Criar índices
O SQL Server tem vários tipos de índice para dar suporte a diferentes tipos de cargas de trabalho. Em um nível alto, um índice pode ser considerado como uma estrutura em disco associada a uma tabela ou exibição, que permite que o SQL Server encontre mais facilmente a linha ou linhas associadas à chave de índice (que consiste em uma ou mais colunas na tabela ou exibição), em comparação com a verificação de toda a tabela.
Índices agrupados
Uma pergunta comum de entrevista de emprego do DBA é perguntar ao candidato a diferença entre um índice clusterizado e não clusterizado, já que os índices são uma tecnologia fundamental de armazenamento de dados no SQL Server. Um índice clusterizado é a tabela subjacente, armazenada em ordem ordenada com base no valor da chave. Só pode haver um índice agrupado em uma determinada tabela, porque as linhas podem ser armazenadas em uma ordem. Uma tabela sem um índice clusterizado é chamada de heap, e heaps normalmente são usados apenas como tabelas de preparo. Um princípio importante de design de desempenho é manter sua chave de índice clusterizada o mais estreita possível. Ao considerar a(s) coluna(s) chave(s) para seu índice clusterizado, você deve considerar colunas que são exclusivas ou que contêm muitos valores distintos. Outra propriedade de uma boa chave de índice clusterizada é para registros que são acessados sequencialmente e são usados com freqüência para classificar os dados recuperados da tabela. Ter o índice clusterizado na coluna usada para classificação pode evitar o custo de classificação toda vez que a consulta for executada, porque os dados já estarão armazenados na ordem desejada.
Nota
Quando dizemos que a tabela é "armazenada" em uma ordem específica, estamos nos referindo à ordem lógica, não necessariamente à ordem física, no disco. Os índices têm ponteiros entre as páginas e os ponteiros ajudam a criar a ordem lógica. Ao verificar um índice 'em ordem', o SQL Server segue os ponteiros de página para página. Imediatamente após a criação de um índice, ele provavelmente também é armazenado em ordem física no disco, mas depois que você começar a fazer modificações nos dados, e novas páginas precisam ser adicionadas ao índice, os ponteiros ainda nos darão a ordem lógica correta, mas as novas páginas mais gostarão de não estar na ordem do disco físico.
Índices não agrupados
Os índices não agrupados são uma estrutura separada das linhas de dados. Um índice não clusterizado contém os valores de chave definidos para o índice e um ponteiro para a linha de dados que contém o valor da chave. Você pode adicionar outra coluna não-chave ao nível de folha do índice não clusterizado para cobrir mais colunas usando o recurso de colunas incluídas no SQL Server. Você pode criar vários índices não clusterizados em uma tabela.
Um exemplo de quando você precisa adicionar um índice ou adicionar colunas a um índice não clusterizado existente é mostrado abaixo:

O plano de consulta indica que, para cada linha recuperada usando a busca de índice, mais dados precisarão ser recuperados do índice clusterizado (a própria tabela). Há um índice não clusterizado, mas ele inclui apenas a coluna do produto. Se você adicionar as outras colunas na consulta a um índice não clusterizado, conforme mostrado abaixo, poderá ver a alteração do plano de execução para eliminar a pesquisa de chaves.

O índice criado acima é um exemplo de um índice de cobertura, onde, além da coluna chave, você está incluindo colunas extras para cobrir a consulta e eliminar a necessidade de acessar a própria tabela.
Os índices não agrupados e agrupados podem ser definidos como exclusivos, o que significa que não pode haver duplicação dos valores de chave. Os índices exclusivos são criados automaticamente quando você cria uma restrição de CHAVE PRIMÁRIA ou EXCLUSIVA em uma tabela.
