Descrever o processamento e a ingestão de dados
A análise de dados implica a recolha de dados e a localização de informações e inferências significativas. Isto pode incluir a seleção do conjunto ideal de produtos para um revendedor ou a seleção dos melhores candidatos a vacinas de uma empresa de biotecnologia.
Por exemplo, numa empresa, a análise de dados pode estar relacionada com a utilização dos dados que a sua organização produz para estabelecer como está a ser o desempenho da sua organização e o que pode fazer para o manter. A análise de dados pode ajudá-lo a identificar os pontos fortes e fracos da sua organização e permite-lhe tomar decisões empresariais adequadas.
Os dados que uma empresa utiliza podem ter várias origens. Pode haver um conjunto de dados históricos que têm de ser analisados cuidadosamente, ao mesmo tempo que continuam sempre a chegar dados novos. Estes dados podem ter origem em compras de clientes, transações bancárias, movimentações do preço de ações, dados meteorológicos em tempo real, dispositivos de monitorização ou até mesmo câmaras. Numa solução de análise de dados, tem de combinar estes dados e criar um armazém de dados que pode utilizar para colocar (e responder a) perguntas sobre as suas operações empresariais. A criação de um armazém de dados exige que consiga capturar os dados de que precisa e utilizar um processo de data wrangling para que estes fiquem num formato apropriado. Pode utilizar ferramentas de análise e visualizações para examinar as informações, bem como identificar as tendências e as respetivas causas.
Nota
Data Wrangling é o processo através do qual mapeia e transforma dados não processados num formato mais útil para a análise. Este processo pode implicar a escrita de código para capturar, filtrar, limpar, combinar e agregar dados de várias origens.
Nesta unidade, vai aprender sobre duas fases importantes na análise de dados: a ingestão e o processamento de dados. O diagrama abaixo mostra como essas fases se complementam.
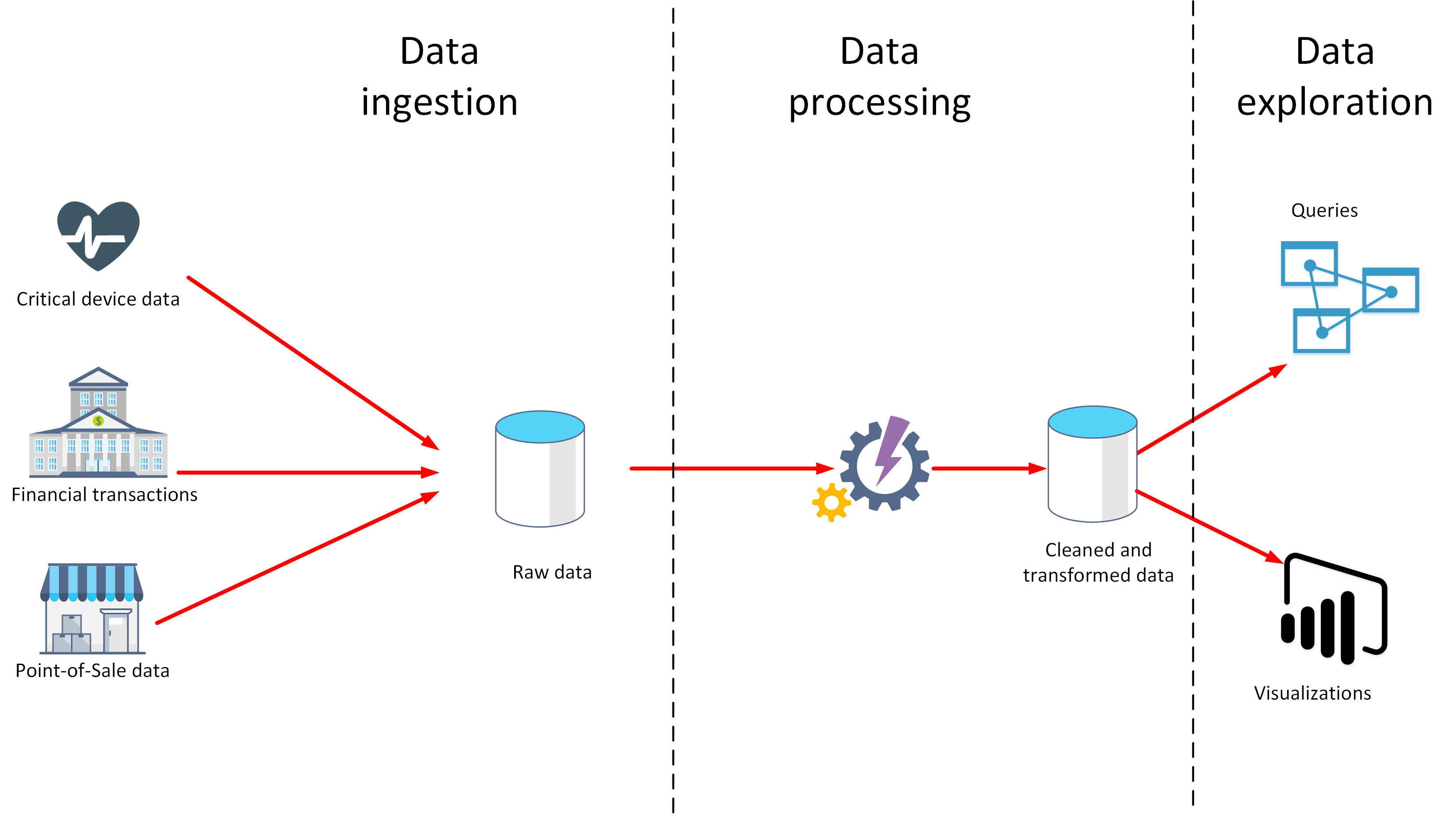
O que é a ingestão de dados?
