Projetar uma solução analítica e de integração de dados com o Azure Synapse Analytics
O Azure Synapse Analytics combina recursos de análise de big data, armazenamento de dados corporativos e integração de dados. O serviço permite executar consultas em dados sem servidor ou dados em escala. O Azure Synapse dá suporte à ingestão, exploração, transformação e gerenciamento de dados e dá suporte à análise para todas as suas necessidades de BI e aprendizado de máquina.
Coisas a saber sobre o Azure Synapse Analytics
O Azure Synapse Analytics implementa uma arquitetura de processamento paralelo maciço (MPP) e tem as seguintes características.
A arquitetura do Azure Synapse Analytics inclui um nó de controle e um pool de nós de computação.
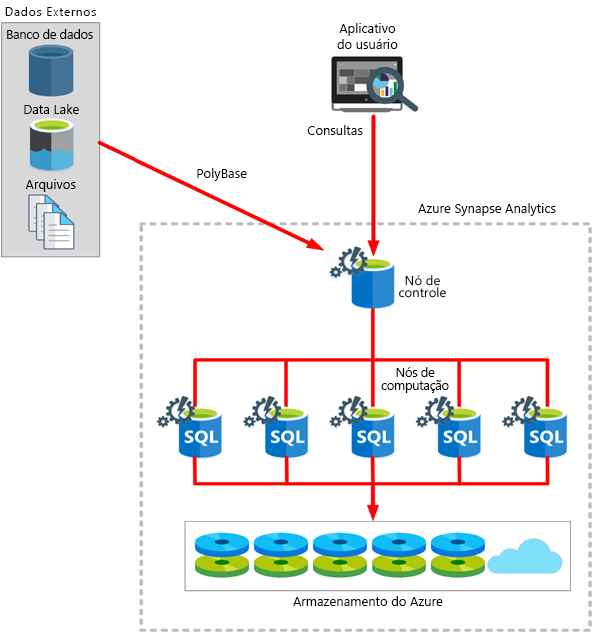
O nó de controle é o cérebro da arquitetura. É o front-end que interage com todas as aplicações. Os nós de computação conferem capacidade de computação. Os dados a serem processados são distribuídos uniformemente entre os nós.
As consultas são submetidas no formato de instruções Transact-SQL e o Azure Synapse Analytics executa-as.
O Azure Synapse usa uma tecnologia chamada PolyBase que permite recuperar e consultar dados de fontes relacionais e não relacionais. Você pode salvar os dados lidos como tabelas SQL dentro do serviço Azure Synapse.

Componentes do Azure Synapse Analytics
O Azure Synapse Analytics é composto pelos cinco elementos:
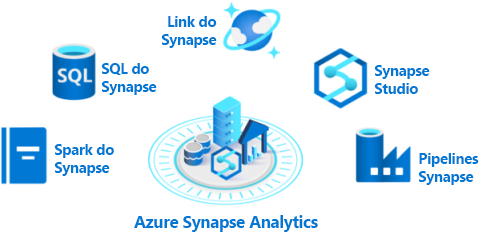
- Pool SQL do Azure Synapse: o Synapse SQL oferece modelos de recursos dedicados e sem servidor para trabalhar com uma arquitetura baseada em nó. Para um desempenho e custo previsíveis, você pode criar pools SQL dedicados. Para cargas de trabalho irregulares ou não planejadas, você pode usar o ponto de extremidade SQL sempre disponível e sem servidor.
- Pool do Azure Synapse Spark: este pool é um cluster de servidores que executam o Apache Spark para processar dados. Você escreve sua lógica de processamento de dados usando uma das quatro linguagens suportadas: Python, Scala, SQL e C# (via .NET para Apache Spark). O Apache Spark for Azure Synapse integra o Apache Spark (o mecanismo de big data de código aberto usado para preparação de dados, engenharia de dados, ETL e aprendizado de máquina).
- Azure Synapse Pipelines: O Azure Synapse Pipelines aplica os recursos do Azure Data Factory. Pipelines são o ETL baseado em nuvem e serviço de integração de dados que permite criar fluxos de trabalho orientados por dados para orquestrar a movimentação de dados e transformar dados em escala. Você pode incluir atividades que transformam os dados à medida que são transferidos ou pode combinar dados de várias fontes juntos.
- Azure Synapse Link: Este componente permite que você se conecte ao Azure Cosmos DB. Você pode usá-lo para executar análises quase em tempo real sobre os dados operacionais armazenados em um banco de dados do Azure Cosmos DB.
