Descrever a normalização
A normalização do banco de dados é um processo de design usado para organizar um determinado conjunto de dados em tabelas e colunas em um banco de dados. Cada tabela deve conter dados relativos a uma "coisa" específica e ter apenas dados que suportem essa mesma "coisa" incluídos na tabela. O objetivo desse processo é reduzir os dados duplicados contidos em seu banco de dados, para reduzir a degradação do desempenho de inserções e atualizações de banco de dados. Por exemplo, uma alteração de endereço de cliente é muito mais fácil de implementar se o único local em que o endereço do cliente é armazenado é na tabela Clientes. As formas mais comuns de normalização são primeira, segunda e terceira forma normal e são descritas abaixo.
Primeira forma normal
A primeira forma normal tem as seguintes especificações:
- Criar uma tabela separada para cada conjunto de dados relacionados
- Elimine grupos repetitivos em tabelas individuais
- Identificar cada conjunto de dados relacionados com uma chave primária
Neste modelo, você não deve usar várias colunas em uma única tabela para armazenar dados semelhantes. Por exemplo, se o produto pode vir em várias cores, você não deve ter várias colunas em uma única linha contendo os diferentes valores de cor. A primeira tabela, abaixo (ProductColors), não está na primeira forma normal, pois há valores repetitivos para cor. Para produtos com apenas uma cor, há espaço desperdiçado. E se um produto vier em mais de três cores? Em vez de ter que definir um número máximo de cores, podemos recriar a tabela como mostrado na segunda tabela, ProductColor. Também temos um requisito para a primeira forma normal de que haja uma chave exclusiva para a tabela, que é coluna (ou colunas) cujo valor identifica exclusivamente a linha. Nenhuma das colunas na segunda tabela é exclusiva, mas, juntas, a combinação de ProductID e Color é exclusiva. Quando várias colunas são necessárias, chamamos isso de chave composta.
| ID do Produto | Cor1 | Cor2 | Cor3 |
|---|---|---|---|
| 1 | Vermelho | Verde | Yellow |
| 2 | Yellow | ||
| 3 | Azul | Vermelho | |
| 4 | Azul | ||
| 5 | Vermelho |
| ID do Produto | Cor |
|---|---|
| 1 | Vermelho |
| 1 | Verde |
| 1 | Yellow |
| 2 | Yellow |
| 3 | Azul |
| 3 | Vermelho |
| 4 | Azul |
| 5 | Vermelho |
A terceira tabela, ProductInfo, está na primeira forma normal porque cada linha se refere a um produto específico, não há grupos repetitivos e temos a coluna ProductID para usar como chave primária.
| ID do Produto | Nome do Produto | Preço | ProduçãoPaís | Localização curta |
|---|---|---|---|---|
| 5 | Widget | 15.95 | Estados Unidos da América | E.U.A. |
| 2 | Foop | 41.95 | Reino Unido | Reino Unido |
| 3 | Glombit | 49.95 | Reino Unido | Reino Unido |
| 4 | Sorfina | 99,99 | República das Filipinas | RepPhil |
| 5 | Parafuso de caule | 29.95 | Estados Unidos da América | E.U.A. |
Segunda forma normal
A segunda forma normal tem as seguintes especificações, para além das exigidas pela primeira forma normal:
- Se a tabela tiver uma chave composta, todos os atributos devem depender da chave completa e não apenas de parte dela.
A segunda forma normal só é relevante para tabelas com chaves compostas, como na tabela ProductColor, que é a segunda tabela acima. Considere o caso em que a tabela ProductColor também inclui o preço do produto. Esta tabela tem uma chave composta em ProductID e Color, porque somente usando ambos os valores de coluna podemos identificar exclusivamente uma linha. Se o preço de um produto não mudar com a cor, poderemos ver os dados conforme mostrado nesta tabela:
| ID do Produto | Cor | Preço |
|---|---|---|
| 1 | Vermelho | 15.95 |
| 1 | Verde | 15.95 |
| 1 | Yellow | 15.95 |
| 2 | Yellow | 41.95 |
| 3 | Azul | 49.95 |
| 3 | Vermelho | 49.95 |
| 4 | Azul | 99,95 |
| 5 | Vermelho | 29.95 |
A tabela acima não está na segunda forma normal. O valor do preço depende do ProductID, mas não da Cor. Há três linhas para o ProductID 1, portanto, o preço desse produto é repetido três vezes. O problema com a violação da segunda forma normal é que, se tivermos que atualizar o preço, temos que nos certificar de atualizá-lo em todos os lugares. Se atualizarmos o preço na primeira linha, mas não na segunda ou terceira, teríamos algo chamado "anomalia de atualização". Após a atualização, não saberíamos qual era o preço real do ProductID 1. A solução é mover a coluna Preço para uma tabela que tenha ProductID como uma chave de coluna única, porque essa é a única coluna da qual Price depende. Por exemplo, podemos usar a Tabela 3 para armazenar o Preço.
