Aplicar técnicas avançadas de exploração de dados
Técnicas avançadas de exploração de dados, como análise de correlação e redução de dimensionalidade, ajudam a descobrir padrões e relacionamentos ocultos nos dados, fornecendo informações valiosas que podem orientar a tomada de decisões.
Correlação
A correlação é um método estatístico utilizado para avaliar a força e direção da relação linear entre duas variáveis quantitativas. O coeficiente de correlação varia de -1 a 1.
| Coeficiente de correlação | Description |
|---|---|
| 1 | Indica uma correlação linear positiva perfeita. À medida que uma variável aumenta, a outra variável também aumenta. |
| -1 | Indica uma correlação linear negativa perfeita. À medida que uma variável aumenta, a outra variável diminui. |
| 0 | Indica que não há correlação linear. As duas variáveis não têm relação uma com a outra. |
Vamos usar o conjunto de dados de pinguins para explicar como funciona a correlação.
Nota
O conjunto de dados de pinguins usado é um subconjunto de dados coletados e disponibilizados pela Dra. Kristen Gorman e pela Estação Palmer, Antarctica LTER, membro da Long Term Ecological Research Network.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Load the penguins dataset
penguins = pd.read_csv('https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/penguins.csv')
# Calculate the correlation matrix
corr = penguins.corr()
# Create a heatmap
sns.heatmap(corr, annot=True)
plt.show()
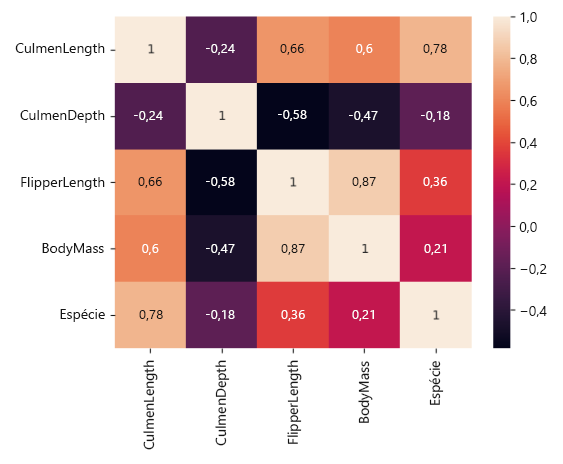
A correlação mais forte no conjunto de dados é entre FlipperLength e BodyMass variáveis, com um coeficiente de correlação de 0,87. Isso sugere que pinguins com nadadeiras maiores tendem a ter uma massa corporal maior.
A identificação e análise de correlações são importantes pelas seguintes razões.
- Análise preditiva: Se duas variáveis estão altamente correlacionadas, podemos prever uma variável a partir da outra.
- Seleção de recursos: se dois recursos estiverem altamente correlacionados, podemos descartar um, pois ele não fornece informações exclusivas.
- Compreender as relações: A correlação ajuda a compreender a relação entre diferentes variáveis nos dados.
Importante
Fundamentalmente, correlação não implica causalidade. Só porque duas variáveis estão correlacionadas não significa que mudanças em uma variável causem mudanças na outra.
Análise de componentes principais (PCA)
A Análise de Componentes Principais (PCA) pode ser usada tanto para exploração quanto para pré-processamento de dados.
Em muitos cenários de dados do mundo real, lidamos com dados de alta dimensão que podem ser difíceis de trabalhar. Quando usado para exploração, o PCA ajuda a reduzir o número de variáveis, mantendo a maioria das informações originais. Isso torna os dados mais fáceis de trabalhar e menos intensivos em recursos para algoritmos de aprendizado de máquina.
Para simplificar o exemplo, estamos trabalhando com o conjunto de dados de pinguins que contém apenas cinco variáveis. No entanto, você seguiria uma abordagem semelhante ao trabalhar com um conjunto de dados maior.
import pandas as pd
import seaborn as sns
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Load the penguins dataset
penguins = pd.read_csv('https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/penguins.csv')
# Remove missing values
penguins = penguins.dropna()
# Prepare the data and target
X = penguins.drop('Species', axis=1)
y = penguins['Species']
# Initialize and apply PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# Plot the data
plt.figure(figsize=(8, 6))
for color, target in zip(['navy', 'turquoise', 'darkorange'], penguins['Species'].unique()):
plt.scatter(X_pca[y == target, 0], X_pca[y == target, 1], color=color, alpha=.8, lw=2,
label=target)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('PCA of Penguins dataset')
plt.show()
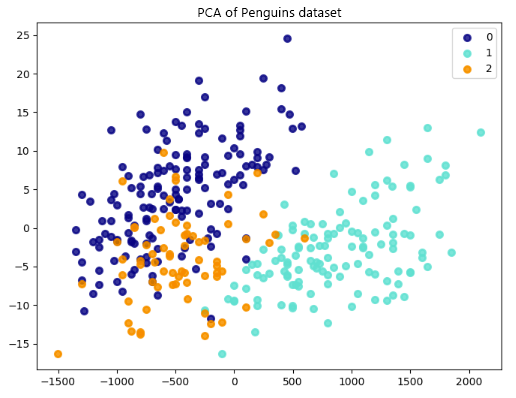
Ao aplicar PCA no conjunto de dados de pinguins, podemos reduzir essas cinco variáveis a dois componentes principais que capturam a maior variância nos dados. Essa transformação reduz a dimensionalidade dos dados de cinco dimensões para duas. Podemos então criar um gráfico de dispersão 2D para visualizar os dados e identificar aglomerados de pinguins com características semelhantes.
Cada ponto no gráfico representa um pinguim do conjunto de dados. Os valores para o primeiro e segundo componentes principais (x e y) determinam a posição de um ponto.
Estas são novas variáveis que a CulmenLengthPCA cria a partir de combinações lineares das variáveis , CulmenDepth, FlipperLength, BodyMass, e Species . O primeiro componente principal captura a maior variância nos dados, e cada componente subsequente captura menos variância.
Os resultados mostram uma separação entre pinguins de diferentes espécies. Ou seja, pontos da mesma cor (espécie) estão mais próximos uns dos outros e pontos de cores diferentes estão mais distantes. Diferenças nas distribuições de características para diferentes classes resultam nessa separação, sugerindo que podemos distinguir essas espécies com base em seus atributos.