Descrever métricas críticas de desempenho
Você viu sobre como coletar dados no Monitor do Azure e no Monitor de Desempenho do Windows. Agora você aprenderá como criar métricas no Azure Monitor, que permitem disparar alertas ou executar respostas de erro automatizadas.
Revisão das métricas do Azure
O serviço Azure Monitor inclui a capacidade de controlar várias métricas sobre a integridade geral de um determinado recurso. As métricas são reunidas em intervalos regulares e são a porta de entrada para processos de alerta que ajudarão a resolver problemas de forma rápida e eficiente. O Azure Monitor Metrics é um subsistema poderoso que permite não apenas analisar e visualizar seus dados de desempenho, mas também disparar alertas que notificam administradores ou ações automatizadas que podem acionar um runbook de Automação do Azure ou um webhook. Você também tem a opção de arquivar seus dados do Azure Metrics no Armazenamento do Azure, já que os dados ativos são armazenados apenas por 93 dias.
Criar alertas de métricas
Utilizando o portal do Azure, você pode criar regras de alerta, com base em métricas definidas, na seção de visão geral da folha Azure Monitor. Os Alertas do Azure Monitor podem ter um escopo de três maneiras. Por exemplo, usando as Máquinas Virtuais do Azure como exemplo, você pode especificar o escopo como:
Uma lista de máquinas virtuais em uma região do Azure dentro de uma assinatura
Todas as máquinas virtuais (em uma região do Azure) em um ou mais grupos de recursos em uma assinatura
Todas as máquinas virtuais (em uma região do Azure) em uma assinatura
Dessa maneira, você pode criar uma regra de alerta com base nos recursos contidos nos grupos de recursos, conforme mostrado.
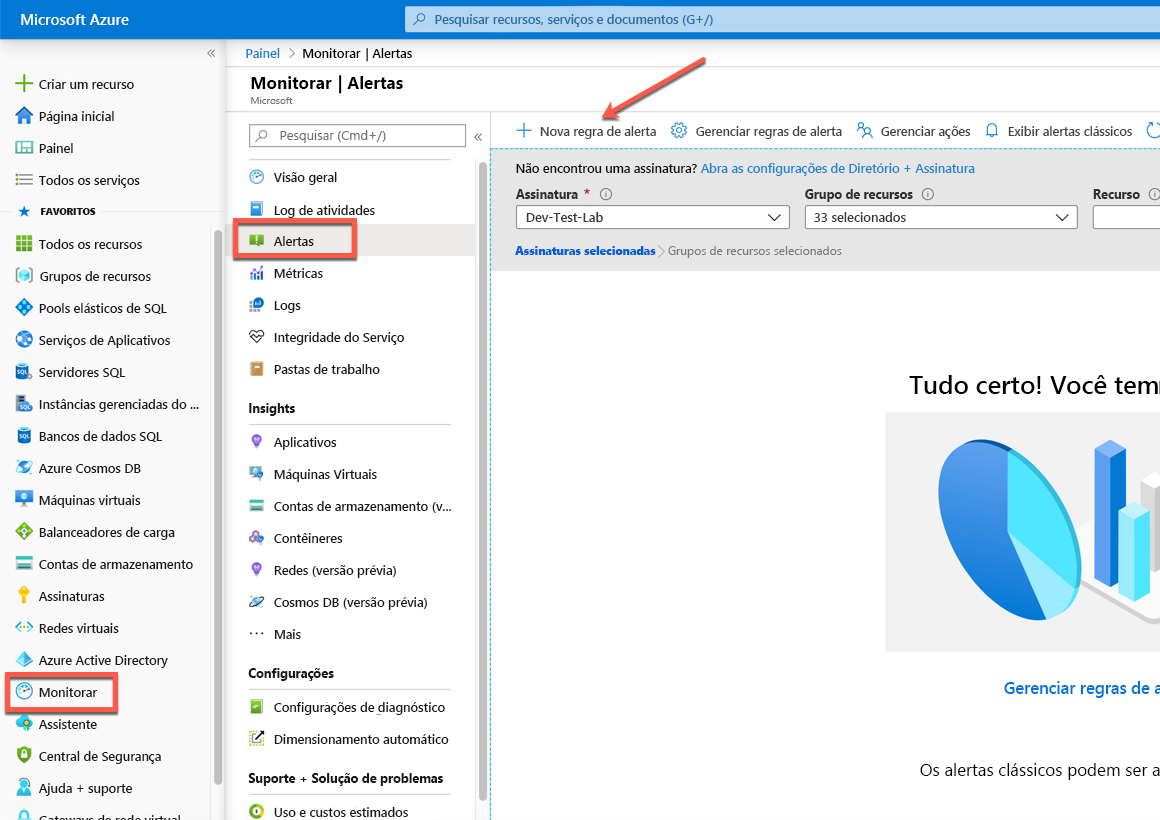
O exemplo mostrado abaixo reflete uma máquina virtual chamada SQL2019 na qual estamos criando um alerta que está no escopo da máquina virtual individual.
