Coletar, consultar e visualizar estados de integridade
Para representar com precisão um modelo de integridade, você deve reunir vários conjuntos de dados do sistema. Os conjuntos de dados incluem logs e métricas de desempenho de componentes de aplicativos e recursos subjacentes do Azure. É importante correlacionar dados entre os conjuntos de dados para criar uma representação em camadas da integridade para o sistema.
Código e infraestrutura de instrumentação
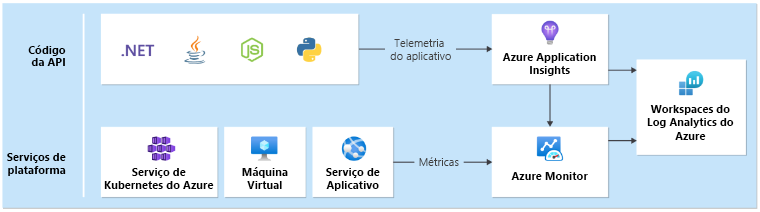
Um coletor de dados unificado é necessário para garantir que todos os dados operacionais sejam armazenados e estejam disponíveis em um único local onde toda a telemetria é coletada. Por exemplo, quando um funcionário cria um comentário em seu navegador da Web, você pode acompanhar essa operação e ver que a solicitação passou pela API de Catálogo para Hubs de Eventos do Azure. A partir daí, o processador em segundo plano pegou o comentário e o armazenou no Azure Cosmos DB.
O Azure Monitor Log Analytics serve como o principal coletor de dados unificado nativo do Azure para armazenar e analisar dados operacionais:
O Application Insights é a ferramenta recomendada de monitoramento de desempenho de aplicativos (APM) em todos os componentes do aplicativo para coletar logs, métricas e rastreamentos de aplicativos. O Application Insights é implantado em uma configuração baseada em espaço de trabalho em cada região.
No aplicativo de exemplo, o Azure Functions é usado no Microsoft .NET 6 para seus serviços back-end para integração nativa. Como os aplicativos back-end já existem, a Contoso Shoes cria apenas um novo recurso do Application Insights no Azure e define a
APPLICATIONINSIGHTS_CONNECTION_STRINGconfiguração em ambos os aplicativos de função. O tempo de execução do Azure Functions registra o provedor de log do Application Insights automaticamente, para que a telemetria apareça no Azure sem esforço extra. Para um registro mais personalizado, você pode usar aILoggerinterface.O conjunto de dados centralizado é um antipadrão para cargas de trabalho de missão crítica. Cada região deve ter seu espaço de trabalho dedicado do Log Analytics e uma instância do Application Insights. Para recursos globais, recomendam-se instâncias separadas. Para ver o padrão de arquitetura principal, consulte Padrão de arquitetura para cargas de trabalho de missão crítica no Azure.
Cada camada deve enviar dados para o mesmo espaço de trabalho do Log Analytics, para facilitar a análise e os cálculos de integridade.
Consultas de monitoramento de integridade
O Log Analytics, o Application Insights e o Azure Data Explorer usam o Kusto Query Language (KQL) para suas consultas. Você pode usar o KQL para criar consultas e usar funções para buscar métricas e calcular pontuações de integridade.
Para serviços individuais que calculam o status de integridade, consulte as consultas de exemplo a seguir.
API do Catálogo
O exemplo a seguir demonstra uma consulta de API de catálogo:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 10, 50, // Failed requests, anything non-200, allow a few more than 0 for user-caused errors like 404s
"avgProcessingTime", 150, 500 // Average duration of the request, in ms
];
// Calculate average processing time for each request
let avgProcessingTime = AppRequests
| where AppRoleName startswith "CatalogService"
| where OperationName != "GET /health/liveness" // Liveness requests don't do any processing, including them would skew the results
| make-series Value = avg(DurationMs) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'avgProcessingTime';
// Calculate failed requests
let failureCount = AppRequests
| where AppRoleName startswith "CatalogService" // Liveness requests don't do any processing, including them would skew the results
| where OperationName != "GET /health/liveness"
| make-series Value=countif(Success != true) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'failureCount';
// Union all together and join with the thresholds
avgProcessingTime
| union failureCount
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
| project-reorder TimeGenerated, MetricName, Value, IsYellow, IsRed, YellowThreshold, RedThreshold
| extend ComponentName="CatalogService"
Azure Key Vault
O exemplo a seguir demonstra uma consulta do Azure Key Vault:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds = datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 3, 10 // Failure count on key vault requests
];
let failureStats = AzureDiagnostics
| where TimeGenerated > _timespanStart
| where ResourceProvider == "MICROSOFT.KEYVAULT"
// Ignore authentication operations that have a 401. This is normal when using Key Vault SDK. First an unauthenticated request is made, then the response is used for authentication
| where Category=="AuditEvent" and not (OperationName == "Authentication" and httpStatusCode_d == 401)
| where OperationName in ('SecretGet','SecretList','VaultGet') or '*' in ('SecretGet','SecretList','VaultGet')
// Exclude Not Found responses because these happen regularly during 'Terraform plan' operations, when Terraform checks for the existence of secrets
| where ResultSignature != "Not Found"
// Create ResultStatus with all the 'success' results bucketed as 'Success'
// Certain operations like StorageAccountAutoSyncKey have no ResultSignature; for now, also set to 'Success'
| extend ResultStatus = case ( ResultSignature == "", "Success",
ResultSignature == "OK", "Success",
ResultSignature == "Accepted", "Success",
ResultSignature);
failureStats
| make-series Value=countif(ResultStatus != "Success") default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName="failureCount", ComponentName="Keyvault"
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
Pontuação de integridade do Serviço de Catálogo
Eventualmente, você pode unir várias consultas de status de integridade para calcular uma pontuação de integridade de um componente. A consulta de exemplo a seguir mostra como calcular uma pontuação de integridade do Serviço de Catálogo:
CatalogServiceHealthStatus()
| union AksClusterHealthStatus()
| union KeyvaultHealthStatus()
| union EventHubHealthStatus()
| where TimeGenerated < ago(2m)
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed) by bin(TimeGenerated, 2m)
| extend HealthScore = 1 - (YellowScore * 0.25) - (RedScore * 0.5)
| extend ComponentName = "CatalogService", Dependencies="AKSCluster,Keyvault,EventHub" // These values are added to build the dependency visualization
| order by TimeGenerated desc
Gorjeta
Veja mais exemplos de consulta no repositório GitHub Online de Missão Crítica do Azure.
