Carregar dados para exploração
Carregar e explorar dados são os primeiros passos em qualquer projeto de ciência de dados. Envolvem a compreensão da estrutura, do conteúdo e da fonte dos dados, que são cruciais para a análise subsequente.
Depois de se conectar a uma fonte de dados, você pode salvar os dados em uma casa de lago do Microsoft Fabric. Você pode usar o lakehouse como um local central para armazenar arquivos estruturados, semiestruturados e não estruturados. Você pode então se conectar facilmente à casa do lago sempre que quiser acessar seus dados para exploração ou transformação.
Carregar dados usando blocos de anotações
Os blocos de anotações no Microsoft Fabric facilitam o processo de manipulação de seus ativos de dados. Uma vez que seus ativos de dados estão localizados na casa do lago, você pode facilmente gerar código dentro do bloco de anotações para ingerir esses ativos.
Considere um cenário em que um engenheiro de dados já transformou os dados do cliente e os armazenou na casa do lago. Um cientista de dados pode facilmente carregar os dados usando blocos de anotações para exploração adicional para construir um modelo de aprendizado de máquina. Isso permite que o trabalho comece imediatamente, quer isso envolva manipulações de dados adicionais, análise exploratória de dados ou desenvolvimento de modelos.
Vamos criar um arquivo de parquet de exemplo para ilustrar a operação de carregamento. O código PySpark a seguir cria um dataframe de dados do cliente e o grava em um arquivo Parquet na casa do lago.
O Apache Parquet é um formato de armazenamento de dados de código aberto orientado a colunas. Ele foi projetado para armazenamento e recuperação de dados eficientes e é conhecido por seu alto desempenho e compatibilidade com muitas estruturas de processamento de dados.
from pyspark.sql import Row
Customer = Row("firstName", "lastName", "email", "loyaltyPoints")
customer_1 = Customer('John', 'Smith', 'john.smith@contoso.com', 15)
customer_2 = Customer('Anna', 'Miller', 'anna.miller@contoso.com', 65)
customer_3 = Customer('Sam', 'Walters', 'sam@contoso.com', 6)
customer_4 = Customer('Mark', 'Duffy', 'mark@contoso.com', 78)
customers = [customer_1, customer_2, customer_3, customer_4]
df = spark.createDataFrame(customers)
df.write.parquet("<path>/customers")
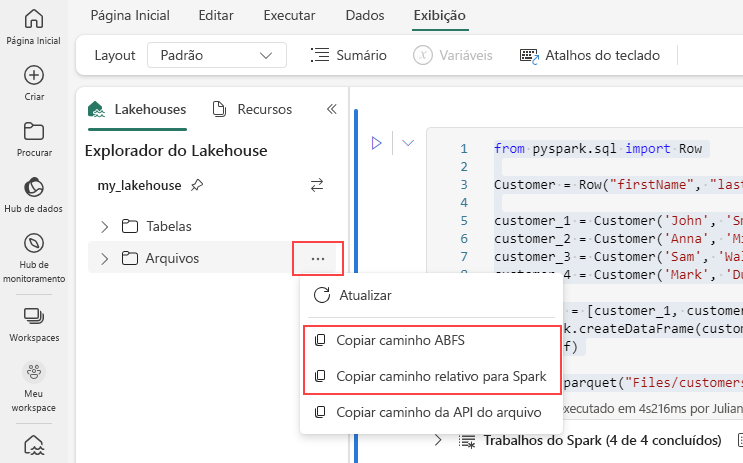
Para gerar o caminho para o arquivo Parquet, selecione as reticências no lakehouse explorer e escolha Copiar caminho ABFS ou Copiar caminho relativo para o Spark. Se estiver escrevendo código Python, você pode usar a opção Copy File API ou Copy ABFS path .
O código a seguir carrega o arquivo parquet em um DataFrame.
df = spark.read.parquet("<path>/customers")
display(df)
Como alternativa, você também pode gerar o código para carregar os dados no bloco de anotações automaticamente. Escolha o arquivo de dados e, em seguida, selecione Carregar dados. Depois disso, você precisará escolher a API que deseja usar.
Embora o arquivo parquet no exemplo anterior seja armazenado na lakehouse, também é possível carregar dados de fontes externas, como o Armazenamento de Blobs do Azure.
account_name = "<account_name>"
container_name = "<container_name>"
relative_path = "<relative_path>"
sas_token = "<sas_token>"
wasbs = f'wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}?{blob_sas_token}'
df = spark.read.parquet(wasbs)
df.show()
Você pode seguir etapas semelhantes para carregar outros tipos de arquivo, como .csv, .jsone .txt arquivos. Basta substituir o .parquet método pelo método apropriado para o seu tipo de arquivo, por exemplo:
# For CSV files
df_csv = spark.read.csv('<path>')
# For JSON files
df_json = spark.read.json('<path>')
# For text files
df_text = spark.read.text('<path>')
Gorjeta
Saiba mais sobre como ingerir e orquestrar dados de várias fontes com o Microsoft Fabric.