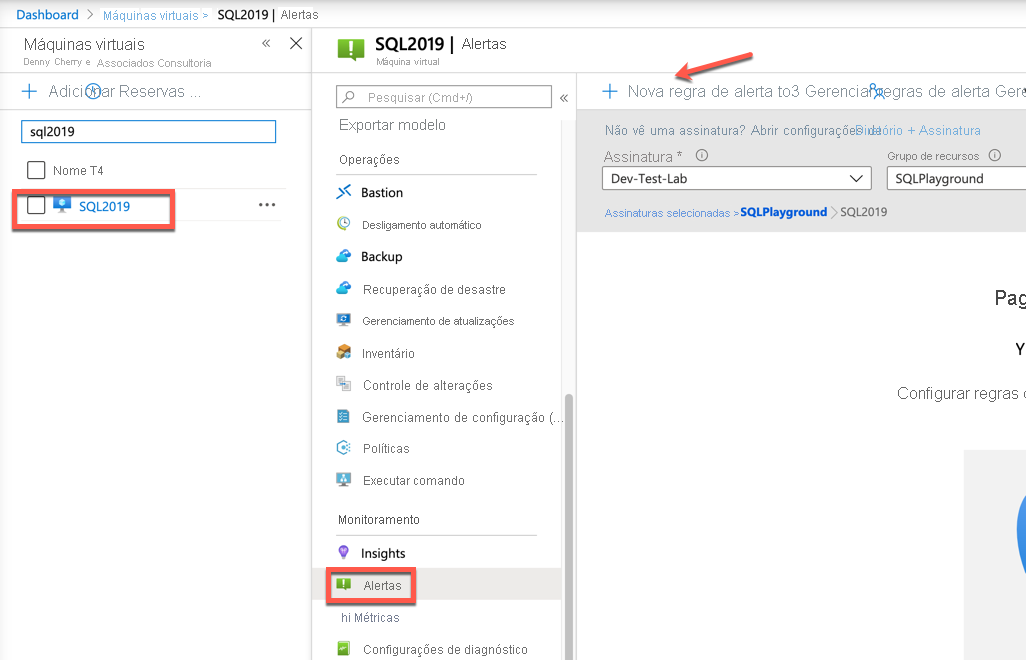
Independentemente do âmbito do alerta, o processo de criação é o mesmo.
Na tela de alertas, clique em Nova regra de alerta. Se um alerta for criado a partir do escopo de um recurso, os valores do recurso deverão ser preenchidos para você. Você pode ver que o recurso é a máquina virtual SQL2019, a assinatura é Dev-Test-Lab e o grupo de recursos no qual reside é SQLPlayground.
