Compreender as técnicas de aprendizagem profunda utilizadas para o processamento de linguagem natural (PNL)
As técnicas estatísticas eram relativamente boas em tarefas de Processamento de Linguagem Natural (PNL), como classificação de texto. Para tarefas como a tradução, ainda havia muito a melhorar.
Uma técnica recente que tem avançado o campo do Processamento de Linguagem Natural (PNL) para tarefas como a tradução é o deep learning.
Quando você quer traduzir texto, você não deve apenas traduzir cada palavra para outro idioma. Você deve se lembrar de serviços de tradução de anos atrás que traduziam frases de forma muito literal, muitas vezes resultando em resultados interessantes. Em vez disso, você deseja que um modelo de linguagem compreenda o significado (ou semântica) de um texto e use essas informações para criar uma frase gramaticalmente correta no idioma de destino.
Compreender a incorporação de palavras
Um dos conceitos-chave introduzidos pela aplicação de técnicas de aprendizagem profunda à PNL é a incorporação de palavras. A incorporação de palavras resolveu o problema de não ser capaz de definir a relação semântica entre palavras.
Antes da incorporação de palavras, um desafio predominante com a PNL era detetar a relação semântica entre as palavras. As incorporações de palavras representam palavras em um espaço vetorial, de modo que a relação entre palavras pode ser facilmente descrita e calculada.
As incorporações de palavras são criadas durante a aprendizagem autosupervisionada. Durante o processo de treinamento, o modelo analisa os padrões de coocorrência de palavras em frases e aprende a representá-las como vetores. Os vetores representam as palavras com coordenadas em um espaço multidimensional. A distância entre palavras pode então ser calculada determinando a distância entre os vetores relativos, descrevendo a relação semântica entre palavras.