- Azure Synapse Studio: Este elemento é um IDE baseado na Web que pode ser usado centralmente para trabalhar com todos os recursos do Azure Synapse Analytics. Você pode usar o Azure Synapse Studio para criar pools SQL e Spark, definir e executar pipelines e configurar links para fontes de dados externas.
Opções analíticas
O Azure Synapse Analytics dá suporte a uma variedade de cenários analíticos. Ao analisar a tabela, considere como os cenários se aplicam à organização Tailwind Traders.
| Análise | Cenário | Description |
|---|---|---|
| Descritivo | O que é que está a acontecer? | O Azure Synapse aplica o recurso de pool SQL dedicado que permite criar um data warehouse persistente para analisar o que agora questiona. Você pode usar o pool SQL sem servidor para preparar dados de arquivos armazenados em um data lake para criar um data warehouse interativamente. |
| Diagnóstico | Por que isso está acontecendo? | Você pode usar o recurso de pool SQL sem servidor no Azure Synapse para explorar dados interativamente em um data lake. Os pools SQL sem servidor podem permitir rapidamente que um usuário pesquise outros dados que possam ajudá-lo a entender por que as perguntas. |
| Preditivo | O que é provável que aconteça? | O Azure Synapse Analytics usa seu mecanismo Apache Spark integrado e pools do Azure Synapse Spark para análise preditiva. Ele combina essa ação com outros serviços, como os Serviços de Aprendizado de Máquina do Azure e o Azure Databricks para ajudá-lo a responder a perguntas futuras . |
| Prescritivo | O que é necessário fazer? | Você pode usar análises prescritivas em tempo real ou quase dados em tempo real para ajudá-lo a identificar soluções para suas perguntas de ação . O Azure Synapse Analytics fornece esse recurso por meio do Apache Spark e do Azure Synapse Link e da integração de tecnologias de streaming, como o Azure Stream Analytics. |
Cenário de negócio
Vamos examinar um cenário em que a empresa está atendendo os clientes com informações do mercado de ações. Você precisa fornecer uma combinação de processamento em lote e fluxo para dar suporte à infraestrutura da Tailwind Traders. Os dados atualizados podem ser usados para ajudar a monitorar o tempo real, onde uma decisão instantânea é necessária para tomar decisões informadas de compra ou venda em frações de segundo. Os dados históricos são igualmente importantes para uma visão das tendências de desempenho. Que tipo de armazém de dados e solução de integração de dados você recomendaria para fornecer acesso aos fluxos de dados brutos e às informações de negócios preparadas derivadas desses dados? Com o Azure Synapse Analytics, você pode ingerir dados de fontes externas e, em seguida, transformar e agregar esses dados em um formato adequado para processamento de análises.
Coisas a considerar ao escolher o Azure Data Factory ou o Azure Synapse Analytics
A tabela a seguir compara os critérios da solução de armazenamento para usar o Azure Data Factory versus o Azure Synapse Analytics. Analise os critérios e considere qual solução é ideal para os Tailwind Traders.
| Comparar | Azure Data Factory | Azure Synapse Analytics |
|---|---|---|
| Partilha de dados | Os dados podem ser compartilhados entre diferentes fábricas de dados | Não suportado |
| Modelos de solução | Os modelos de solução são fornecidos com a galeria de modelos do Azure Data Factory | Os modelos de solução são fornecidos no Centro de conhecimento do Synapse Workspace |
| Fluxos entre regiões do tempo de execução da integração | Há suporte para fluxos de dados entre regiões | Não suportado |
| Monitorar dados | O monitoramento de dados é integrado ao Azure Monitor | Os logs de diagnóstico estão disponíveis no Azure Monitor |
| Monitorar trabalhos do Spark para fluxo de dados | Não suportado | Os Spark Jobs podem ser monitorados quanto ao fluxo de dados usando pools Synapse Spark |
O Azure Synapse Analytics é uma solução ideal para muitos outros cenários. Considere as seguintes opções:
- Considere a variedade de fontes de dados. Quando você tem várias fontes de dados que usam o Azure Synapse Analytics para ETL sem código e atividades de fluxo de dados.
- Considere o Machine Learning. Quando precisar implementar soluções de Machine Learning usando o Apache Spark, você poderá usar o Azure Synapse Analytics para suporte interno para o Azure Machine Learning.
- Considere a integração do data lake. Quando você tem dados existentes armazenados em um data lake e precisa de integração com o Azure Data Lake e outras fontes de entrada, o Azure Synapse Analytics fornece integração perfeita entre os dois componentes.
- Considere análises em tempo real. Quando você precisa de análises em tempo real, pode usar recursos como o Azure Synapse Link para analisar dados em tempo real e oferecer insights.