O foco desta seção está nos índices de árvore b no SQL Server — eles também são conhecidos como índices de armazenamento de linha. A estrutura geral de uma b-tree é mostrada abaixo:
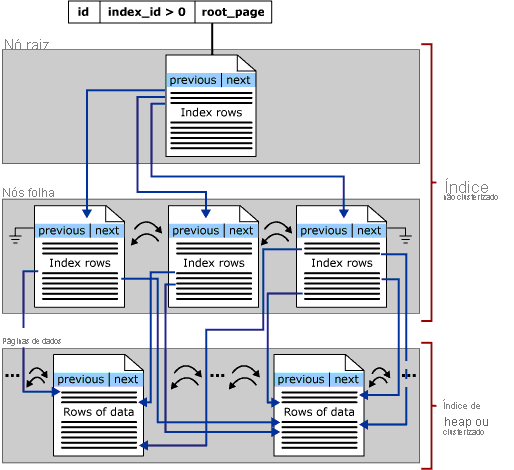
Cada página em uma árvore b de índice é chamada de nó de índice, e o nó superior da árvore b é chamado de nó raiz. Os nós inferiores em um índice são chamados nós de folha e a coleção de nós de folha é o nível de folha.
O design de índices é uma mistura de arte e ciência. Um índice estreito com poucas colunas em sua chave requer menos tempo para atualizar e tem menor sobrecarga de manutenção; no entanto, pode não ser útil para tantas consultas como um índice mais amplo que inclui mais colunas. Talvez seja necessário experimentar várias abordagens de indexação com base nas colunas selecionadas pelas consultas do seu aplicativo. O otimizador de consulta geralmente escolhe o que considera ser o melhor índice existente para uma consulta; No entanto, isso não significa que não haja um índice melhor que possa ser construído.
Indexar corretamente um banco de dados é uma tarefa complexa. Ao planejar seus índices para uma tabela, você deve ter alguns princípios básicos em mente:
- Compreender as cargas de trabalho do sistema. Uma tabela que é usada principalmente para operações de inserção se beneficiará muito menos de índices extras do que uma tabela usada para operações de data warehouse que são 90% de atividade de leitura.
- Entenda quais consultas são executadas com mais frequência e otimize seus índices em torno dessas consultas.
- Entenda os tipos de dados das colunas usadas em suas consultas. Os índices são ideais para tipos de dados inteiros ou colunas exclusivas ou não nulas.
- Crie índices não agrupados em colunas que são frequentemente usadas em predicados e cláusulas de junção e mantenha esses índices o mais estreitos possível para evitar sobrecarga.
- Entender o tamanho/volume de dados – Uma verificação de tabela em uma tabela pequena será uma operação relativamente barata e o SQL Server pode decidir fazer uma verificação de tabela simplesmente porque é fácil (trivial) de fazer. Uma varredura de mesa em uma mesa grande seria cara.
Outra opção que o SQL Server fornece é a criação de índices filtrados. Os índices filtrados são mais adequados para colunas em tabelas grandes em que uma grande percentagem das linhas tem o mesmo valor nessa coluna. Um exemplo prático seria uma tabela de funcionários, como mostrado abaixo, que armazenasse os registros de todos os funcionários, incluindo aqueles que saíram ou se aposentaram.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
Nesta tabela, há uma coluna chamada CurrentFlag, que indica se um funcionário está empregado no momento. Este exemplo usa o tipo de dados bit, indicando apenas dois valores, um para atualmente empregado e zero para não empregado no momento. Um índice filtrado com um WHERE CurrentFlag = 1, na coluna CurrentFlag permitiria consultas eficientes de funcionários atuais.
Você também pode criar índices em modos de exibição, que podem fornecer ganhos de desempenho significativos quando os modos de exibição contêm elementos de consulta, como agregações e/ou junções de tabela.
Índices Columnstore
O Columnstore oferece desempenho aprimorado para consultas que executam grandes cargas de trabalho de agregação. Esse tipo de índice foi originalmente direcionado para data warehouses, mas com o tempo os índices columnstore foram usados em muitas outras cargas de trabalho para ajudar a resolver problemas de desempenho de consulta em tabelas grandes. A partir do SQL Server 2014, há índices columnstore não clusterizados e clusterizados. Como os índices de árvore b, um índice columnstore clusterizado é a própria tabela armazenada de uma maneira especial, e os índices columnstore não clusterizados são armazenados independentemente da tabela. Os índices columnstore agrupados incluem inerentemente todas as colunas de uma determinada tabela. No entanto, ao contrário dos índices clusterizados rowstore, os índices columnstore clusterizados NÃO são classificados.