Na seção Condição, clique em Adicionar:
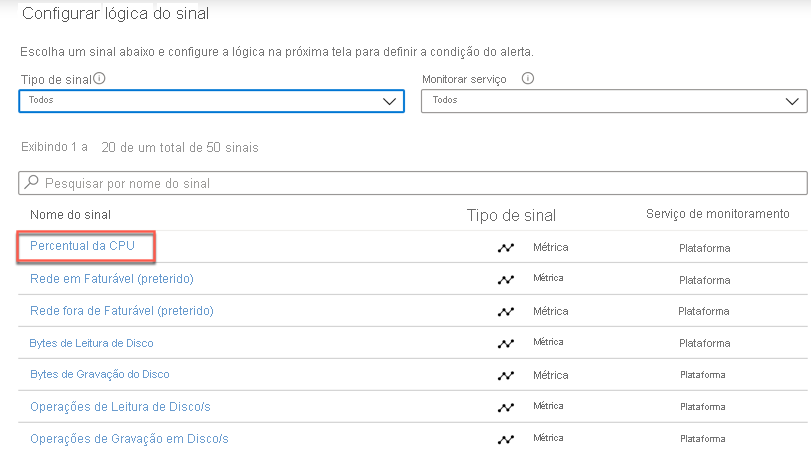
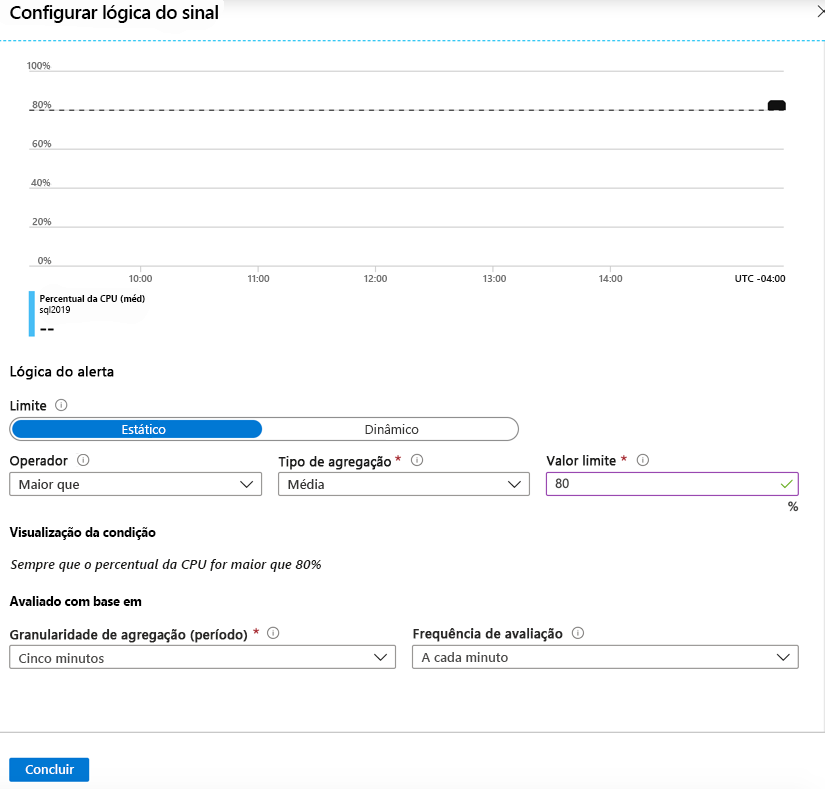
Selecione a métrica sobre a qual deseja alertar. A imagem a seguir mostra a porcentagem de CPU, que você verá selecionada.
Os alertas podem ser configurados de forma estática (por exemplo, gerar um alerta quando a CPU ultrapassa 95%) ou de forma dinâmica usando Limites Dinâmicos. Os Limiares Dinâmicos aprendem o comportamento histórico da métrica e emitem um alerta quando os recursos estão operando de maneira anormal. Esses limites dinâmicos podem detetar sazonalidade em suas cargas de trabalho e ajustar o alerta de acordo.
Se forem usados alertas estáticos, você deverá fornecer um limite para a métrica selecionada. Neste exemplo, 80% foi especificado. Esse limite significa que, se a utilização da CPU exceder 80% em um determinado período, um alerta será disparado e reagirá conforme especificado.
Ambos os tipos de alertas oferecem aos operadores booleanos, tais como os operadores «maior que» ou «menos que». Junto com os operadores booleanos, há medidas agregadas para selecionar, como média, mínimo, máximo, contagem, média e total. Com essas opções disponíveis, é fácil criar um alerta flexível que se adapte a praticamente qualquer alerta de nível empresarial.
Depois de criar o alerta, para notificar os administradores ou iniciar um processo de automação, um grupo de ações precisa ser configurado.
