Explore pipelines de ingestão de dados
Agora que você entende um pouco sobre a arquitetura de uma solução de armazenamento de dados em grande escala e algumas das tecnologias de processamento distribuído que podem ser usadas para lidar com grandes volumes de dados, é hora de explorar como os dados são ingeridos em um armazenamento de dados analíticos de uma ou mais fontes.
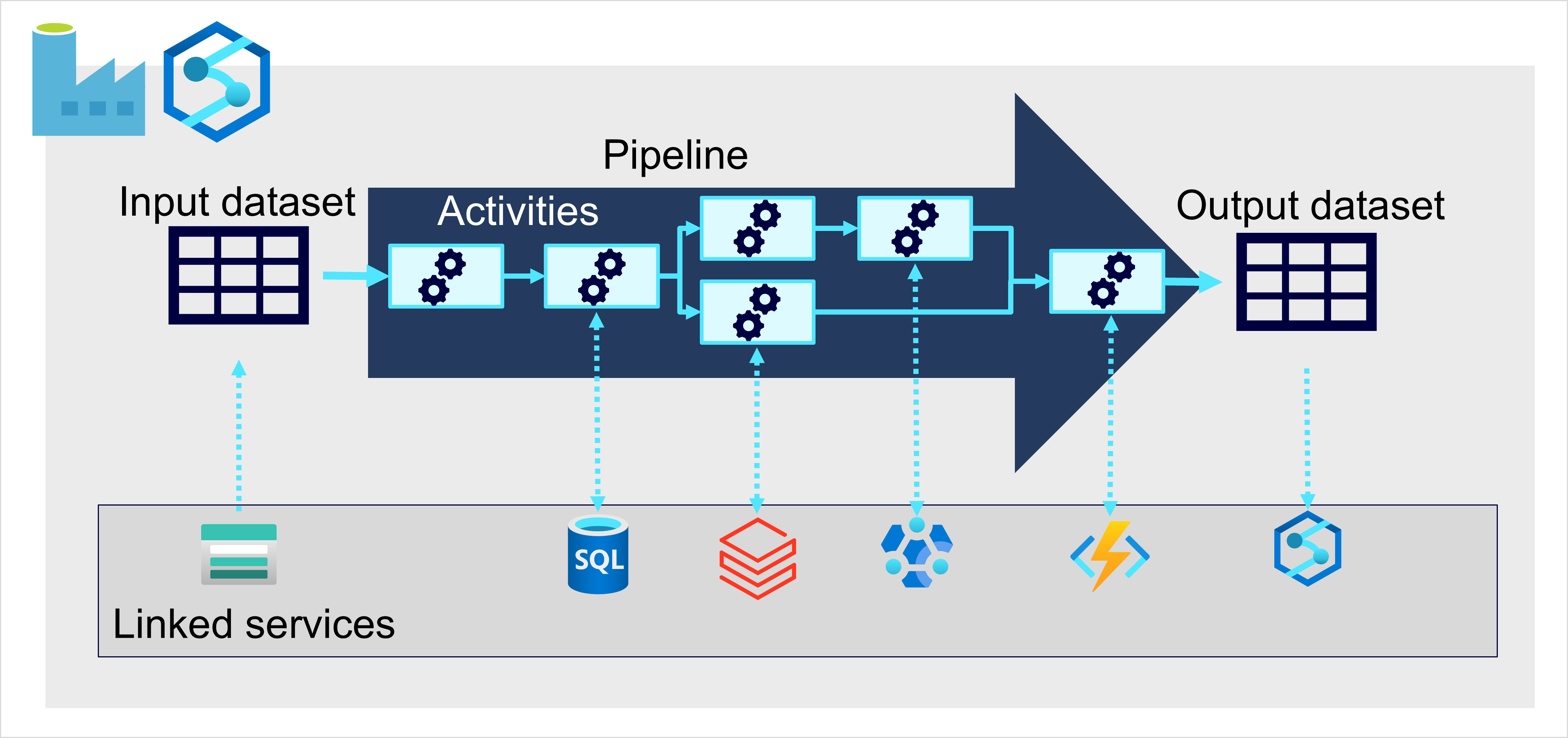
No Azure, a ingestão de dados em grande escala é melhor implementada criando pipelines que orquestram processos ETL. Você pode criar e executar pipelines usando o Azure Data Factory ou pode usar o recurso de pipeline no Microsoft Fabric se quiser gerenciar todos os componentes de sua solução de armazenamento de dados em um espaço de trabalho unificado.
Em ambos os casos, os pipelines consistem em uma ou mais atividades que operam com dados. Um conjunto de dados de entrada fornece os dados de origem, e as atividades podem ser definidas como um fluxo de dados que manipula incrementalmente os dados até que um conjunto de dados de saída seja produzido. Os pipelines usam serviços vinculados para carregar e processar dados, permitindo que você use a tecnologia certa para cada etapa do fluxo de trabalho. Por exemplo, você pode usar um serviço vinculado do Repositório de Blobs do Azure para ingerir o conjunto de dados de entrada e, em seguida, usar serviços como o Banco de Dados SQL do Azure para executar um procedimento armazenado que procura valores de dados relacionados, antes de executar uma tarefa de processamento de dados no Azure Databricks, ou aplicar lógica personalizada usando uma Função do Azure. Finalmente, você pode salvar o conjunto de dados de saída em um serviço vinculado, como o Microsoft Fabric. Os pipelines também podem incluir algumas atividades internas, que não exigem um serviço vinculado.