Os índices columnstore não clusterizados são normalmente usados em dois cenários, o primeiro é quando uma coluna na tabela tem um tipo de dados que não é suportado em um índice columnstore. A maioria dos tipos de dados são suportados, mas XML, CLR, sql_variant, ntext, text e image não são suportados em um índice columnstore. Como um columnstore clusterizado sempre contém todas as colunas da tabela (porque é a tabela), um columnstore não clusterizado é a única opção. O segundo cenário é um índice filtrado — esse cenário é usado em uma arquitetura chamada processamento analítico transacional híbrido (HTAP), onde os dados estão sendo carregados na tabela subjacente e, ao mesmo tempo, os relatórios estão sendo executados na tabela. Ao filtrar o índice (normalmente em um campo de data), esse design permite um bom desempenho de inserção e relatório.
Os índices Columnstore são exclusivos em seu mecanismo de armazenamento, na medida em que cada coluna no índice é armazenada independentemente. Oferece um duplo benefício. Uma consulta usando um índice columnstore só precisa verificar as colunas necessárias para satisfazer a consulta, reduzindo o total de E/S executado, e permite maior compactação, uma vez que os dados na mesma coluna provavelmente serão de natureza semelhante.
Os índices Columnstore têm melhor desempenho em consultas analíticas que examinam grandes quantidades de dados, como tabelas de fatos em um data warehouse. A partir do SQL Server 2016, você pode aumentar um índice columnstore com outro índice não clusterizado b-tree, o que pode ser útil se algumas de suas consultas fizerem pesquisas em valores singleton.
Os índices Columnstore também se beneficiam do modo de execução em lote, que se refere ao processamento de um conjunto de linhas (normalmente cerca de 900) de cada vez versus o mecanismo de banco de dados que processa essas linhas uma de cada vez. Em vez de carregar cada registro independentemente e processá-los, o mecanismo de consulta calcula o cálculo nesse grupo de 900 registros. Este modelo de processamento reduz drasticamente o número de instruções da CPU.
SELECT SUM(Sales) FROM SalesAmount;
O modo de lote pode fornecer um aumento significativo de desempenho em relação ao processamento de linha tradicional. O SQL Server 2019 também inclui o modo de lote para dados de armazenamento de linhas. Embora o modo de lote para rowstore não tenha o mesmo nível de desempenho de leitura que um índice columnstore, as consultas analíticas podem ver uma melhoria de desempenho de até 5x.
O outro benefício que os índices columnstore oferecem às cargas de trabalho do data warehouse é um caminho de carga otimizado para operações de inserção em massa de 102.400 linhas ou mais. Enquanto 102.400 é o valor mínimo para carregar diretamente no columnstore, cada coleção de linhas, chamada de rowgroup, pode ser de até aproximadamente 1.024.000 linhas. Ter menos grupos de linhas, mas mais completos, torna suas consultas SELECT mais eficientes, porque menos grupos de linhas precisam ser verificados para recuperar os registros solicitados. Essas cargas ocorrem na memória e são carregadas diretamente no índice. Para volumes menores, os dados são gravados em uma estrutura de árvore b chamada armazenamento delta e carregados de forma assíncrona no índice.
