Melhorar o desempenho de um modelo linguístico
Depois de implantar um modelo em um ponto de extremidade, você pode interagir com o modelo para explorar como ele se comporta. Quando você deseja que o modelo seja personalizado para o seu caso de uso, existem várias estratégias de otimização que você pode aplicar para melhorar o desempenho do modelo. Vamos explorar as várias estratégias.
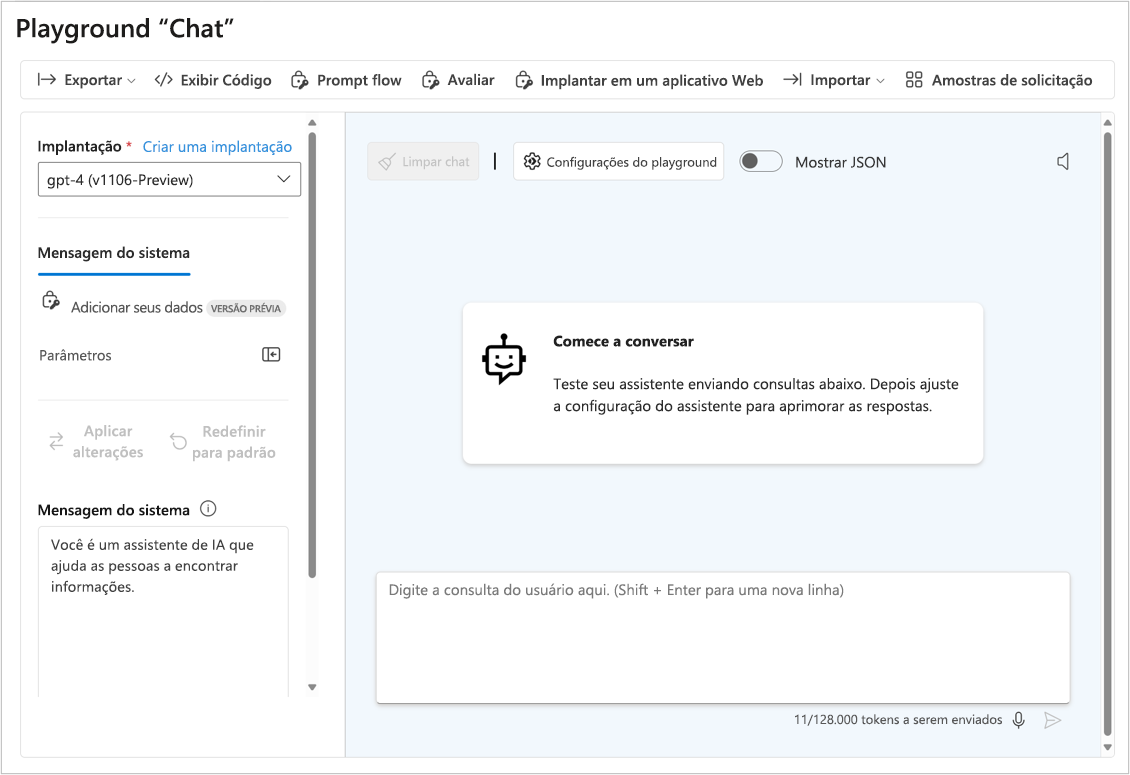
Bate-papo com uma modelo no playground
Você pode usar sua linguagem de codificação preferida para fazer uma chamada de API para o ponto de extremidade do seu modelo ou pode conversar com o modelo diretamente no playground do portal do Azure AI Foundry. O playground de bate-papo é uma maneira rápida e fácil de experimentar e melhorar o desempenho do seu modelo.
