Compreender a arquitetura do transformador usada para processamento de linguagem natural (NLP)
O mais recente avanço no Processamento de Linguagem Natural (PNL) deve-se ao desenvolvimento da arquitetura Transformer .
Os transformadores foram introduzidos no artigo Attention is all you need por Vaswani, et al., de 2017. A arquitetura Transformer fornece uma alternativa às Redes Neurais Recorrentes (RNNS) para fazer PNL. Enquanto os RNNs são intensivos em computação, uma vez que processam palavras sequencialmente, os Transformers não processam as palavras sequencialmente, mas processam cada palavra independentemente em paralelo usando a atenção.
A posição de uma palavra e a ordem das palavras numa frase são importantes para compreender o significado de um texto. Para incluir essas informações, sem ter que processar texto sequencialmente, os Transformers usam codificação posicional.
Compreender a codificação posicional
Antes do Transformers, os modelos de linguagem usavam incorporações de palavras para codificar texto em vetores. Na arquitetura do Transformer, a codificação posicional é usada para codificar texto em vetores. A codificação posicional é a soma de vetores de incorporação de palavras e vetores posicionais. Ao fazer isso, o texto codificado inclui informações sobre o significado e a posição de uma palavra em uma frase.
Para codificar a posição de uma palavra em uma frase, você pode usar um único número para representar o valor do índice. Por exemplo:
| Token | Valor do índice |
|---|---|
| O | 0 |
| Trabalho | 5 |
| de | 2 |
| Guilherme | 3 |
| Shakespeare | 4 |
| Inspirado | 5 |
| muitos | 6 |
| filmes | 7 |
| ... | ... |
Quanto mais longo for um texto ou uma sequência, maiores poderão ser os valores do índice. Embora o uso de valores únicos para cada posição em um texto seja uma abordagem simples, os valores não teriam significado e os valores crescentes podem criar instabilidade durante o treinamento do modelo.
A solução proposta na Atenção é tudo o que você precisa papel usa funções seno e cosseno, onde pos é a posição e i é a dimensão:
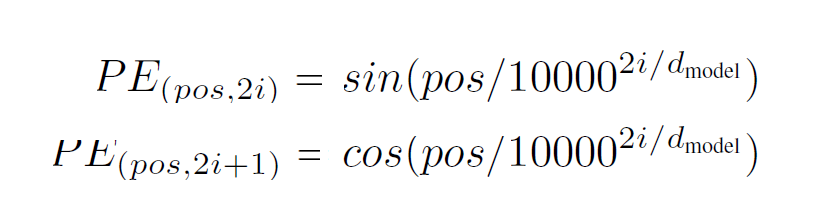
Ao usar essas funções periódicas juntas para criar, você pode criar vetores exclusivos para cada posição. Como resultado, os valores estão dentro de um intervalo e o índice não fica maior quando um texto maior é codificado. Além disso, esses vetores posicionais tornam mais fácil para o modelo calcular e comparar as posições de diferentes palavras em uma frase umas contra as outras.
Compreender a atenção multi-cabeça
A técnica mais importante usada por Transformers para processar texto é o uso da atenção em vez da recorrência.
A atenção (também referida como auto-atenção ou intra-atenção ) é um mecanismo usado para mapear novas informações para informações aprendidas, a fim de entender o que as novas informações implicam.
Os transformadores usam uma função de atenção, onde uma nova palavra é codificada (usando codificação posicional) e representada como uma consulta. A saída de uma palavra codificada é uma chave com um valor associado.
Para ilustrar as três variáveis que são usadas pela função de atenção: a consulta, as teclas e os valores, vamos explorar um exemplo simplificado. Imagine codificar a frase Vincent van Gogh is a painter, known for his stunning and emotionally expressive artworks. Ao codificar a consulta Vincent van Gogh, a saída pode ser Vincent van Gogh como a chave com painter o valor associado. A arquitetura armazena chaves e valores em uma tabela, que pode ser usada para decodificação futura:
| Chaves | Valores |
|---|---|
| Vicente Van Gogh | Pincel de Formatação |
| Guilherme Shakespeare | Playwright |
| Charles Dickens | Redator |
Sempre que uma nova frase é apresentada como Shakespeare's work has influenced many movies, mostly thanks to his work as a .... O modelo pode completar a frase tomando Shakespeare como consulta e localizando-a na tabela de chaves e valores. Shakespeare A consulta está mais próxima William Shakespeare da chave e, portanto, o valor playwright associado é apresentado como a saída.
Usando o produto ponto dimensionado para calcular a função de atenção
Para calcular a função de atenção, a consulta, as chaves e os valores são todos codificados em vetores. Em seguida, a função de atenção calcula o produto ponto dimensionado entre o vetor de consulta e os vetores de chaves.
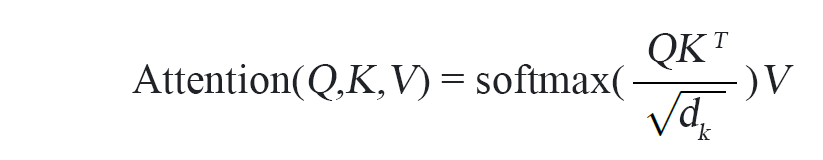
O ponto-produto calcula o ângulo entre vetores que representam tokens, com o produto sendo maior quando os vetores estão mais alinhados.
