Visualizar gráficos em blocos de anotações
A visualização de dados é um aspeto fundamental da exploração de dados. Envolve a apresentação de dados num formato gráfico, tornando os dados complexos mais compreensíveis e utilizáveis.
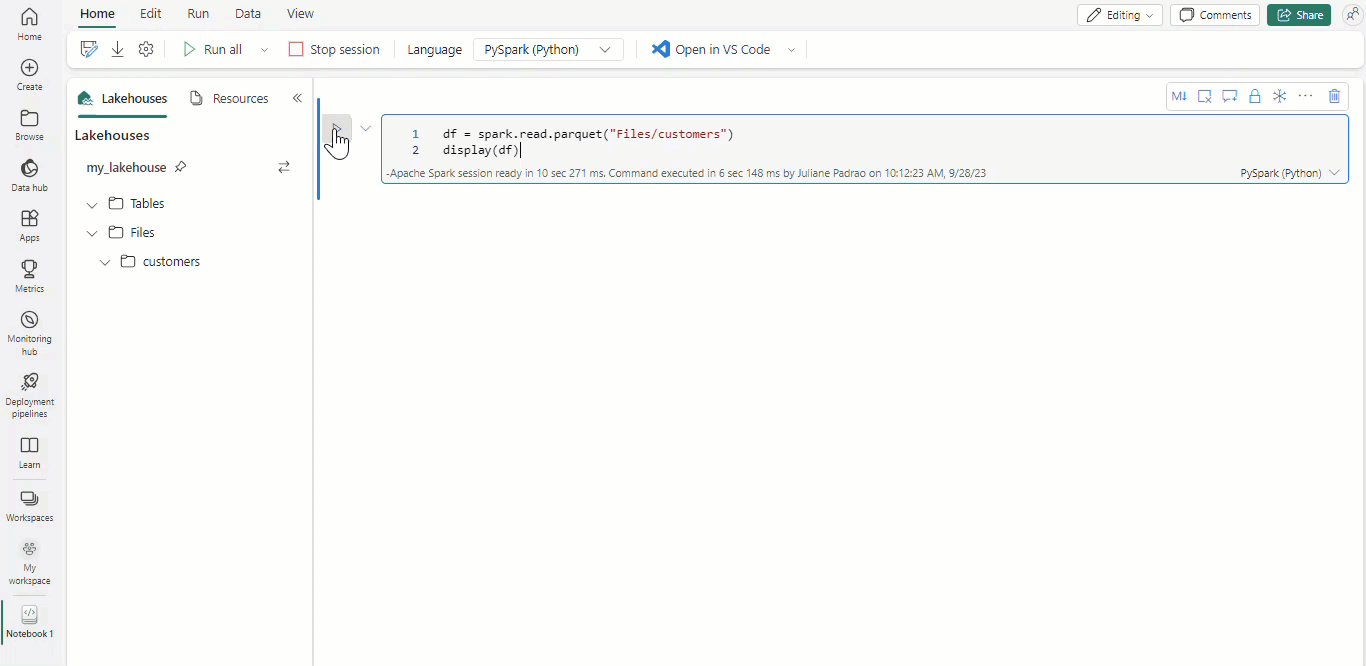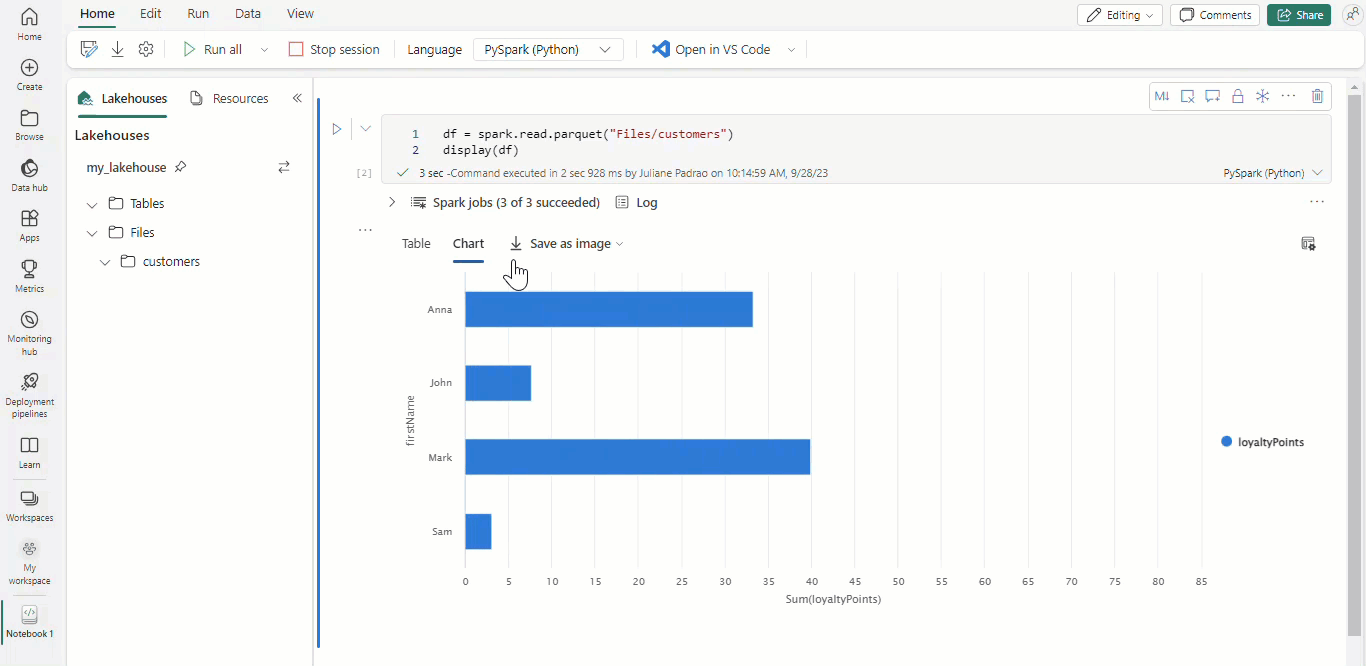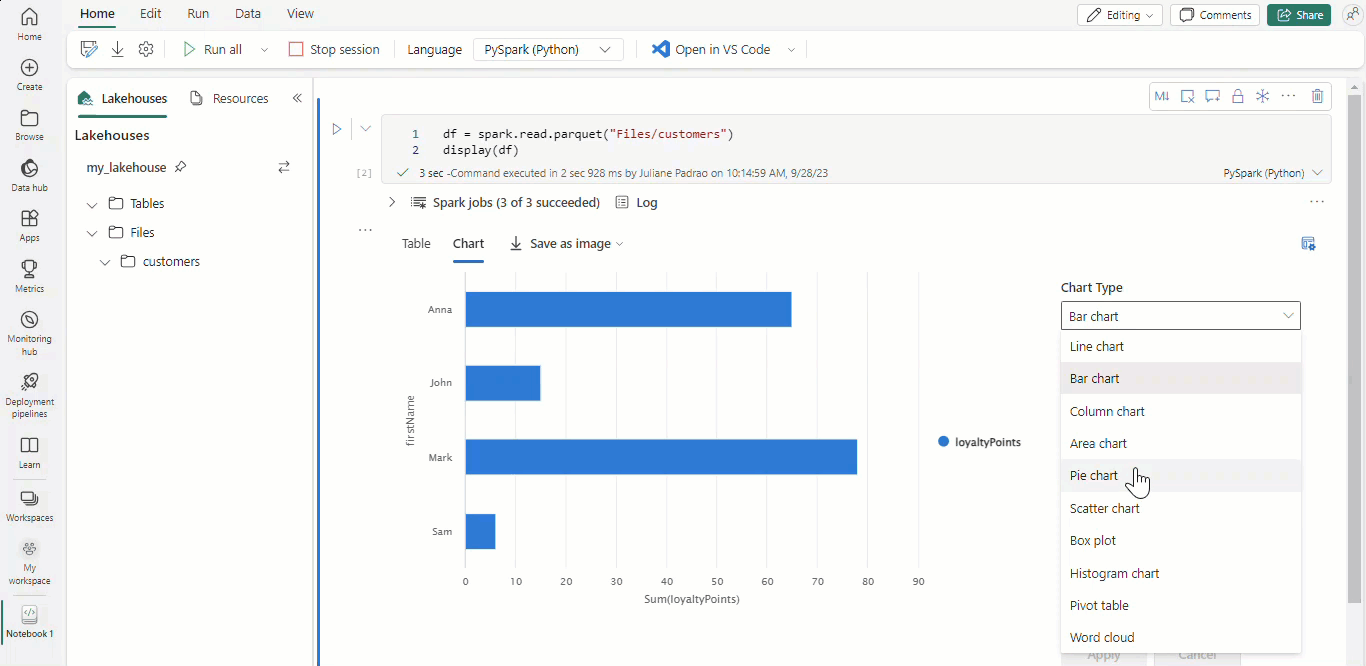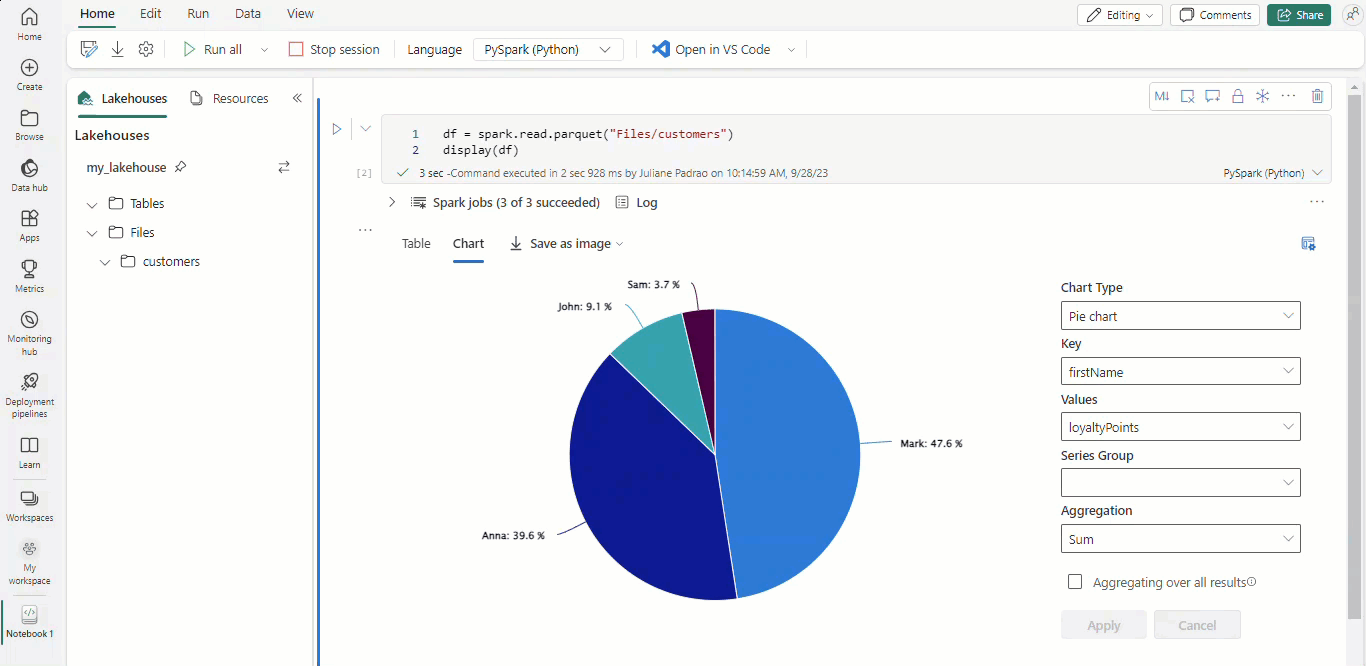
Com os notebooks Microsoft Fabric e os dataframes Apache Spark, seus resultados tabulares são apresentados automaticamente como gráficos sem a necessidade de qualquer codificação extra.
Gorjeta
Bibliotecas de código aberto como matplotlib e plotly, entre outras, também podem ser usadas para melhorar a experiência de exploração de dados.