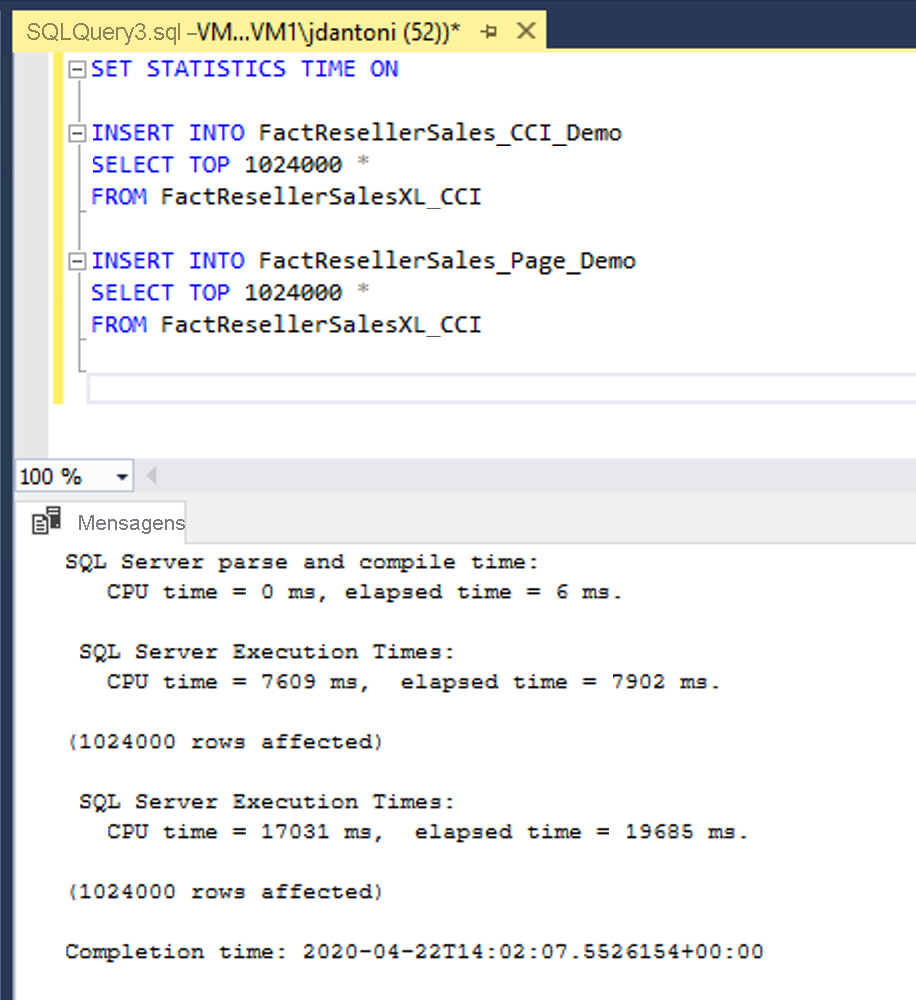
Neste exemplo, os mesmos dados estão sendo carregados em duas tabelas, FactResellerSales_CCI_Demo e FactResellerSales_Page_Demo. O FactResellerSales_CCI_Demo tem um índice columnstore clusterizado e o FactResellerSales_Page_Demo tem um índice de árvore b clusterizado com duas colunas e é compactado de página. Como você pode ver, cada tabela está carregando 1.024.000 linhas da tabela FactResellerSalesXL_CCI . Quando SET STATISTICS TIME é ON, o SQL Server controla o tempo decorrido da execução da consulta. O carregamento dos dados na tabela columnstore levou cerca de 8 segundos, enquanto o carregamento na tabela compactada de página levou quase 20 segundos. Neste exemplo, todas as linhas que vão para o índice columnstore são carregadas em um único grupo de linhas.
Se você carregar menos de 102.400 linhas de dados em um índice columnstore em uma única operação, ele será carregado em uma estrutura de árvore b conhecida como armazenamento delta. O mecanismo de banco de dados move esses dados para o índice columnstore usando um processo assíncrono chamado tuple mover. Ter repositórios delta abertos pode afetar o desempenho de suas consultas, porque a leitura desses registros é menos eficiente do que a leitura do columnstore. Você também pode reorganizar o índice com a opção para forçar os repositórios delta a COMPRESS_ALL_ROW_GROUPS serem adicionados e compactados nos índices columnstore.