A ingestão de dados é o processo de obtenção e importação de dados para utilização imediata ou armazenamento numa base de dados. Dependendo da origem, os dados podem chegar sob a forma de um fluxo contínuo ou em lotes. O processo de ingestão tem como finalidade a captura e o armazenamento desses dados. Estes dados não processados podem ser guardados num repositório, como um sistema de gestão de bases de dados, um conjunto de ficheiros ou outro tipo de armazenamento rápido e facilmente acessível.
O processo de ingestão também pode proceder à filtragem. Por exemplo, a ingestão poderá rejeitar dados suspeitos, danificados ou duplicados. Os dados suspeitos podem ser provenientes de uma origem inesperada. Os dados danificados ou duplicados podem dever-se a um erro do dispositivo, a uma falha de transmissão ou a adulteração.
Nesta fase, também poderá ser possível realizar algumas transformações através da conversão de dados num formato padrão para processamento futuro. Por exemplo, é recomendado que volte a formatar todos os dados de data e hora para utilizar as mesmas representações de data e hora e que converta todos os dados de medidas para utilizar as mesmas unidades. No entanto, estas transformações têm de ser realizadas rapidamente. Não tente realizar cálculos complexos nem proceder a agregações nos dados nesta fase.
O que é o processamento de dados?
A fase de processamento de dados ocorre após a ingestão e recolha dos dados. O processamento de dados limpa os dados não processados e converte-os num formato mais significativo (tabelas, gráficos, documentos, etc.). O resultado é uma base de dados que pode utilizar para realizar consultas e gerar visualizações, dando-lhe o formato e o contexto necessários para que esta seja interpretada por computadores e utilizada por colaboradores em toda a organização.
Nota
A limpeza de dados é um termo generalizado que abrange várias ações, tais como a remoção de anomalias e a aplicação de filtros e transformações que seriam demasiado morosas se fossem executadas durante a fase de ingestão.
O objetivo do processamento de dados consiste em converter os dados não processados em um ou mais modelos empresariais. Um modelo empresarial descreve os dados em termos de entidades empresariais significativas e poderá agregar itens e resumir informações. A fase de processamento de dados também pode gerar modelos analíticos preditivos ou outros modelos analíticos a partir dos dados. O processamento de dados pode ser complexo e poderá envolver scripts automatizados e ferramentas como o Azure Databricks, as Funções do Azure e os Serviços Cognitivos do Azure para examinar e voltar a formatar os dados e gerar modelos. Os analistas de dados podem utilizar machine learning para ajudar a determinar tendências futuras com base nestes modelos.

O que é ELT e ETL?
O mecanismo de processamento de dados pode ter duas abordagens para obter os dados ingeridos, processar estes dados para os transformar e gerar modelos e, em seguida, guardar os dados e modelos transformados. Estas abordagens são conhecidas como ETL e ELT.