Compreender variáveis categóricas e numéricas
Para variáveis categóricas, é importante entender as diferentes categorias ou níveis na variável. Isso envolve identificar quantas observações existem em cada categoria, o que é referido como contagens ou frequências. Além disso, entender qual proporção ou porcentagem das observações cada categoria representa é crucial.
Quando se trata de variáveis numéricas, vários aspetos precisam ser considerados. A tendência central da variável, que pode ser a média, mediana ou modo, fornece um resumo da variável.
Medidas de dispersão, como o intervalo, intervalo interquartílico (IQR), desvio padrão ou variância, fornecem informações sobre a dispersão da variável. Por fim, entender a distribuição da variável é fundamental. Isso envolve determinar se a variável é normalmente distribuída ou segue alguma outra distribuição e identificar quaisquer valores atípicos.
Estas são muitas vezes referidas como estatísticas sumárias de variáveis numéricas e categóricas.
Estatísticas resumidas
As estatísticas de resumo estão disponíveis para dataframes do Apache Spark quando você usa o parâmetro summary=True.
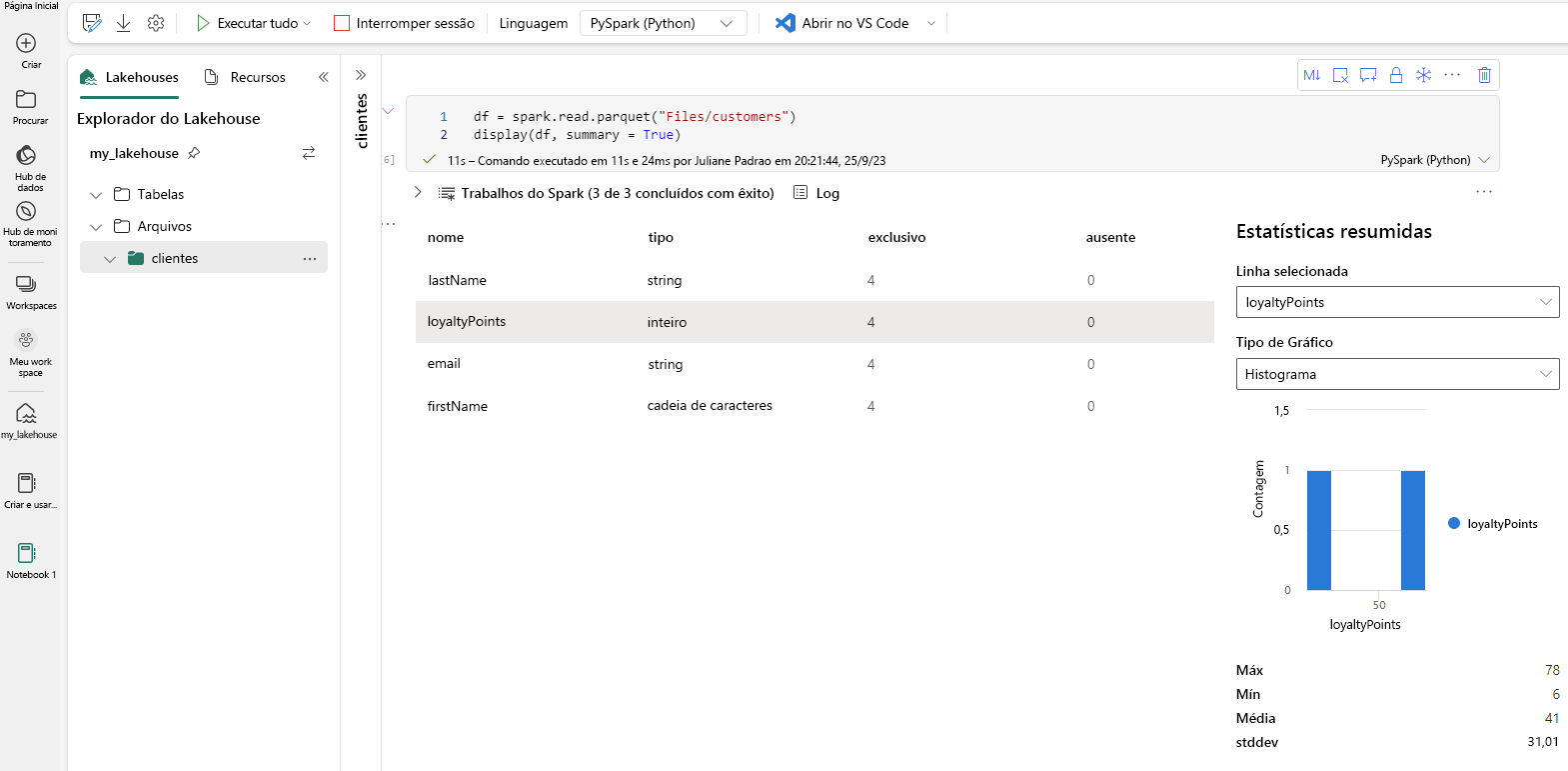
Como alternativa, você pode gerar as estatísticas de resumo usando Python.