Se o preço de um produto fosse diferente com base na sua cor, a quarta tabela estaria na segunda forma normal, uma vez que o preço dependeria de ambas as partes da chave: o ProductID e o Color.
Terceira forma normal
A terceira forma normal é tipicamente o objetivo para a maioria dos bancos de dados OLTP. A terceira forma normal tem as seguintes especificações, para além das exigidas pela segunda forma normal:
- Todas as colunas não-chave não dependem transitoriamente da chave primária.
A relação transitiva implica que uma coluna numa tabela está relacionada com outras colunas, através de uma segunda coluna. Dependência significa que uma coluna pode derivar seu valor de outra, como resultado de uma dependência. Por exemplo, a sua idade pode ser determinada a partir da sua data de nascimento, tornando a sua idade dependente da sua data de nascimento. Consulte novamente a terceira tabela, ProductInfo. Esta tabela está na segunda forma normal, mas não na terceira. A coluna ShortLocation depende da coluna ProductionCountry, que não é a chave. Como a segunda forma normal, violar a terceira forma normal pode levar a anomalias de atualização. Acabaríamos com dados inconsistentes se atualizássemos o ShortLocation em uma linha, mas não o atualizássemos em todas as linhas onde esse local ocorreu. Para evitar isso, poderíamos criar uma tabela separada para armazenar nomes de países/regiões e seus formulários abreviados.
Desnormalização
Embora a terceira forma normal seja teoricamente desejável, nem sempre é possível para todos os dados. Além disso, um banco de dados normalizado nem sempre oferece o melhor desempenho. Os dados normalizados frequentemente requerem várias operações de junção para obter todos os dados necessários retornados em uma única consulta. Há uma compensação entre normalizar dados quando o número de junções necessárias para retornar resultados de consulta tem alta utilização da CPU e dados desnormalizados que têm menos junções e menos CPU necessária, mas abre a possibilidade de anomalias de atualização.
Nota
Dados desnormalizados não são o mesmo que dados não normalizados. Para a desnormalização, começamos projetando tabelas que são normalizadas. Em seguida, podemos adicionar colunas adicionais a algumas tabelas para reduzir o número de junções necessárias, mas ao fazê-lo, estamos cientes das possíveis anomalias de atualização. Em seguida, certificamo-nos de que temos gatilhos ou outros tipos de processamento que garantirão que, quando realizarmos uma atualização, todos os dados duplicados também sejam atualizados.
Dados desnormalizados podem ser mais eficientes para consulta, especialmente para cargas de trabalho pesadas de leitura, como um data warehouse. Nesses casos, ter colunas extras pode oferecer melhores padrões de consulta e/ou consultas mais simplistas.
Esquema em estrela
Enquanto a maioria da normalização é destinada a cargas de trabalho OLTP, os data warehouses têm sua própria estrutura de modelagem, que geralmente é um modelo desnormalizado . Esse design usa tabelas de fatos, que registram medidas ou métricas para eventos específicos, como uma venda, e as une a tabelas de dimensão, que são menores em termos de contagem de linhas, mas podem ter um grande número de colunas para descrever os dados de fato. Alguns exemplos de dimensões incluiriam inventário, tempo e/ou geografia. Esse padrão de design é usado para tornar o banco de dados mais fácil de consultar e oferecer ganhos de desempenho para cargas de trabalho de leitura.
