Armazenar vetores no Banco de Dados do Azure para PostgreSQL
Lembre-se de que você precisa incorporar vetores armazenados em um banco de dados vetorial para executar uma pesquisa semântica. O servidor flexível do Banco de Dados do Azure para PostgreSQL pode ser usado como um banco de dados vetorial com a vector extensão.
Introdução ao vector
A extensão de código vector aberto fornece armazenamento vetorial, consulta de similaridade e outras operações vetoriais para PostgreSQL. Uma vez habilitado, você pode criar vector colunas para armazenar incorporações (ou outros vetores) ao lado de outras colunas.
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
Você pode adicionar colunas vetoriais a tabelas existentes:
ALTER TABLE documents ADD COLUMN embedding vector(3);
Depois de ter alguns dados vetoriais, você pode vê-los ao lado dos dados normais da tabela:
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
A vector extensão suporta várias linguagens, como .NET, Python, Java e muitas outras. Veja seus repositórios do GitHub para saber mais.
Para inserir um documento com vetor [1, 2, 3] usando Npgsql em C#, execute um código como este:
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
Inserir e atualizar vetores
Quando uma tabela tem uma coluna vetorial, as linhas podem ser adicionadas com valores vetoriais, como observado anteriormente.
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
Você também pode carregar vetores em massa usando a instrução (veja o COPY exemplo completo em Python):
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
As colunas vetoriais podem ser atualizadas como colunas padrão:
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
Realizar uma pesquisa de distância cosseno
A vector extensão fornece ao v1 <=> v2 operador para calcular a distância cosseno entre vetores v1 e v2. O resultado é um número entre 0 e 2, onde 0 significa "semanticamente idêntico" (sem distância) e dois significa "semanticamente oposto" (distância máxima).
Você pode ver os termos cosseno distância e semelhança. Lembre-se que a semelhança cosseno está entre -1 e 1, onde -1 significa "semanticamente oposto" e 1 significa "semanticamente idêntico". Note-se que similarity = 1 - distance.
O resultado é que uma consulta ordenada por distância ascendente retorna os resultados menos distantes (mais semelhantes) primeiro, enquanto uma consulta ordenada por semelhança descendente retorna os resultados mais semelhantes (menos distantes) primeiro.
Aqui estão alguns vetores e suas distâncias e semelhanças para ilustrar os conceitos. Você mesmo pode calcular esse cálculo executando algo como:
SELECT '[1,1]' <=> '[-1,-1]';
Considere estes vetores:
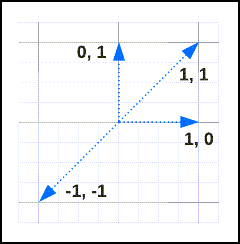
As suas semelhanças e distâncias são:
| v1 | V2 | Distância | semelhança |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
Para obter os documentos em ordem de proximidade com o vetor [2, 3, 4], execute esta consulta:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
Resultados:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
O documento com id=3 é o mais semelhante à consulta, seguido por id=1, e por último por id=2.
Adicione uma LIMIT N cláusula à SELECT consulta para retornar os principais N documentos mais semelhantes. Por exemplo, para obter o documento mais semelhante:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
Resultados:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535