A função softmax é usada dentro da função de atenção, sobre o ponto-produto escalado dos vetores, para criar uma distribuição de probabilidade com possíveis resultados. Em outras palavras, a saída da função softmax inclui quais teclas estão mais próximas da consulta. A chave com a maior probabilidade é então selecionada, e o valor associado é a saída da função de atenção.
A arquitetura Transformer usa atenção multi-cabeça, o que significa que os tokens são processados pela função de atenção várias vezes em paralelo. Ao fazer isso, uma palavra ou frase pode ser processada várias vezes, de várias maneiras, para extrair diferentes tipos de informações da frase.
Explore a arquitetura do Transformer
No papel Atenção é tudo o que você precisa , a arquitetura proposta do Transformer é modelada como:
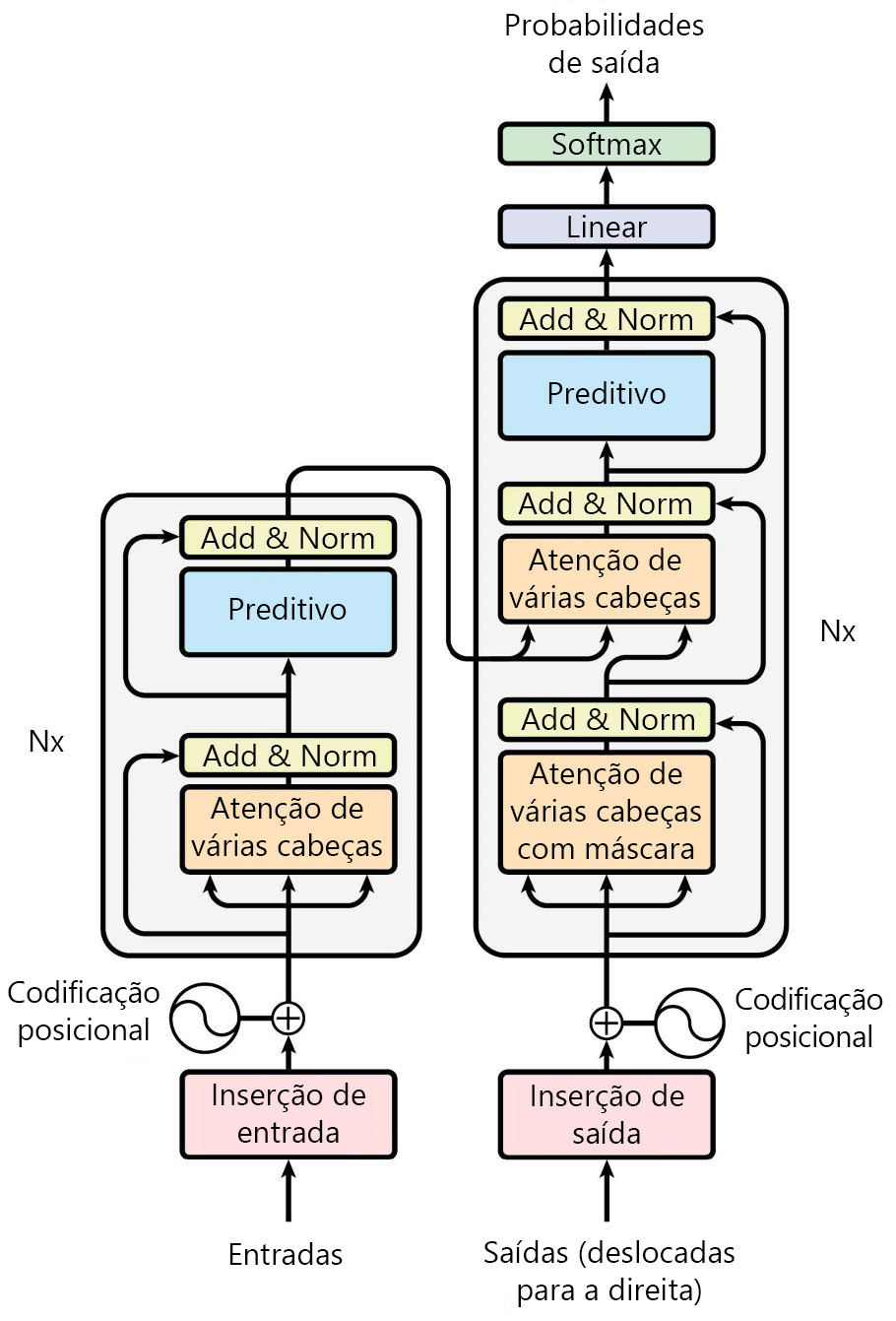
Existem dois componentes principais na arquitetura original do Transformer:
- O codificador: Responsável por processar a sequência de entrada e criar uma representação que captura o contexto de cada token.