Configurar alertas baseados em consulta
Os alertas chamam a atenção imediata para problemas que refletem ou afetam o estado de saúde. Sempre que houver uma mudança no estado de saúde, seja para um estado degradado (amarelo) ou para um estado insalubre (vermelho), as notificações devem ser enviadas para a equipe responsável. Defina alertas no nó raiz do modelo de integridade para tomar conhecimento imediato de qualquer alteração no nível de negócios no estado de integridade da solução. Em seguida, você pode examinar as visualizações do modelo de integridade para obter mais informações e solucionar problemas.
O exemplo usa alertas do Azure Monitor para direcionar ações automatizadas em resposta a alterações no estado de integridade do aplicativo.
Usar painéis para visualização
É importante visualizar seu modelo de integridade para que você possa entender rapidamente o efeito de uma interrupção de componente em todo o sistema. O objetivo final de um modelo de saúde é facilitar o diagnóstico rápido, fornecendo uma visão informada dos desvios do estado estacionário.
Uma maneira comum de visualizar informações de integridade do sistema é combinar uma exibição de modelo de integridade em camadas com recursos de detalhamento de telemetria em um painel.
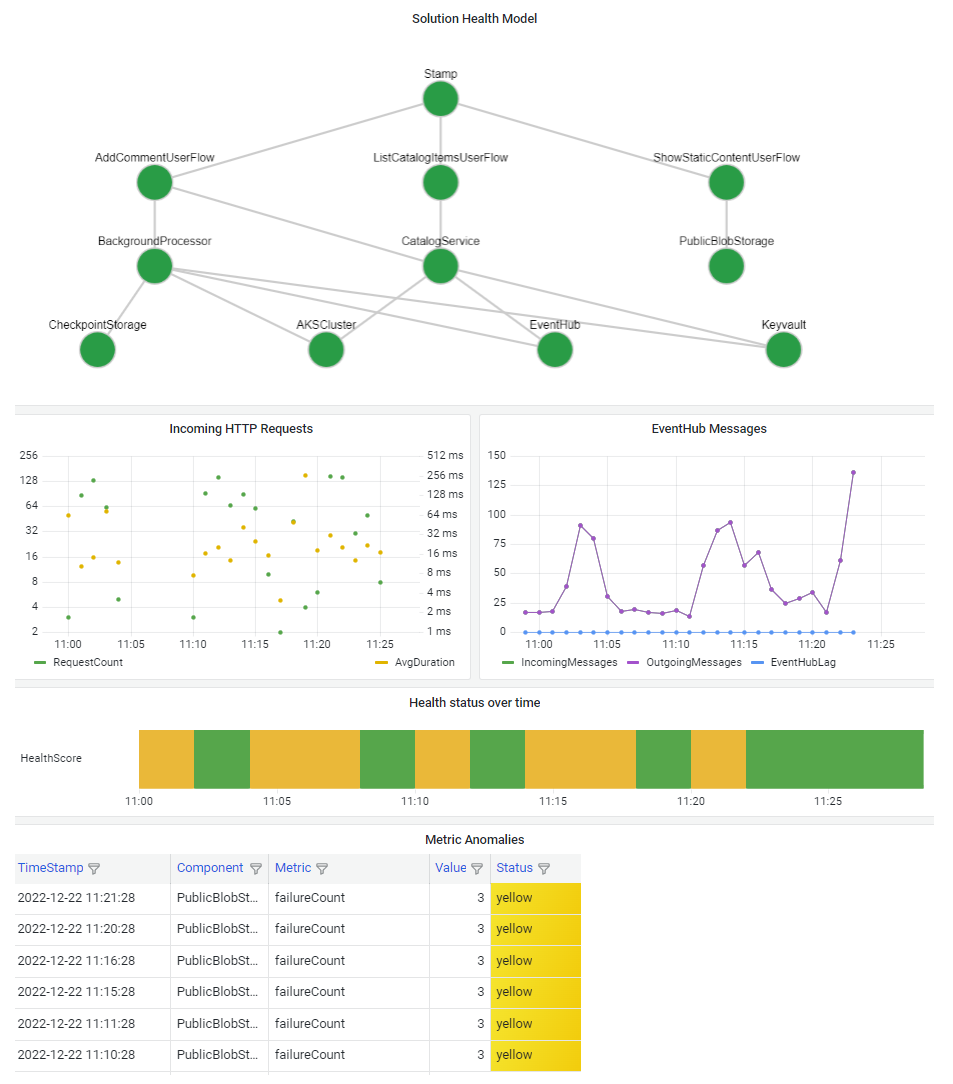
A tecnologia do painel deve ser capaz de representar o modelo de integridade. As opções populares incluem Painéis do Azure, Power BI e Azure Managed Grafana.