Descrever o Azure Synapse Link
As soluções HTAP são suportadas no Azure Synapse Analytics através do Azure Synapse Link, um termo geral para um conjunto de serviços ligados que suportam a sincronização de dados HTAP na sua área de trabalho do Azure Synapse Analytics.
Azure Synapse Link para Cosmos DB
O Azure Cosmos DB é um serviço de dados NoSQL de escala global no Microsoft Azure que permite que os aplicativos armazenem e acessem dados operacionais usando uma variedade de interfaces de programação de aplicativos (APIs).
O Azure Synapse Link for Azure Cosmos DB é um recurso HTAP nativo da nuvem que permite executar análises quase em tempo real sobre dados operacionais armazenados em um contêiner do Cosmos DB. O Azure Synapse Link cria uma integração totalmente integrada entre o Azure Cosmos DB e o Azure Synapse Analytics.
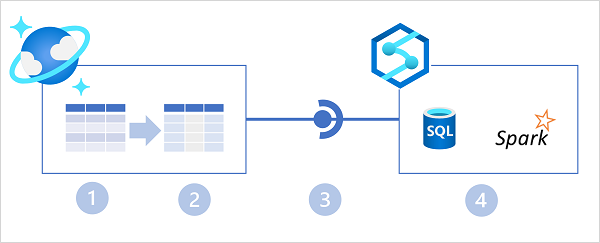
No diagrama acima, os seguintes recursos principais da arquitetura do Azure Synapse Link for Cosmos DB são ilustrados:
- Um contêiner do Azure Cosmos DB fornece um repositório transacional baseado em linha que é otimizado para operações de leitura/gravação.
- O contêiner também fornece um armazenamento analítico baseado em colunas que é otimizado para cargas de trabalho analíticas. Um processo de sincronização automática totalmente gerenciado mantém os armazenamentos de dados sincronizados.
- O Azure Synapse Link fornece um serviço vinculado que conecta o contêiner habilitado para armazenamento analítico no Azure Cosmos DB a um espaço de trabalho do Azure Synapse Analytics.
- O Azure Synapse Analytics fornece tempos de execução Synapse SQL e Apache Spark nos quais você pode executar código para recuperar, processar e analisar dados do repositório analítico do Azure Cosmos DB sem afetar o armazenamento de dados transacionais no Azure Cosmos DB.
Azure Synapse Link para SQL
O Microsoft SQL Server é um popular sistema de banco de dados relacional que alimenta aplicativos de negócios em algumas das maiores organizações do mundo. O Banco de Dados SQL do Azure é uma solução de banco de dados de plataforma como serviço baseada em nuvem baseada no SQL Server. Ambas as soluções de banco de dados relacional são comumente usadas como armazenamentos de dados operacionais.
O Azure Synapse Link for SQL permite a integração HTAP entre dados no SQL Server ou no Banco de Dados SQL do Azure e um espaço de trabalho do Azure Synapse Analytics.
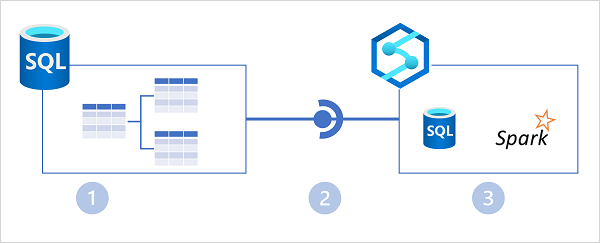
No diagrama acima, os seguintes recursos principais da arquitetura do Azure Synapse Link for SQL são ilustrados:
- Um Banco de Dados SQL do Azure ou uma instância do SQL Server contém um banco de dados relacional no qual os dados transacionais são armazenados em tabelas.
- O Azure Synapse Link for SQL replica os dados da tabela para um pool SQL dedicado em um espaço de trabalho do Azure Synapse.
- Os dados replicados no pool SQL dedicado podem ser consultados no pool SQL dedicado ou conectados como uma fonte externa de um pool do Spark sem afetar o banco de dados de origem.
Azure Synapse Link for Dataverse
O Microsoft Dataverse é um serviço de armazenamento de dados dentro da Microsoft Power Platform. Você pode usar o Dataverse para armazenar dados corporativos em tabelas que são acessadas pelo Power Apps, Power BI, Power Virtual Agents e outros aplicativos e serviços no Microsoft 365, Dynamics 365 e Azure.
O Azure Synapse Link for Dataverse permite a integração HTAP replicando dados de tabela para o armazenamento do Azure Data Lake, onde podem ser acessados por tempos de execução no Azure Synapse Analytics - diretamente do data lake ou por meio de um Lake Database definido em um pool SQL sem servidor.
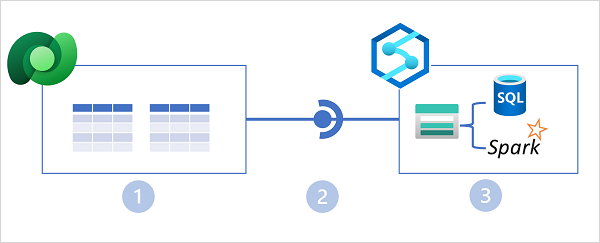
No diagrama acima, os seguintes recursos principais da arquitetura do Azure Synapse Link for Dataverse são ilustrados:
- Os aplicativos de negócios armazenam dados em tabelas do Microsoft Dataverse.
- O Azure Synapse Link for Dataverse replica os dados da tabela para uma conta de armazenamento do Azure Data Lake Gen2 associada a um espaço de trabalho do Azure Synapse.
- Os dados no data lake podem ser usados para definir tabelas em um banco de dados lake e consultados usando um pool SQL sem servidor ou lidos diretamente do armazenamento usando SQL ou Spark.