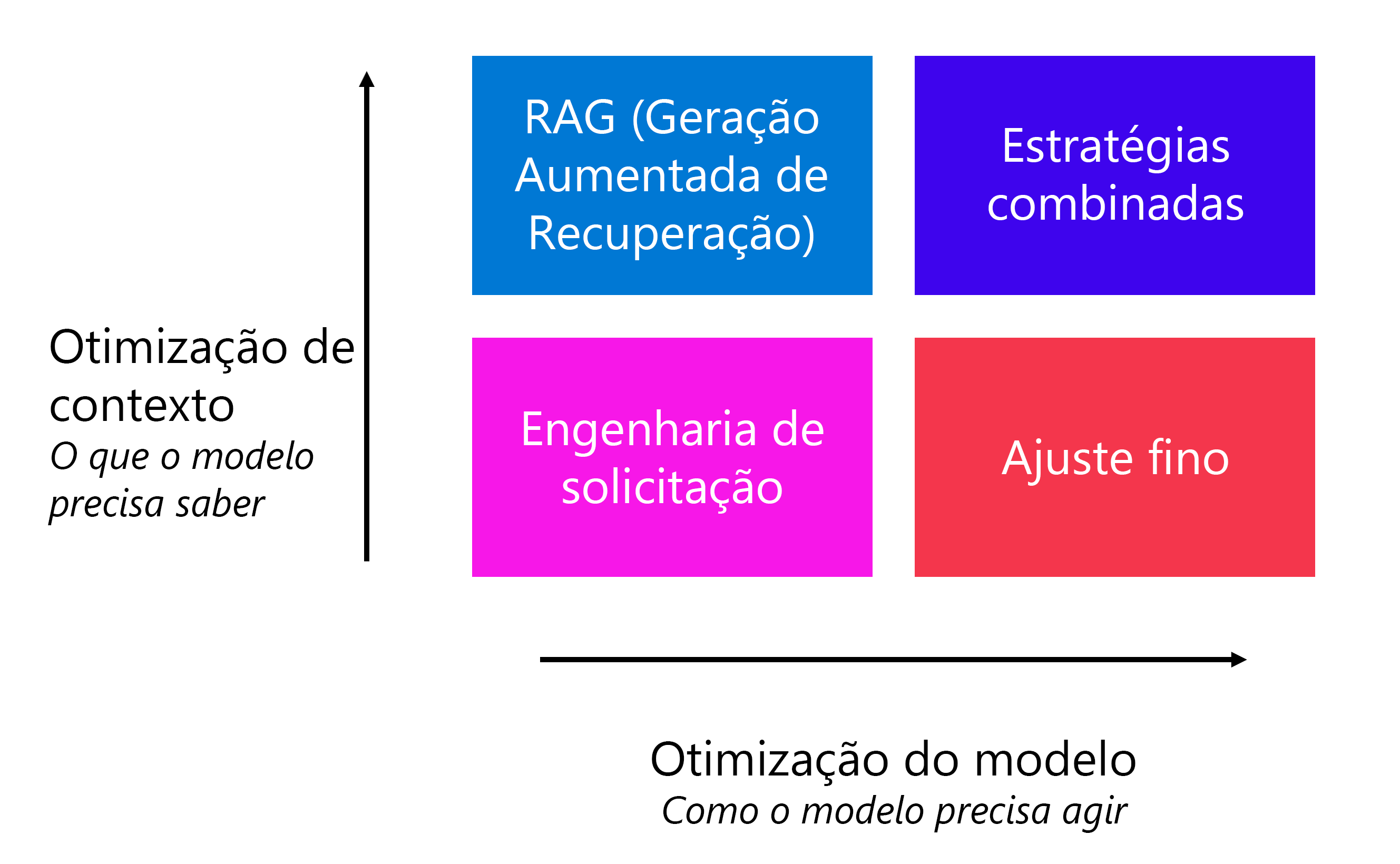
O RAG é mais comumente aplicado quando você precisa que as respostas do modelo sejam factuais e fundamentadas em dados específicos. Por exemplo, você quer que os clientes façam perguntas sobre os hotéis que você está oferecendo em seu catálogo de reservas de viagens. Por outro lado, quando você quer que o modelo se comporte de determinada maneira, o ajuste fino pode ajudá-lo a alcançar seu objetivo. Você também pode usar uma combinação de estratégias de otimização, como RAG e um modelo ajustado, para melhorar seu aplicativo de linguagem.
Como o modelo precisa agir se relaciona principalmente com o estilo, formato e tom das respostas geradas por um modelo. Quando você quiser que seu modelo siga um estilo e formato específicos ao responder, você pode instruir o modelo a fazê-lo por meio de engenharia imediata também. Às vezes, no entanto, a engenharia rápida pode não levar a resultados consistentes. Ainda pode acontecer que um modelo ignore suas instruções e se comporte de forma diferente.
Dentro da engenharia de prompt, uma técnica usada para "forçar" o modelo a gerar saída em um formato específico, é fornecer ao modelo vários exemplos de como a saída desejada pode parecer, também conhecida como one-shot (um exemplo) ou few-shot (poucos exemplos). Ainda assim, pode acontecer que seu modelo nem sempre gere a saída no estilo e formato especificados.
Para maximizar a consistência do comportamento do modelo, você pode ajustar um modelo base com seus próprios dados de treinamento.