import pandas as pd
df = pd.DataFrame({
'Height_in_cm': [170, 180, 175, 185, 178],
'Weight_in_kg': [65, 75, 70, 80, 72],
'Age_in_years': [25, 30, 28, 35, 32]
})
desc_stats = df.describe()
print(desc_stats)
Análise univariada
A análise univariada é a forma mais simples de análise de dados onde os dados que estão sendo analisados contêm apenas uma variável. O principal objetivo da análise univariada é descrever os dados e encontrar padrões que existem dentro deles.
Estes são gráficos comuns usados para realizar análises univariadas.
Histogramas: Utilizados para mostrar a frequência de cada categoria de uma variável contínua. Eles podem ajudar a identificar a tendência, a forma e a disseminação centrais dos dados.
Box plots: Usado para mostrar o intervalo, intervalo interquartílico (IQR), mediana e potenciais valores atípicos de uma variável numérica.
Gráficos de barras: Estes são semelhantes aos histogramas, mas são normalmente usados para variáveis categóricas. Cada barra representa uma categoria, e a altura ou comprimento da barra corresponde à sua frequência ou proporção.
O código a seguir cria um gráfico de caixa e histograma usando Python.
import numpy as np
import matplotlib.pyplot as plt
# Let's assume these are the heights of a group in inches
heights_in_inches = [63, 64, 66, 67, 68, 69, 71, 72, 73, 55, 75]
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
# Boxplot
axs[0].boxplot(heights_in_inches, whis=0.5)
axs[0].set_title('Box plot of heights')
# Histogram
bins = range(min(heights_in_inches), max(heights_in_inches) + 5, 5)
axs[1].hist(heights_in_inches, bins=bins, alpha=0.5)
axs[1].set_title('Frequency distribution of heights')
axs[1].set_xlabel('Height (in)')
axs[1].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
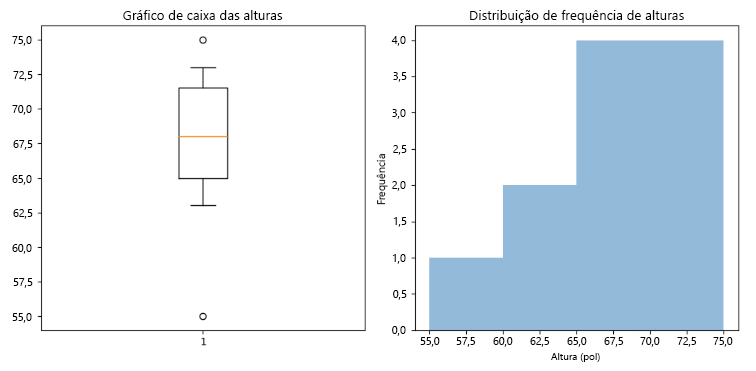
Estas são algumas conclusões que podemos retirar dos resultados.
- No gráfico de caixa, a distribuição das alturas é inclinada para a esquerda, o que significa que há muitos indivíduos com alturas significativamente abaixo da média.
- Existem dois outliers potenciais: 55 polegadas (4'7") e 75 polegadas (6'3"). Esses valores são menores e mais altos do que o resto dos pontos de dados.
- A distribuição das alturas é aproximadamente simétrica em torno da mediana, assumindo que os valores atípicos não distorcem significativamente a distribuição.