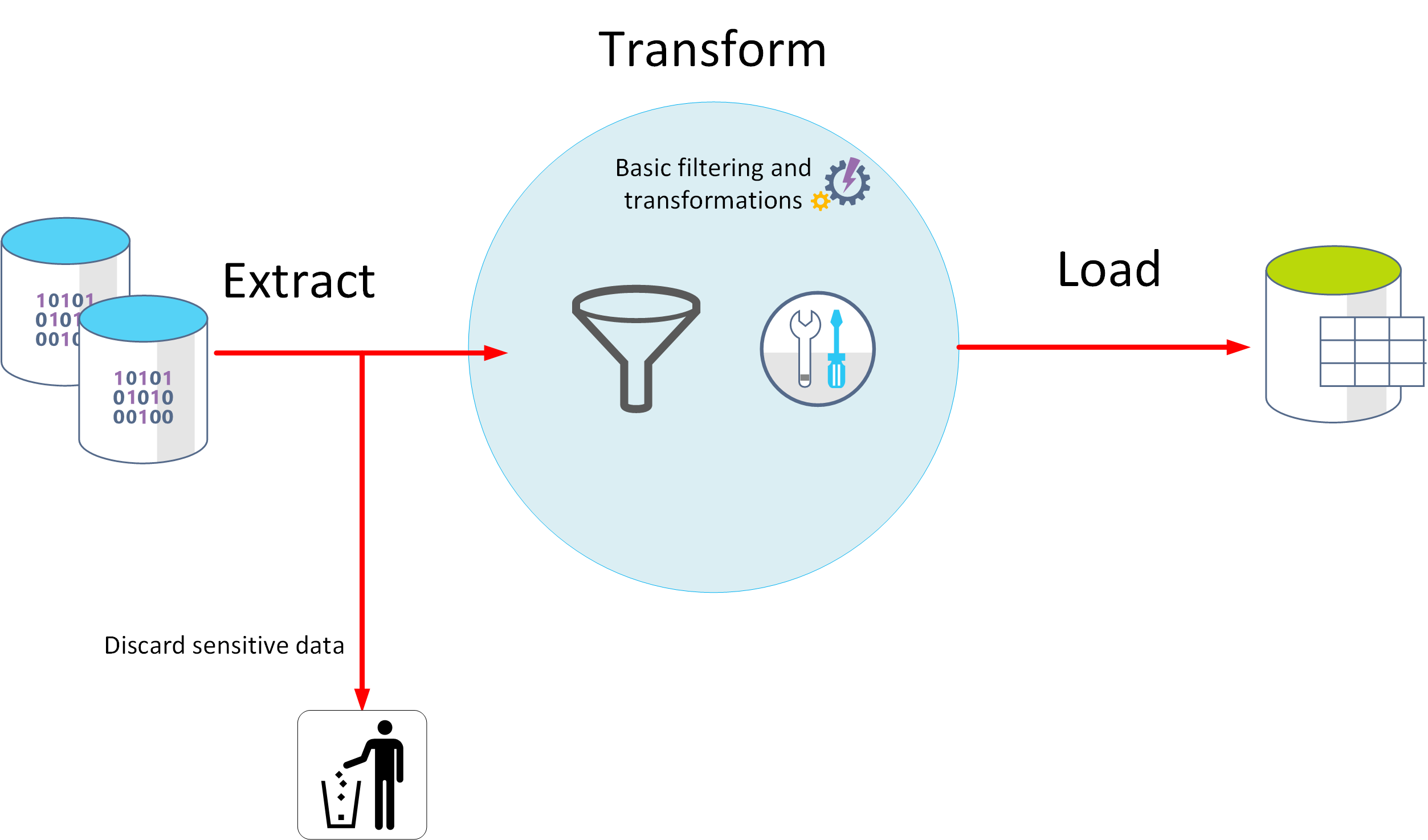
ETL significa Extract, Transform e Load (Extração, Transformação e Carregamento). Os dados não processados são obtidos e transformados antes de serem guardados. Os passos de extração, transformação e carregamento podem ser realizados sob a forma de um pipeline contínuo de operações. Esta abordagem é adequada para sistemas que apenas exigem modelos simples, com pouca dependência entre os itens. Por exemplo, este tipo de processo costuma ser utilizado para realizar tarefas básicas de limpeza de dados, eliminação de dados duplicados e reformatação dos conteúdos de campos individuais.
A ELT é uma das abordagens alternativas. ELT é uma abreviatura de Extract, Load e Transform (Extração, Carregamento e Transformação). O processo difere da abordagem ETL na medida em que os dados são armazenados antes de serem transformados. O motor de processamento de dados pode utilizar uma abordagem iterativa, obtendo e processando os dados a partir do armazenamento antes de escrever novamente os modelos e dados transformados no armazenamento. A abordagem ELT é mais adequada para construir modelos complexos que dependem de múltiplos itens na base de dados, geralmente com recurso ao processamento em lotes periódico.