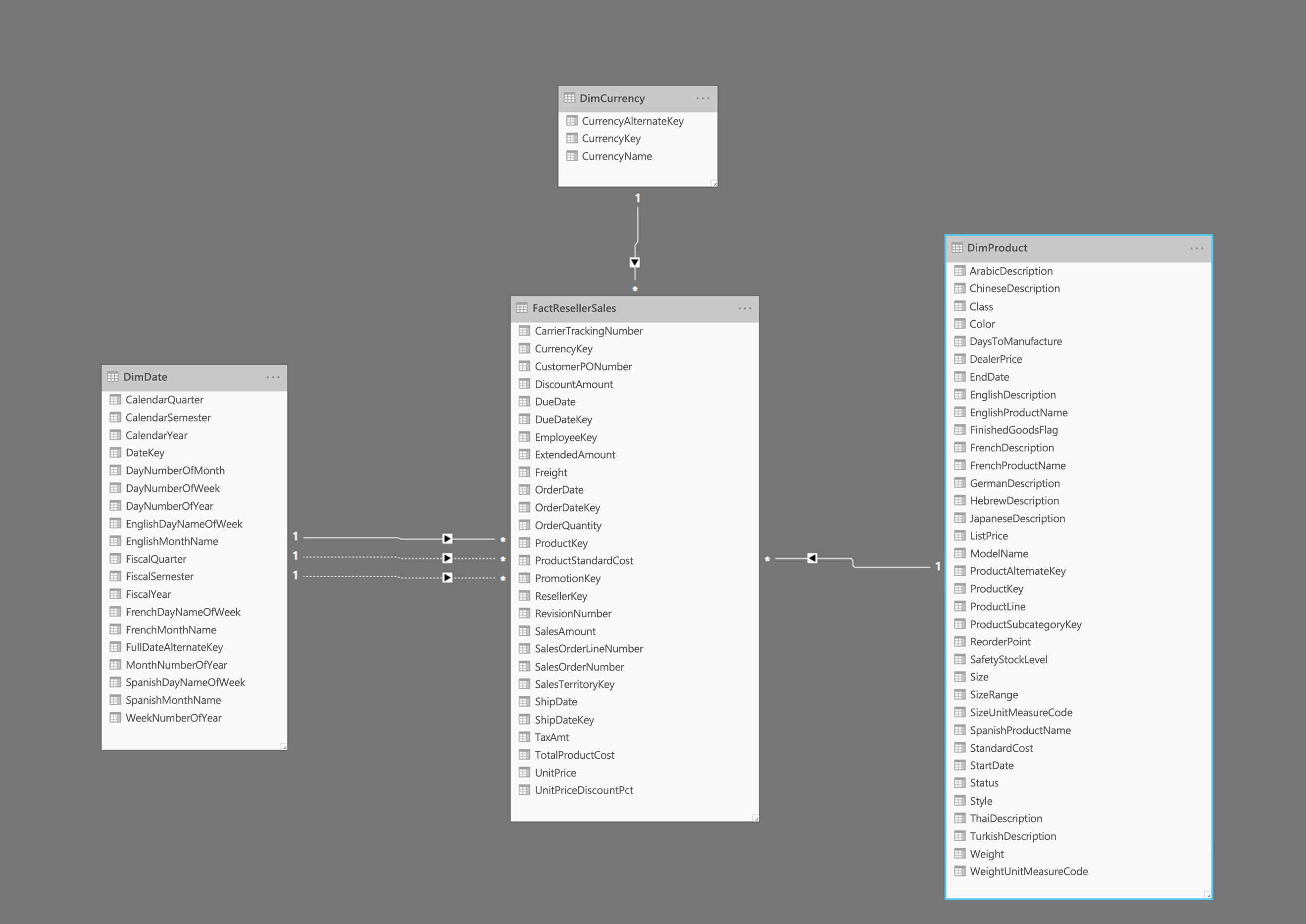
A imagem acima mostra um exemplo de um esquema em estrela, incluindo uma tabela de fatos FactResellerSales e dimensões para data, moeda e produtos. A tabela de fatos contém dados relacionados às transações de vendas, e as dimensões contêm apenas dados relacionados a um elemento específico dos dados de vendas. Por exemplo, a tabela FactResellerSales contém apenas uma ProductKey para indicar qual produto foi vendido. Todos os detalhes sobre cada produto são armazenados na tabela DimProduct e relacionados à tabela de fatos com a coluna ProductKey .
Relacionado ao design de esquema em estrela está um esquema de floco de neve, que usa um conjunto de tabelas mais normalizadas para uma única entidade comercial. A imagem a seguir mostra um exemplo de uma única dimensão para um esquema de floco de neve. A dimensão Produtos é normalizada e armazenada em três tabelas chamadas DimProductCategory, DimProductSubcategory e DimProduct.
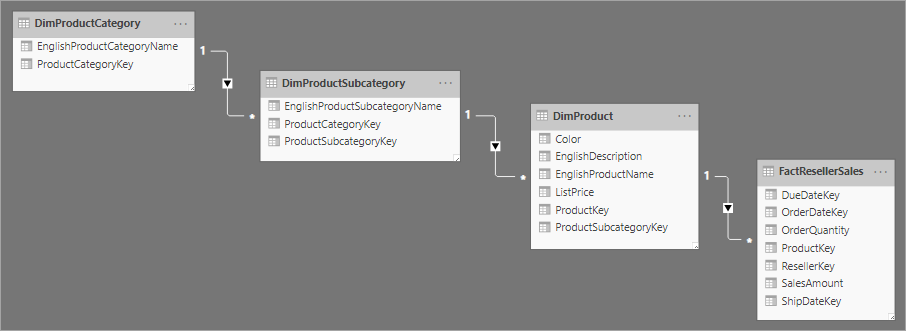
A principal diferença entre os esquemas de estrela e floco de neve é que as dimensões em um esquema de flocos de neve são normalizadas para reduzir a redunância, o que economiza espaço de armazenamento. A contrapartida é que suas consultas exigem mais junções, o que pode aumentar sua complexidade e diminuir o desempenho.