Monitorar o modelo
Como cientista de dados, você quer treinar o melhor modelo de aprendizado de máquina. Para implementar o modelo, você deseja implantá-lo em um ponto de extremidade e integrá-lo a um aplicativo.
Com o tempo, você quer treinar novamente o modelo. Por exemplo, você pode treinar novamente o modelo quando tiver mais dados de treinamento.
Em geral, depois de treinar um modelo de aprendizado de máquina, você deseja preparar o modelo para a escala empresarial. Para preparar o modelo e operacionalizá-lo, pretende-se:
- Converta o treinamento do modelo em um pipeline robusto e reproduzível .
- Teste o código e o modelo em um ambiente de desenvolvimento .
- Implante o modelo em um ambiente de produção .
- Automatize o processo de ponta a ponta.
Projetar uma arquitetura MLOps
Trazer um modelo para a produção significa que você precisa escalar sua solução e trabalhar em conjunto com outras equipes. Juntamente com outros cientistas de dados, engenheiros de dados e uma equipe de infraestrutura, você pode decidir usar a seguinte abordagem:
- Armazene todos os dados em um armazenamento de Blob do Azure, gerenciado pelo engenheiro de dados.
- A equipe de infraestrutura cria todos os recursos necessários do Azure, como o espaço de trabalho do Azure Machine Learning.
- Os cientistas de dados concentram-se no que fazem melhor: desenvolver e treinar o modelo (loop interno).
- Os engenheiros de aprendizado de máquina implantam os modelos treinados (loop externo).
Como resultado, sua arquitetura MLOps inclui as seguintes partes:
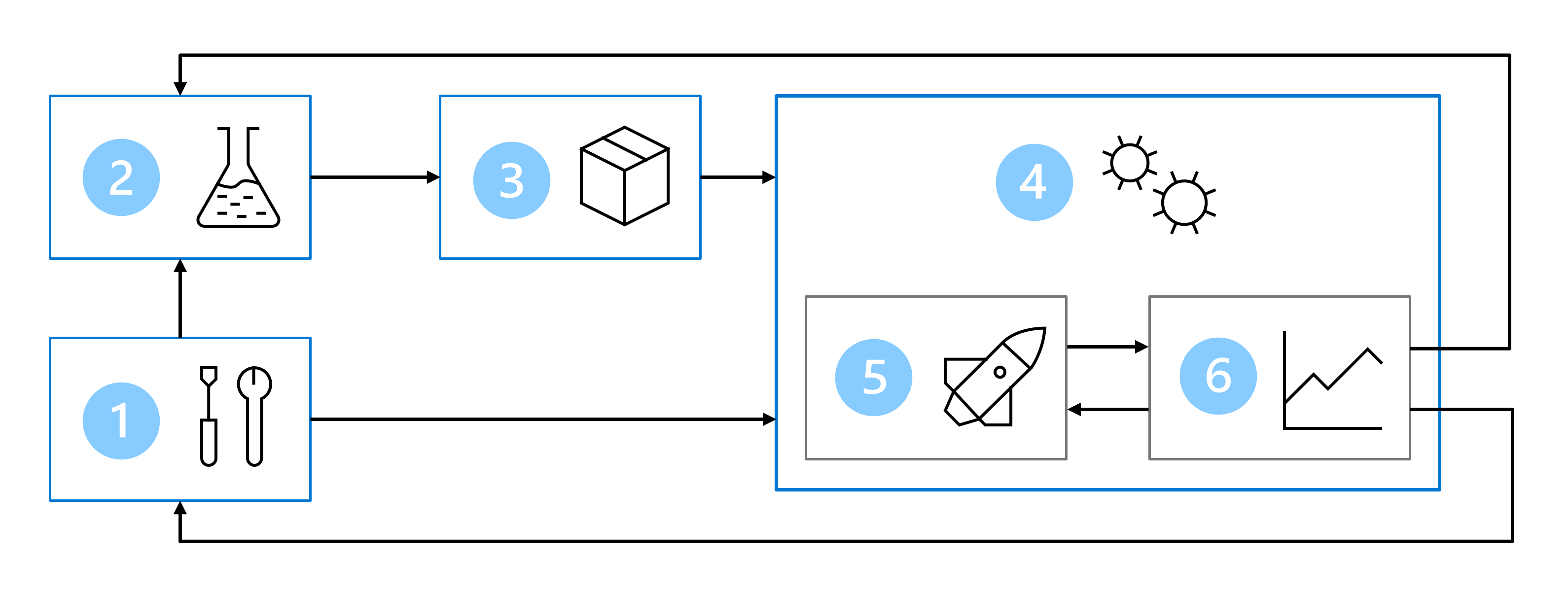
- Configuração: crie todos os recursos necessários do Azure para a solução.