- O decodificador: gera a sequência de saída observando a representação do codificador e prevendo o próximo token na sequência.
As inovações mais importantes apresentadas na arquitetura do Transformer foram a codificação posicional e a atenção multi-cabeça. Uma representação simplificada da arquitetura, com foco nesses dois componentes, pode se parecer com:
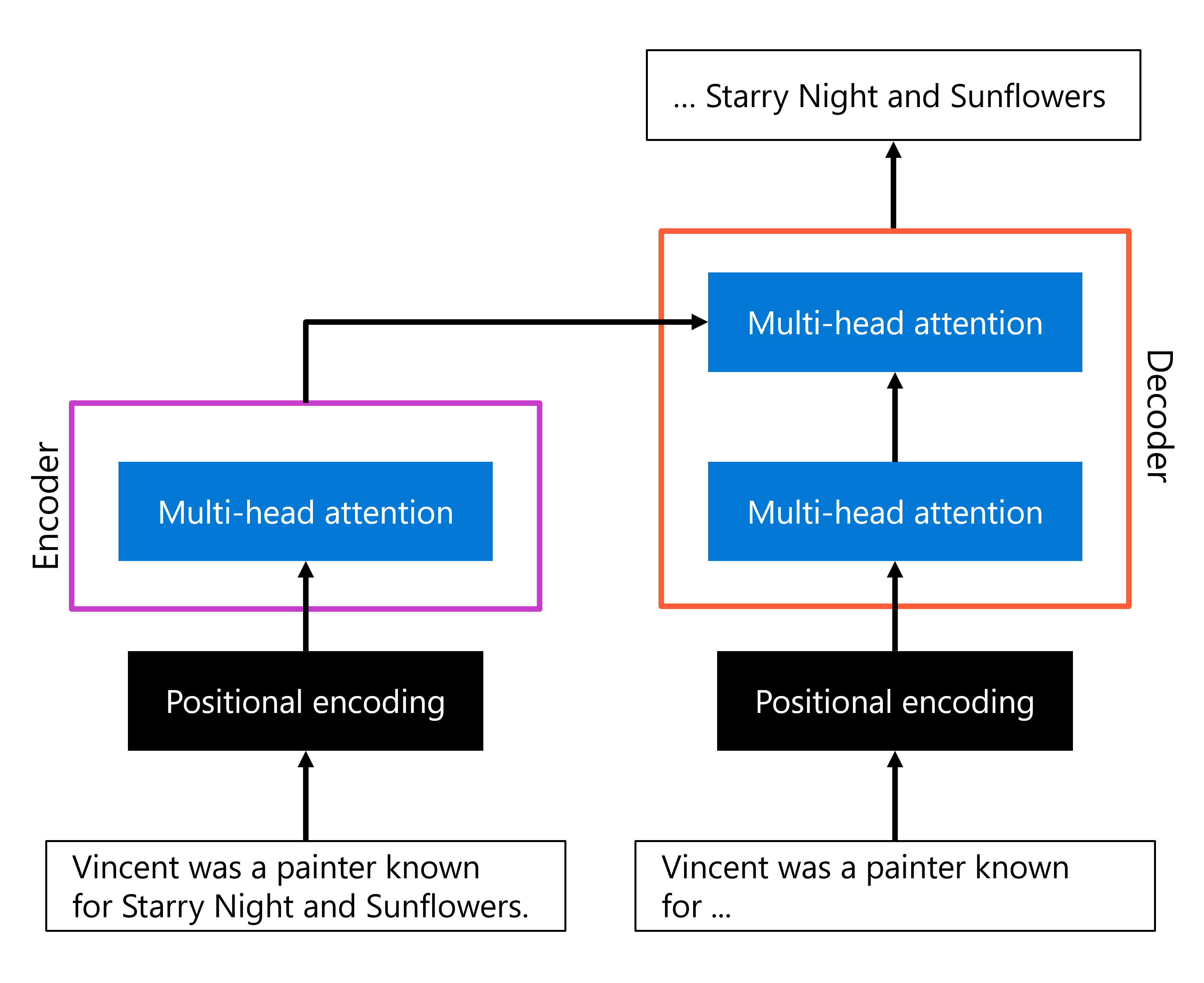
- Na camada codificadora, uma sequência de entrada é codificada com codificação posicional, após a qual a atenção de várias cabeças é usada para criar uma representação do texto.
- Na camada decodificadora, uma sequência de saída (incompleta) é codificada de maneira semelhante, usando primeiro a codificação posicional e, em seguida, a atenção de várias cabeças. Em seguida, o mecanismo de atenção multi-head é usado uma segunda vez dentro do decodificador para combinar a saída do codificador e a saída da sequência de saída codificada que foi passada como entrada para a parte do decodificador. Como resultado, a saída pode ser gerada.
A arquitetura Transformer introduziu conceitos que melhoraram drasticamente a capacidade de um modelo de entender e gerar texto. Diferentes modelos foram treinados usando adaptações da arquitetura do Transformer para otimizar para tarefas específicas de PNL.