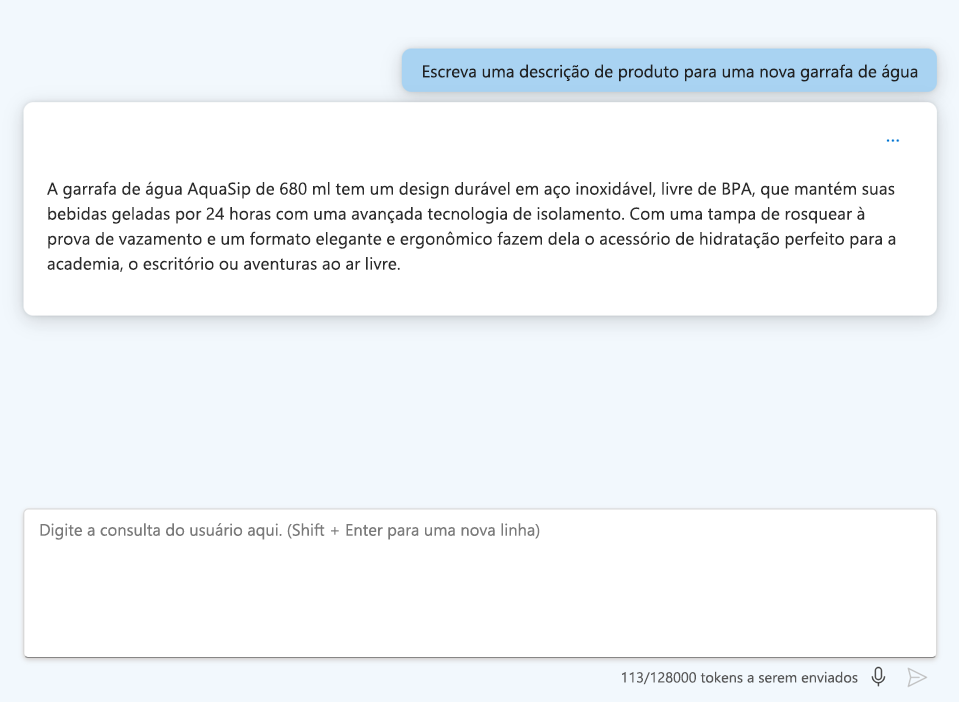
A qualidade das perguntas que envia para o modelo linguístico influencia diretamente a qualidade das respostas que recebe. Você pode construir cuidadosamente sua pergunta, ou solicitar, para receber respostas melhores e mais interessantes. O processo de projetar e otimizar prompts para melhorar o desempenho do modelo também é conhecido como engenharia de prompt. Quando um usuário final fornece prompts relevantes, específicos, inequívocos e bem estruturados, o modelo pode entender melhor o contexto e gerar respostas mais precisas.
Aplicar engenharia imediata
Quando você está conversando com o modelo no playground, você pode aplicar várias técnicas de engenharia de prompt para explorar se ele melhora a saída do modelo.
Vamos explorar algumas técnicas que um usuário final pode usar para aplicar a engenharia de prompt:
- Forneça instruções claras: Seja específico sobre a saída desejada.