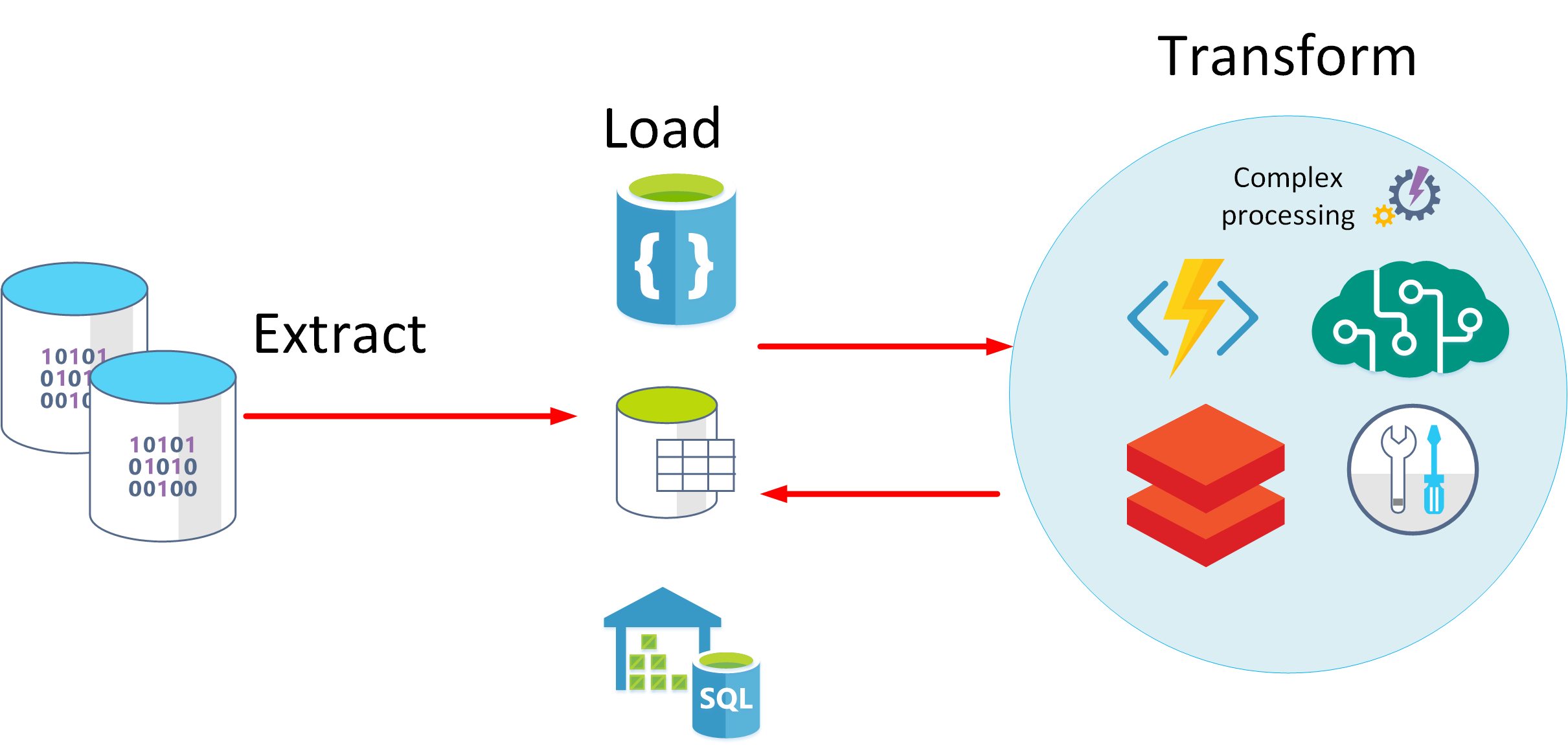
A abordagem ELT é dimensionável e adequada para a cloud, pois pode utilizar a ampla capacidade de processamento disponível. A abordagem ETL mais orientada para o fluxo dá mais ênfase ao débito. No entanto, a abordagem ETL pode filtrar dados antes de serem armazenados. Desta forma, a ETL pode ajudar em matéria de conformidade e privacidade dos dados, ao remover os dados confidenciais antes que cheguem aos modelos de dados analíticos.
O Azure disponibiliza várias opções que pode utilizar para implementar as abordagens ELT e ETL. Por exemplo, se estiver a armazenar dados na Base de Dados SQL do Azure, poderá utilizar o SQL Server Integration Services. O SQL Server Integration Services consegue extrair e transformar dados de uma vasta gama de origens, tais como ficheiros de dados XML, ficheiros simples e origens de dados relacionais, e, em seguida, carregar os dados em um ou mais destinos.
Esta é uma tabela simples que mostra as vantagens do ETL e ELT na maioria dos casos.

Outra abordagem mais generalizada consiste em utilizar o Azure Data Factory. O Azure Data Factory é um serviço de integração de dados com base na cloud, que lhe permite criar fluxos de trabalho condicionados por dados para orquestrar o movimento e a transformação de dados em escala. Ao utilizar o Azure Data Factory, pode criar e agendar fluxos de trabalho condicionados por dados (denominados pipelines) que podem ingerir dados a partir de arquivos de dados diferentes. Você pode criar processos ETL complexos que transformam dados visualmente com fluxos de dados ou usando serviços de computação como o Azure Databricks e o Banco de Dados SQL do Azure.