Análise bivariada e multivariada
A análise bivariada e multivariada ajuda a entender as relações e interações entre diferentes variáveis em um conjunto de dados e geralmente são apresentadas usando gráficos de dispersão, matrizes de correlação ou tabulações cruzadas.
Gráficos de dispersão
O código a seguir usa a scatter() função de matplotlib para criar o gráfico de dispersão. Especificamos house_sizes para o eixo x e house_prices para o eixo y.
import matplotlib.pyplot as plt
import numpy as np
# Sample data
np.random.seed(0) # for reproducibility
house_sizes = np.random.randint(1000, 3000, size=50) # Size of houses in square feet
house_prices = house_sizes * 100 + np.random.normal(0, 20000, size=50) # Price of houses in dollars
# Create scatter plot
plt.scatter(house_sizes, house_prices)
# Set plot title and labels
plt.title('House Prices vs Size')
plt.xlabel('Size (sqt)')
plt.ylabel('Price ($)')
# Display the plot
plt.show()
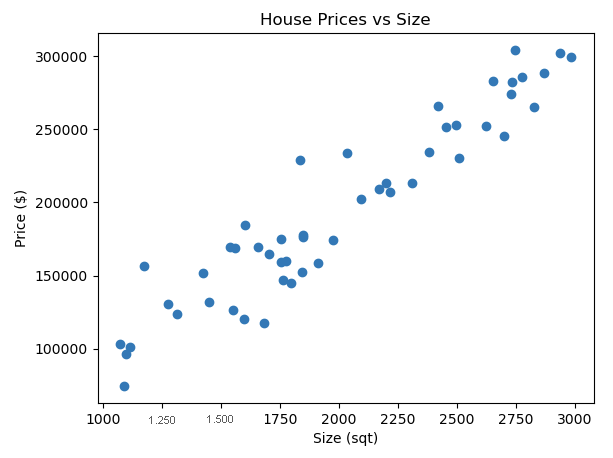
Neste gráfico de dispersão, cada ponto representa uma casa. Você vê que, à medida que o tamanho da casa aumenta (movendo-se para a direita ao longo do eixo x), o preço também tende a aumentar (movendo-se para cima ao longo do eixo y).
Este tipo de análise ajuda-nos a compreender como as mudanças nas variáveis dependentes afetam a variável alvo. Ao analisar as relações entre essas variáveis, podemos fazer previsões sobre a variável alvo com base nos valores das variáveis dependentes.
Além disso, esta análise pode ajudar a identificar quais as variáveis dependentes que têm um impacto significativo na variável alvo. Isso é útil para a seleção de recursos em modelos de aprendizado de máquina, onde o objetivo é usar os recursos mais relevantes para prever o alvo.
Gráfico de linhas
O script Python a seguir usa a matplotlib biblioteca para criar um gráfico de linha de preços de casas simulados durante um período de três anos. Ele gera uma lista de datas mensais de 2020 a 2022 e uma lista correspondente de preços de casas, que começam a partir de US $ 200.000 e aumentam a cada mês com alguma aleatoriedade.
O eixo x do gráfico é formatado para exibir datas no formato 'Ano-Mês' e definir o intervalo dos ticks no eixo x para cada seis meses.