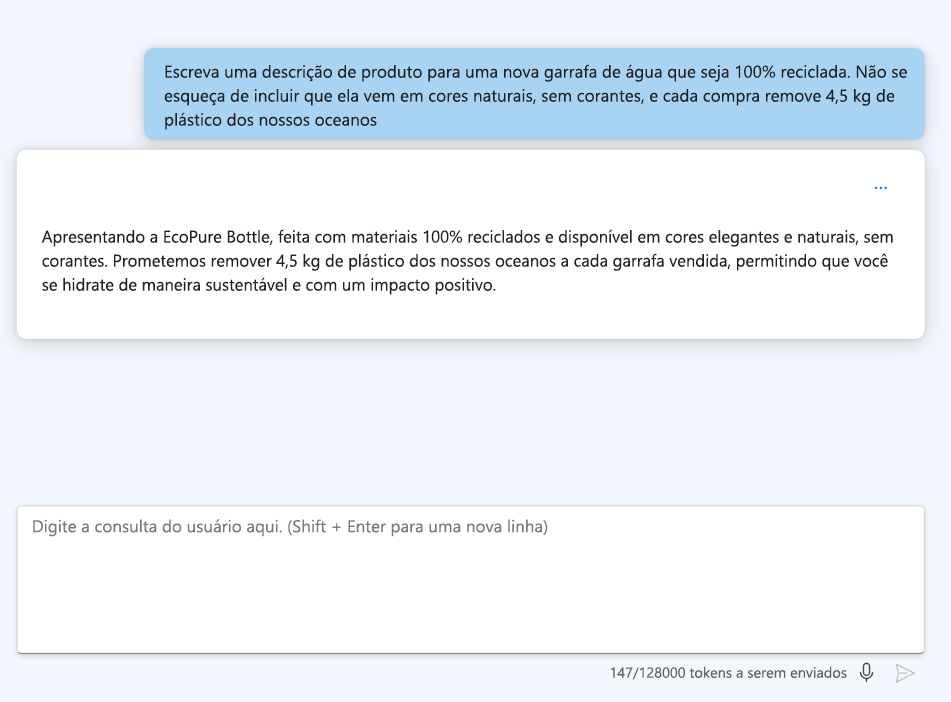
- Formate suas instruções: use cabeçalhos e delineadores para facilitar a leitura da pergunta.
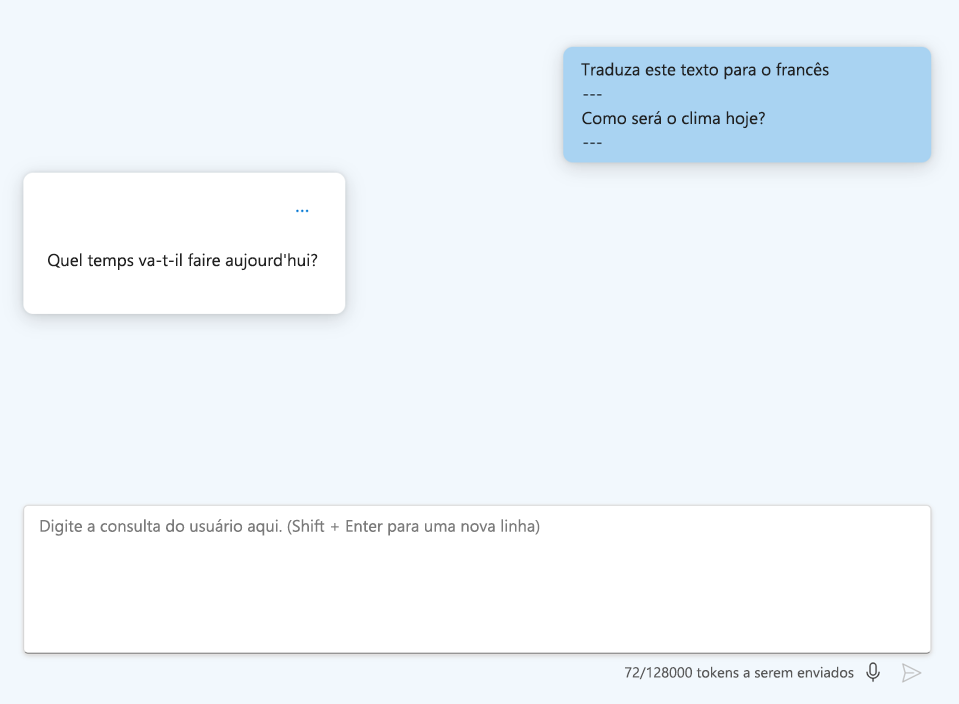
- Use pistas: forneça palavras-chave ou indicadores de como o modelo deve iniciar sua resposta, como uma linguagem de codificação específica.
