Explore o processamento de dados analíticos
O processamento de dados analíticos normalmente usa sistemas somente leitura (ou principalmente leitura) que armazenam grandes volumes de dados históricos ou métricas de negócios. As análises podem ser baseadas num instantâneo dos dados num determinado momento ou numa série de instantâneos.
Os detalhes específicos de um sistema de processamento analítico podem variar entre soluções, mas uma arquitetura comum para análise em escala empresarial tem esta aparência:
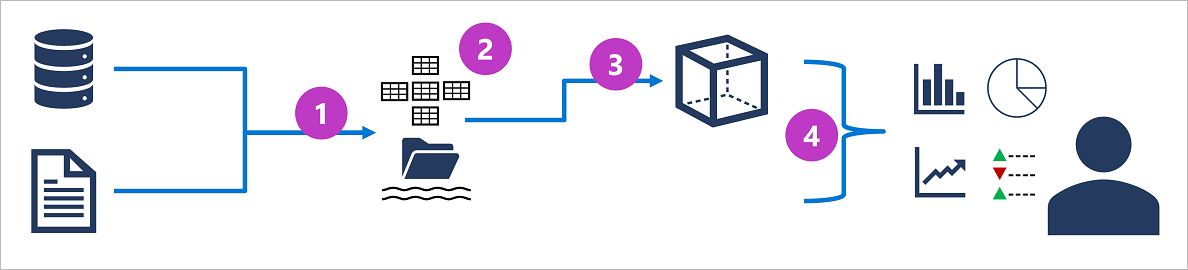
- Os dados operacionais são extraídos, transformados e carregados (ETL) em um data lake para análise.
- Os dados são carregados em um esquema de tabelas - normalmente em um data lakehouse baseado no Spark com abstrações tabulares sobre arquivos no data lake ou em um data warehouse com um mecanismo SQL totalmente relacional.
- Os dados no data warehouse podem ser agregados e carregados em um modelo OLAP (processamento analítico online) ou cubo. Os valores numéricos agregados (medidas) das tabelas de fatos são calculados para interseções de dimensões a partir de tabelas de dimensões. Por exemplo, a receita de vendas pode ser totalizada por data, cliente e produto.
- Os dados no data lake, data warehouse e modelo analítico podem ser consultados para produzir relatórios, visualizações e painéis.
Os data lakes são comuns em cenários de processamento analítico de dados em grande escala, onde um grande volume de dados baseados em arquivos deve ser coletado e analisado.
Os armazéns de dados são uma maneira estabelecida de armazenar dados em um esquema relacional otimizado para operações de leitura – principalmente consultas para dar suporte a relatórios e visualização de dados. Os Data Lakehouses são uma inovação mais recente que combina o armazenamento flexível e escalável de um data lake com a semântica de consulta relacional de um data warehouse. O esquema de tabela pode exigir alguma desnormalização de dados em uma fonte de dados OLTP (introduzindo alguma duplicação para tornar as consultas mais rápidas).
Um modelo OLAP é um tipo agregado de armazenamento de dados otimizado para cargas de trabalho analíticas. As agregações de dados são entre dimensões em diferentes níveis, permitindo que você faça drill up/down para visualizar agregações em vários níveis hierárquicos, por exemplo, para encontrar vendas totais por região, por cidade ou para um endereço individual. Como os dados OLAP são pré-agregados, as consultas para retornar os resumos que eles contêm podem ser executadas rapidamente.
Diferentes tipos de usuários podem realizar trabalho analítico de dados em diferentes estágios da arquitetura geral. Por exemplo:
- Os cientistas de dados podem trabalhar diretamente com arquivos de dados em um data lake para explorar e modelar dados.
- Os analistas de dados podem consultar tabelas diretamente no data warehouse para produzir relatórios e visualizações complexos.
- Os usuários corporativos podem consumir dados pré-agregados em um modelo analítico na forma de relatórios ou painéis.