- Desenvolvimento do modelo (loop interno): Explore e processe os dados para treinar e avaliar o modelo.
- Integração contínua: Empacotar e registrar o modelo.
- Implantação do modelo (loop externo): implante o modelo.
- Implantação contínua: teste o modelo e promova para o ambiente de produção.
- Monitoramento: Monitore o desempenho do modelo e do ponto final.
Quando você está trabalhando com equipes maiores, não se espera que você seja responsável por todas as partes da arquitetura MLOps como cientista de dados. Para preparar seu modelo para MLOps como cientista de dados, você deve pensar em como projetar para monitoramento e reciclagem.
Monitorar o desempenho do modelo
Se você quiser treinar novamente apenas quando necessário, você pode monitorar o desempenho do modelo e qualquer coisa que possa influenciá-lo:
- Acompanhe o desempenho: monitore as principais métricas do modelo, como precisão e pontuação F1, para avaliar a eficácia do seu modelo.
- Detetar desvio de dados: o desvio de dados ocorre quando as propriedades estatísticas dos dados de entrada mudam ao longo do tempo. A deteção de desvio de dados envolve o monitoramento das distribuições de recursos de entrada ou variáveis de destino para identificar quaisquer alterações significativas que possam afetar o desempenho do modelo.
- Identificar desvio de conceito: O desvio de conceito refere-se a mudanças na relação entre os recursos de entrada e a variável de destino. O desvio de conceito pode acontecer quando os padrões subjacentes nos dados evoluem. Identificar desvios de conceito envolve acompanhar o desempenho do modelo em novos dados e procurar mudanças nas relações de rótulo de recurso.
Retreinar o modelo
Geralmente, há duas abordagens para quando você deseja treinar novamente um modelo:
- Com base num calendário: quando sabe que precisa sempre da versão mais recente do modelo, pode decidir reciclar o seu modelo todas as semanas, ou todos os meses, com base num calendário.
- Com base em métricas: se você quiser treinar novamente seu modelo apenas quando necessário, poderá monitorar o desempenho do modelo e o desvio de dados para decidir quando precisará treinar novamente o modelo.
Em ambos os casos, você precisa projetar para reciclagem. Para treinar facilmente seu modelo, você deve preparar seu código para automação.
Prepare o seu código
O ideal é treinar modelos com scripts em vez de notebooks. Os scripts são mais adequados para automação. Você pode adicionar parâmetros a um script e alterar parâmetros de entrada, como dados de treinamento ou valores de hiperparâmetros. Ao parametrizar seus scripts, você pode facilmente treinar novamente o modelo em novos dados, se necessário.
Outra coisa importante para preparar seu código é hospedar o código em um repositório central. Um repositório refere-se a um local onde todos os arquivos relevantes para um projeto são armazenados. Com projetos de aprendizado de máquina, os repositórios baseados em Git são ideais para obter o controle do código-fonte.
Quando você aplica o controle do código-fonte ao seu projeto, você pode colaborar facilmente em um projeto. Você pode designar alguém para melhorar o modelo atualizando o código. Você pode explorar as alterações anteriores e revisar as alterações antes que elas sejam confirmadas no repositório principal.
Automatize seu código
Quando quiser executar automaticamente seu código, você pode configurar trabalhos do Aprendizado de Máquina do Azure para executar scripts. No Azure Machine Learning, você também pode criar e agendar pipelines para executar scripts.
Se quiser que os scripts sejam executados com base em um gatilho ou evento que acontece fora do Azure Machine Learning, acione o trabalho do Azure Machine Learning a partir de outra ferramenta.
Duas ferramentas que são comumente usadas em projetos MLOps são o Azure DevOps e o GitHub (Actions). Ambas as ferramentas permitem criar pipelines de automação e podem acionar pipelines do Azure Machine Learning.
Como cientista de dados, você pode preferir trabalhar com o SDK Python do Azure Machine Learning. No entanto, ao trabalhar com ferramentas como o Azure DevOps e o GitHub, você pode preferir configurar os recursos e trabalhos necessários com a extensão da CLI do Azure Machine Learning. A CLI do Azure foi projetada para automatizar tarefas e se integra bem ao Azure DevOps e ao GitHub.
Gorjeta
Se você quiser saber mais sobre MLOps, explore a introdução às operações de aprendizado de máquina (MLOps) ou tente criar seu primeiro pipeline de automação de MLOps com o GitHub Actions