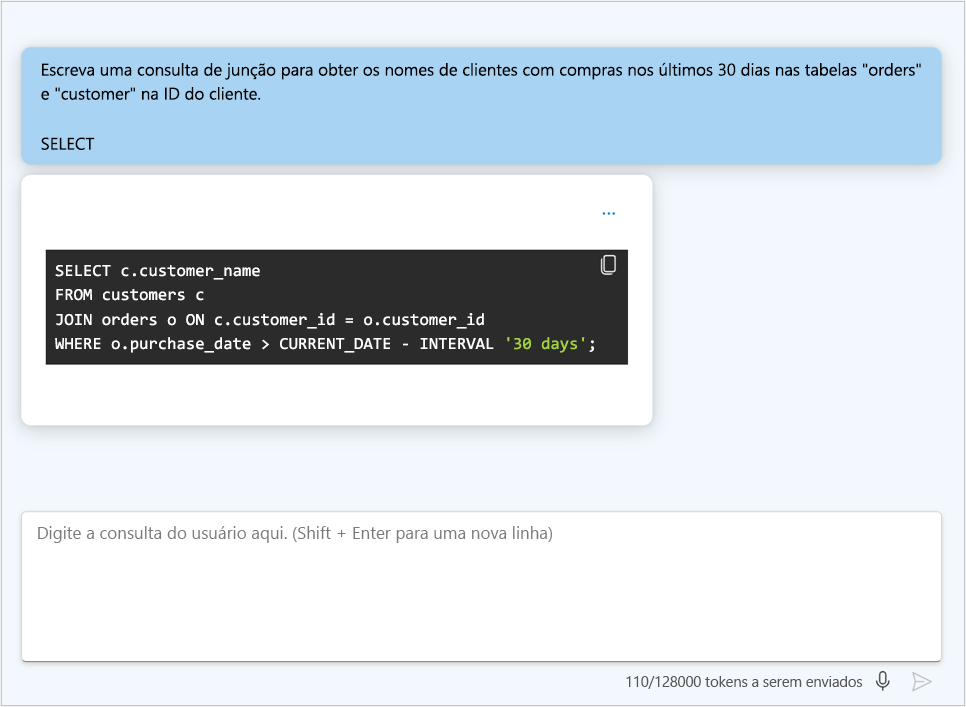
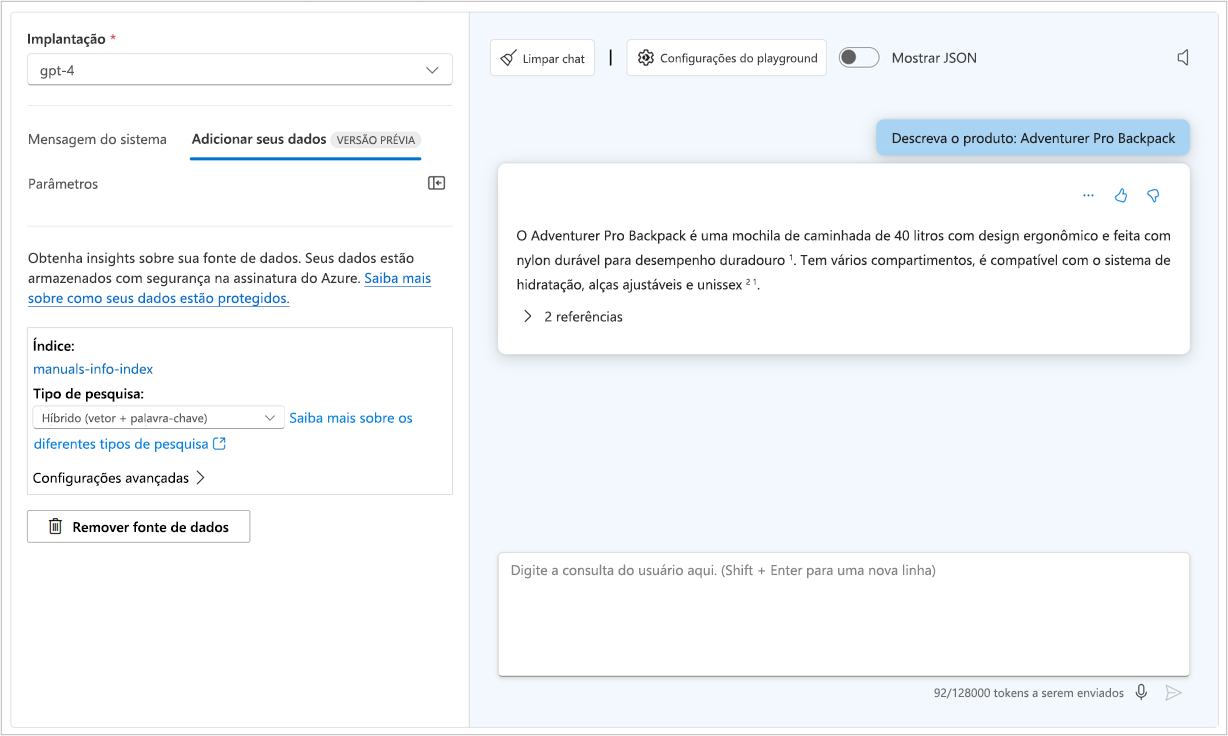
Atualizar a mensagem do sistema
No playground de bate-papo, você pode visualizar o JSON da sua conversa atual selecionando Mostrar JSON:
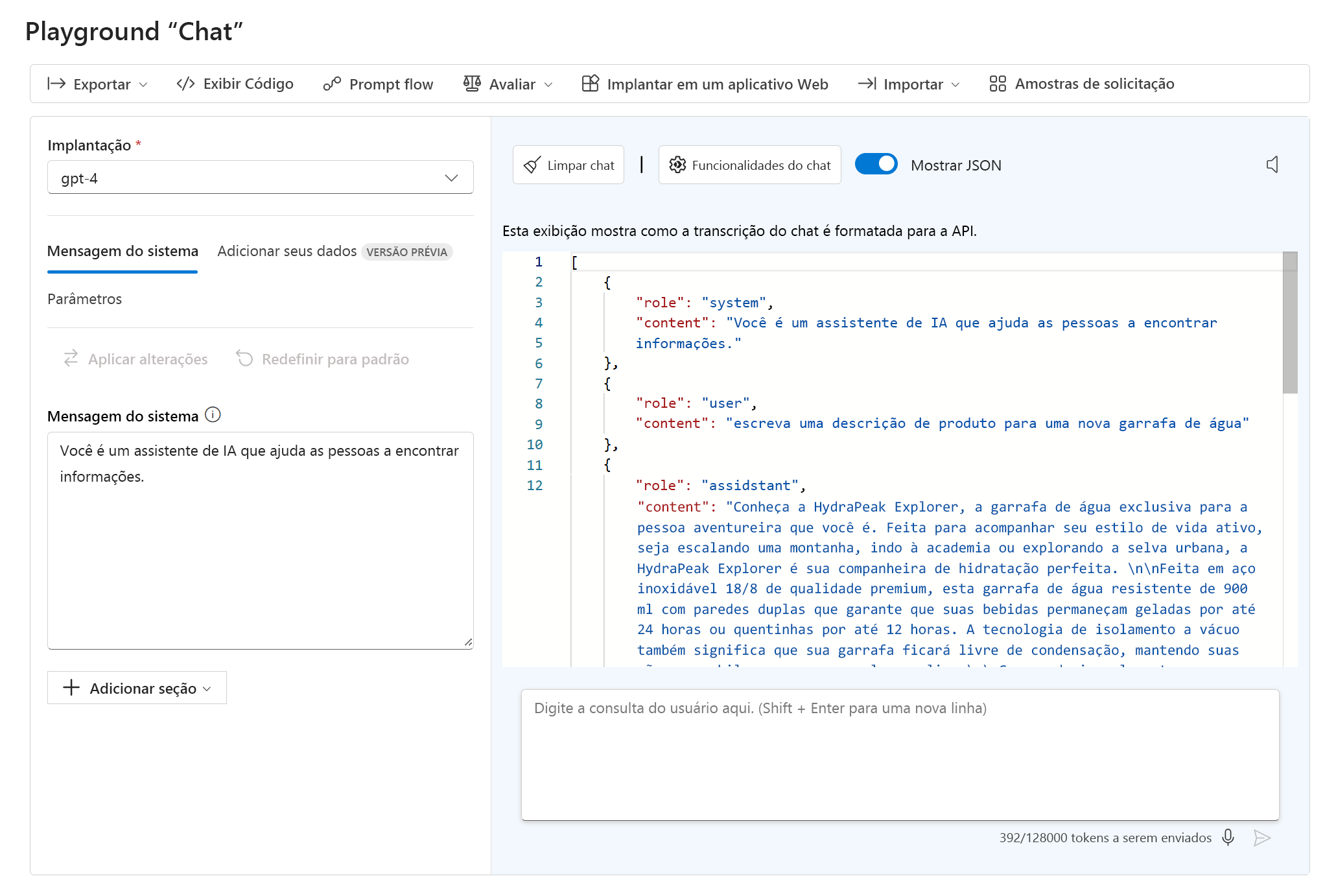
O JSON mostrado é os dados de entrada para o ponto de extremidade do modelo toda vez que você envia uma nova mensagem. A mensagem do sistema é sempre parte dos dados de entrada. Embora não seja visível para os usuários finais, a mensagem do sistema permite que você, como desenvolvedor, personalize o comportamento do modelo, fornecendo instruções para seu comportamento.