Imagine que você treina um modelo em um grande corpus de dados de texto. Durante o processo de treinamento, o modelo descobre que as palavras e car são frequentemente usadas nos mesmos padrões de palavrasbike. Ao lado de encontrar e car no mesmo texto, você também pode encontrar bike cada um deles para ser usado ao descrever coisas semelhantes. Por exemplo, alguém pode dirigir um ou um , ou comprar um ou um bike carbike car em uma loja.
O modelo aprende que as duas palavras são frequentemente encontradas em contextos semelhantes e, portanto, plota os vetores de palavras para bike e car próximos um do outro no espaço vetorial.
Imagine que temos um espaço vetorial tridimensional onde cada dimensão corresponde a uma característica semântica. Neste caso, digamos que as dimensões representam fatores como tipo de veículo, modo de transporte e atividade. Podemos então atribuir vetores hipotéticos às palavras com base em suas relações semânticas:
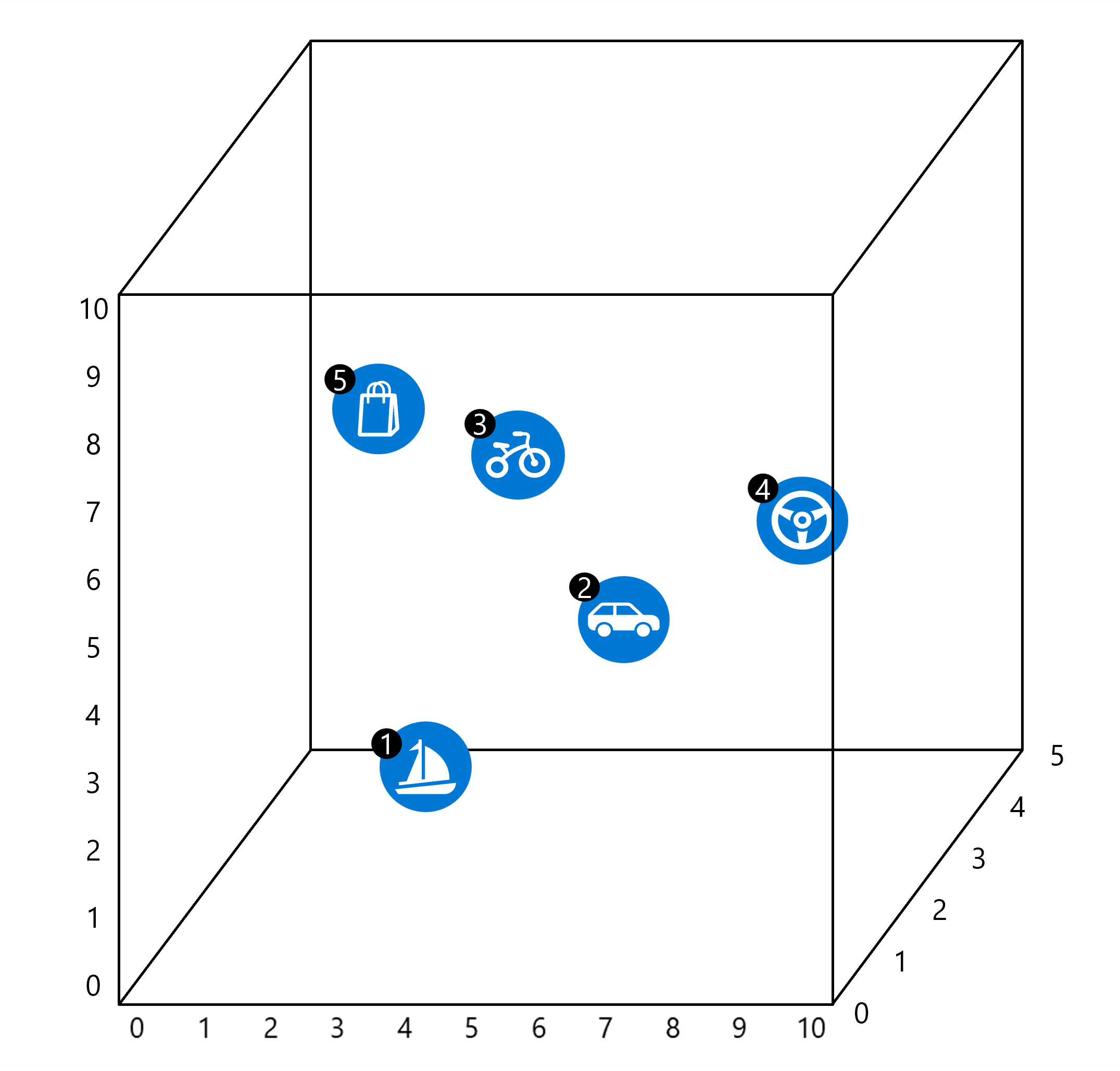
Boat[2, 1, 4] está perto e , refletindo que você pode dirigir um barco e visitar lojas pertodriveshopde corpos de água.Car[7, 5, 1] mais pertobikedo queboatcomo carros e motos são usados em terra e não na água.Bike[6, 8, 0] está mais próximadrivena dimensão da atividade e próximacarda dimensão do tipo de veículo.Drive[8, 4, 3] está próximo de , ebike,carmas longe deshopboatdescrever um tipo diferente de atividade.Shop[1, 3, 5] é obikemais próximo, pois estas palavras são mais comumente usadas juntas.
Nota
No exemplo, um plano tridimensional é usado para descrever incorporações de palavras e espaços vetoriais em termos simples. Os espaços vetoriais são frequentemente planos multidimensionais com vetores que representam uma posição nesse espaço, semelhante às coordenadas em um plano bidimensional.
Embora a incorporação de palavras seja uma ótima abordagem para detetar a relação semântica entre palavras, ela ainda tem seus problemas. Por exemplo, palavras com intenções diferentes gostam love e hate muitas vezes aparecem relacionadas porque são usadas em contexto semelhante. Outro problema era que o modelo usaria apenas uma entrada por palavra, resultando em uma palavra com significados diferentes, como bank ser semanticamente relacionada a uma matriz selvagem de palavras.