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
import random
import matplotlib.dates as mdates
# Generate monthly dates from 2020 to 2022
dates = [datetime(2020, 1, 1) + timedelta(days=30*i) for i in range(36)]
# Generate corresponding house prices with some randomness
prices = [200000 + 5000*i + random.randint(-5000, 5000) for i in range(36)]
plt.figure(figsize=(10,5))
# Plot data
plt.plot(dates, prices)
# Format x-axis to display dates
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=6)) # set interval to 6 months
plt.gcf().autofmt_xdate() # Rotation
# Set plot title and labels
plt.title('House Prices Over Years')
plt.xlabel('Year-Month')
plt.ylabel('House Price ($)')
# Show the plot
plt.show()
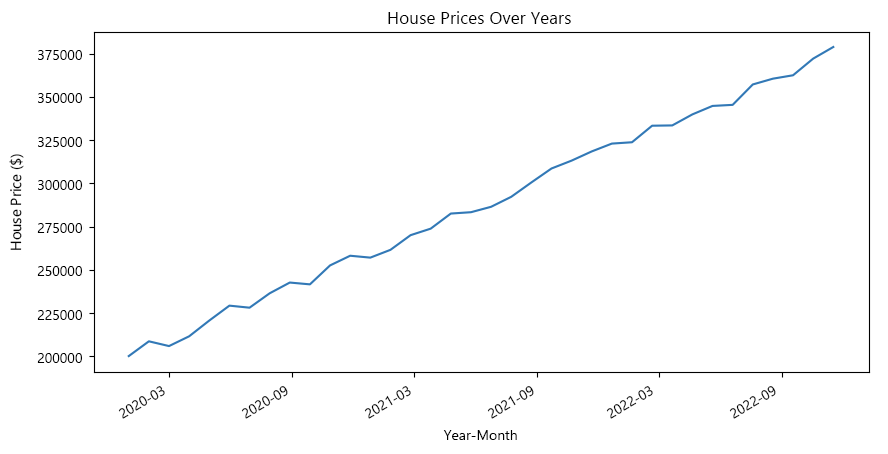
Os gráficos de linhas são simples de entender e ler. Eles fornecem uma visão geral clara e de alto nível da progressão dos dados ao longo do tempo, tornando-os uma escolha popular para dados de séries temporais.
Gráfico de pares
Um gráfico de pares pode ser útil quando você deseja visualizar a relação entre várias variáveis ao mesmo tempo.
import seaborn as sns
import pandas as pd
# Sample data
data = {
'Size': [1000, 2000, 3000, 1500, 1200],
'Bedrooms': [2, 4, 3, 2, 1],
'Age': [5, 10, 2, 6, 4],
'Price': [200000, 400000, 350000, 220000, 150000]
}
df = pd.DataFrame(data)
# Create a pair plot
sns.pairplot(df)
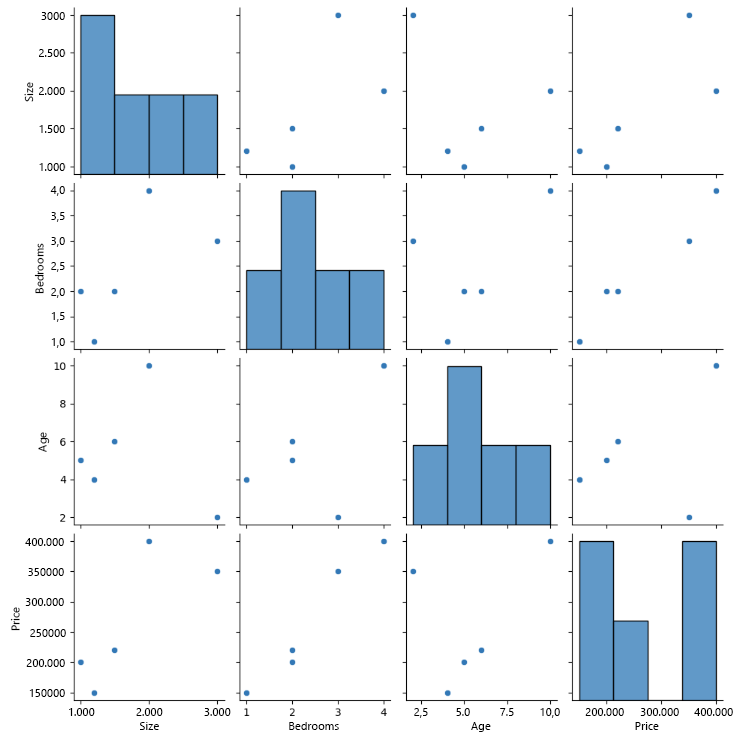
Isso cria uma grade de gráficos onde cada recurso é plotado em relação a todos os outros recursos. Na diagonal estão histogramas mostrando a distribuição de cada característica. Os gráficos fora da diagonal são gráficos de dispersão que mostram a relação entre duas características.
Esse tipo de visualização pode nos ajudar a entender como diferentes recursos estão relacionados entre si e pode ser usado para informar decisões sobre compra ou venda de casas.