Algumas técnicas comuns de engenharia de prompt para aplicar como um desenvolvedor atualizando a mensagem do sistema são:
- Use uma foto ou poucas fotos: forneça um ou mais exemplos para ajudar o modelo a identificar um padrão desejado. Você pode adicionar uma seção à mensagem do sistema para adicionar um ou mais exemplos.
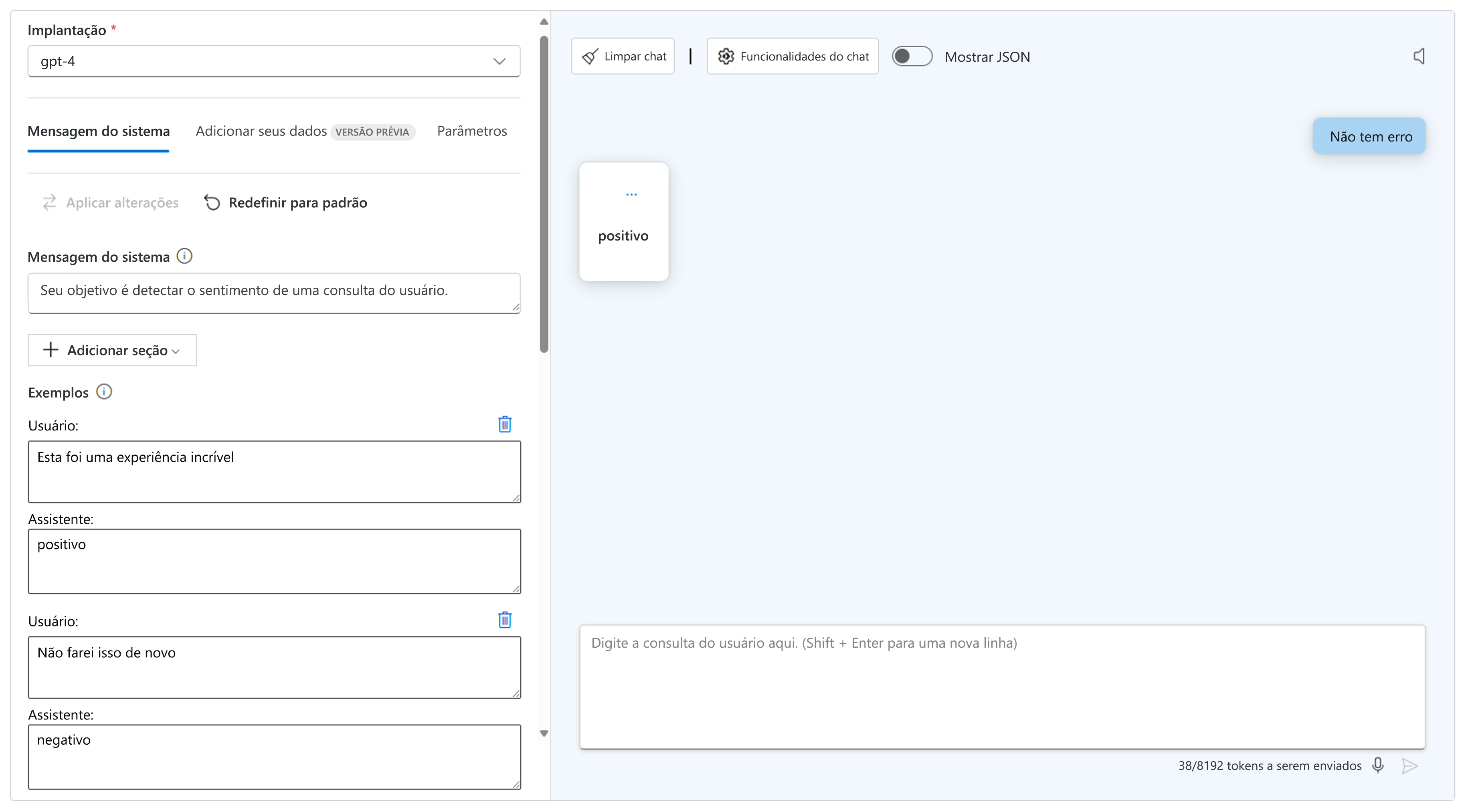
- Use a cadeia de pensamento: guie o modelo para raciocinar passo a passo, instruindo-o a pensar na tarefa.