Adicionando memória a modelos de PNL
Compreender texto não é apenas compreender palavras individuais, apresentadas isoladamente. As palavras podem diferir em seu significado dependendo do contexto em que são apresentadas. Em outras palavras, a frase em torno de uma palavra importa para o significado da palavra.
Usando RNNs para incluir o contexto de uma palavra
Antes da aprendizagem profunda, incluir o contexto de uma palavra era uma tarefa demasiado complexa e dispendiosa. Um dos primeiros avanços na inclusão do contexto foram as Redes Neurais Recorrentes (RNNs).
Os RNNs consistem em várias etapas sequenciais. Cada etapa leva uma entrada e um estado oculto. Imagine que a entrada em cada etapa seja uma nova palavra. Cada etapa também produz uma saída. O estado oculto pode servir como uma memória da rede, armazenando a saída da etapa anterior e passando-a como entrada para a próxima etapa.
Imagine uma frase como:
Vincent Van Gogh was a painter most known for creating stunning and emotionally expressive artworks, including ...
Para saber que palavra vem a seguir, você precisa lembrar o nome do pintor. A frase precisa ser completada, pois ainda falta a última palavra. Uma palavra ausente ou mascarada em tarefas de PNL geralmente é representada com [MASK]. Usando o token especial [MASK] em uma frase, você pode informar a um modelo de linguagem que ele precisa prever qual é o token ou valor ausente.
Simplificando a frase de exemplo, você pode fornecer a seguinte entrada para um RNN: : Vincent was a painter known for [MASK]

O RNN toma cada token como uma entrada, processa-o e atualiza o estado oculto com uma memória desse token. Quando o próximo token é processado como nova entrada, o estado oculto da etapa anterior é atualizado.
Finalmente, o último token é apresentado como entrada para o modelo, ou seja, o [MASK] token. Indicando que há informações faltando e o modelo precisa prever seu valor. O RNN então usa o estado oculto para prever que a saída deve ser algo como Starry Night

No exemplo, o estado oculto contém as informações Vincent, , , painterise know. Com RNNs, cada um desses tokens é igualmente importante no estado oculto e, portanto, igualmente considerado ao prever a saída.
Os RNNs permitem que o contexto seja incluído ao decifrar o significado de uma palavra em relação à frase completa. No entanto, à medida que o estado oculto de um RNN é atualizado com cada token, a informação relevante real, ou sinal, pode ser perdida.
No exemplo fornecido, o nome de Vincent Van Gogh está no início da frase, enquanto a máscara está no final. Na etapa final, quando a máscara é apresentada como entrada, o estado oculto pode conter uma grande quantidade de informações que são irrelevantes para prever a saída da máscara. Como o estado oculto tem um tamanho limitado, as informações relevantes podem até ser excluídas para abrir espaço para informações novas e mais recentes.
Quando lemos esta frase, sabemos que apenas certas palavras são essenciais para prever a última palavra. Um RNN, no entanto, inclui todas as informações (relevantes e irrelevantes) em um estado oculto. Como resultado, as informações relevantes podem se tornar um sinal fraco no estado oculto, o que significa que podem ser ignoradas porque há muitas outras informações irrelevantes influenciando o modelo.
Melhorando RNNs com memória de longo prazo
Uma solução para o problema do sinal fraco com RNNs é um novo tipo de RNN: Long Short-Term Memory (LSTM). O LSTM é capaz de processar dados sequenciais mantendo um estado oculto que é atualizado em cada etapa. Com o LSTM, o modelo pode decidir o que lembrar e o que esquecer. Ao fazer isso, o contexto que não é relevante ou não fornece informações valiosas pode ser ignorado, e sinais importantes podem persistir por mais tempo.