- Adicionar contexto: melhore a precisão do modelo fornecendo informações contextuais ou básicas relevantes para a tarefa. Você pode fornecer contexto por meio de dados de aterramento fornecidos no prompt do usuário ou conectando sua própria fonte de dados.
Aplicar estratégias de otimização de modelo
Como desenvolvedor, você também pode aplicar outras estratégias de otimização para melhorar o desempenho do modelo, sem ter que pedir ao usuário final para escrever prompts específicos. Ao lado da engenharia imediata, a estratégia escolhida depende dos seus requisitos:
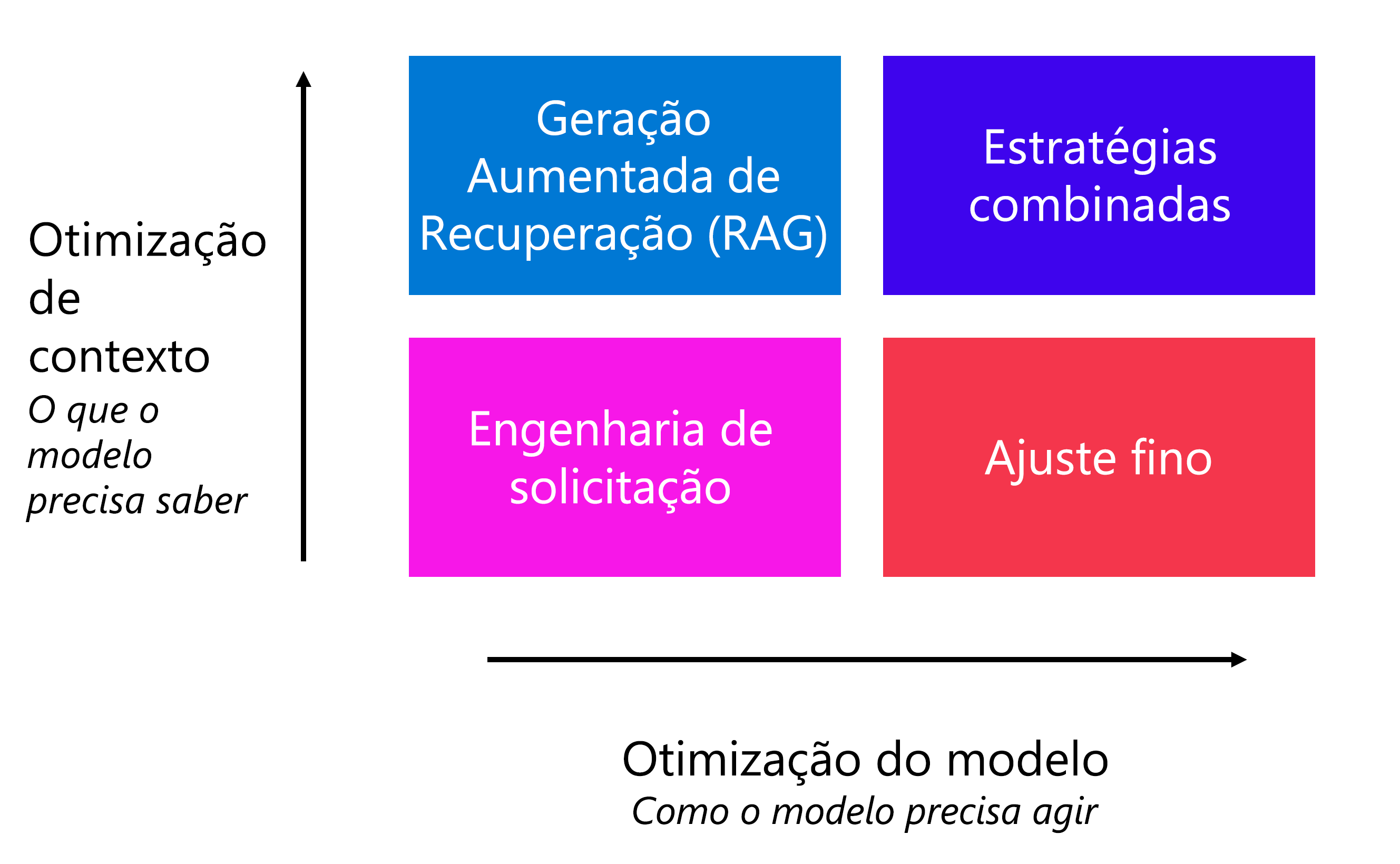
- Otimizar para o contexto: quando o modelo não tem conhecimento contextual e você deseja maximizar a precisão das respostas.
- Otimizar o modelo: quando você quiser melhorar o formato, o estilo ou a fala da resposta maximizando a consistência do comportamento.
Para otimizar o contexto, você pode aplicar um padrão de Geração Aumentada de Recuperação (RAG). Com o RAG, você aterra seus dados primeiro recuperando o contexto de uma fonte de dados antes de gerar uma resposta. Por exemplo, você quer que os clientes façam perguntas sobre os hotéis que você está oferecendo em seu catálogo de reservas de viagens.
Quando desejar que o modelo responda em um estilo ou formato específico, você pode instruir o modelo a fazê-lo adicionando diretrizes na mensagem do sistema. Quando notar que o comportamento do modelo não é consistente, você pode impor ainda mais a consistência no comportamento ajustando um modelo. Com o ajuste fino, você treina um modelo de linguagem base em um conjunto de dados antes de integrá-lo ao seu aplicativo.
Você também pode usar uma combinação de estratégias de otimização, como RAG e um modelo ajustado, para melhorar seu aplicativo de linguagem.