Nota
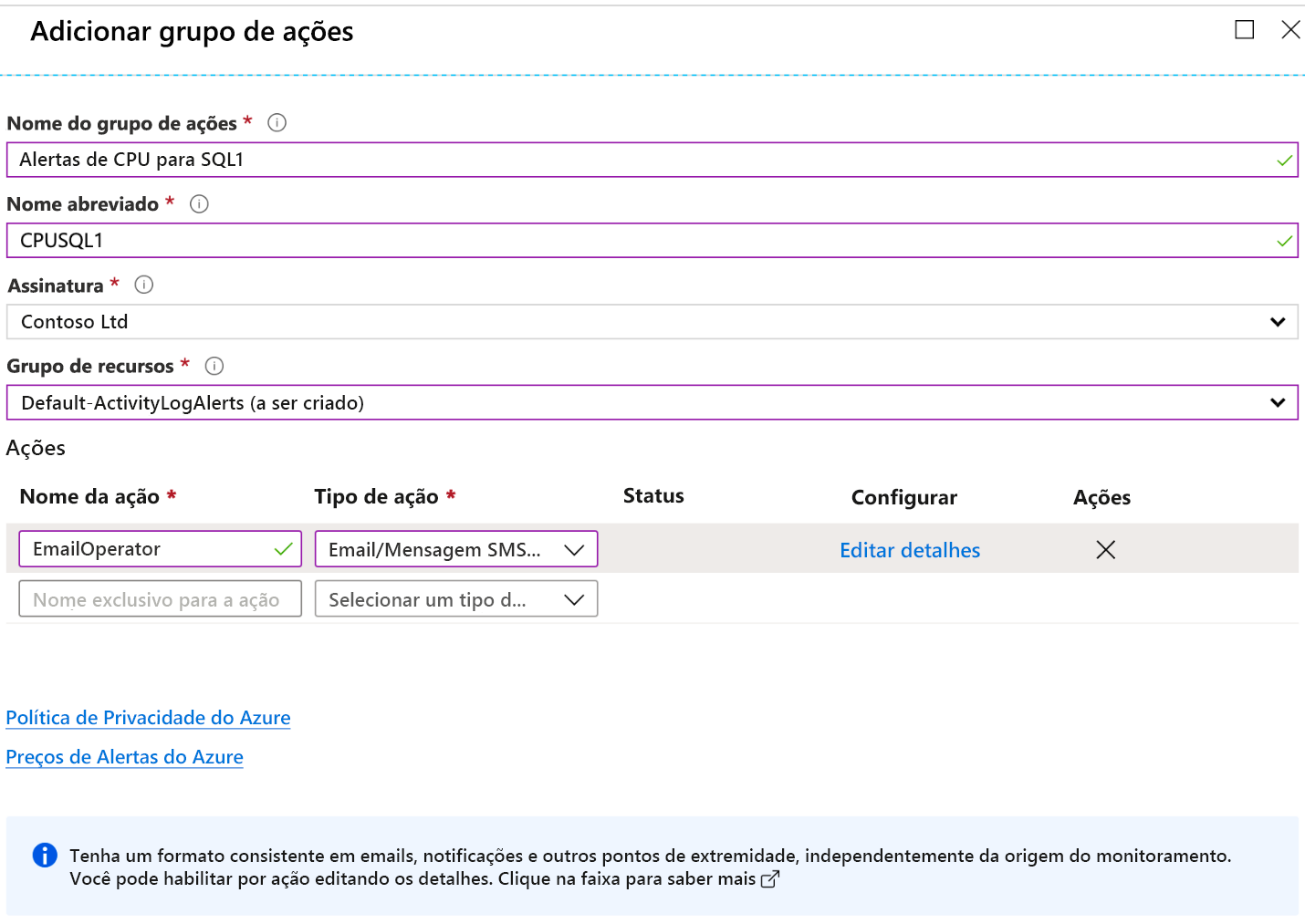
A definição de um grupo de ações é opcional e, se um não estiver configurado, o alerta apenas registrará a notificação no armazenamento, sem que nenhuma ação adicional seja executada. Você pode criar um novo grupo de ações na tela de métricas, clicando em Adicionar ao lado de Grupos de Ação. Em seguida, você verá esta caixa de diálogo:

Depois de clicar em Criar grupo de ação, você verá a tela mostrada abaixo. Você nomeará o grupo de ação e definirá um alerta e a resposta. Neste exemplo, o administrador será enviado por e-mail caso a condição do alerta seja acionada.
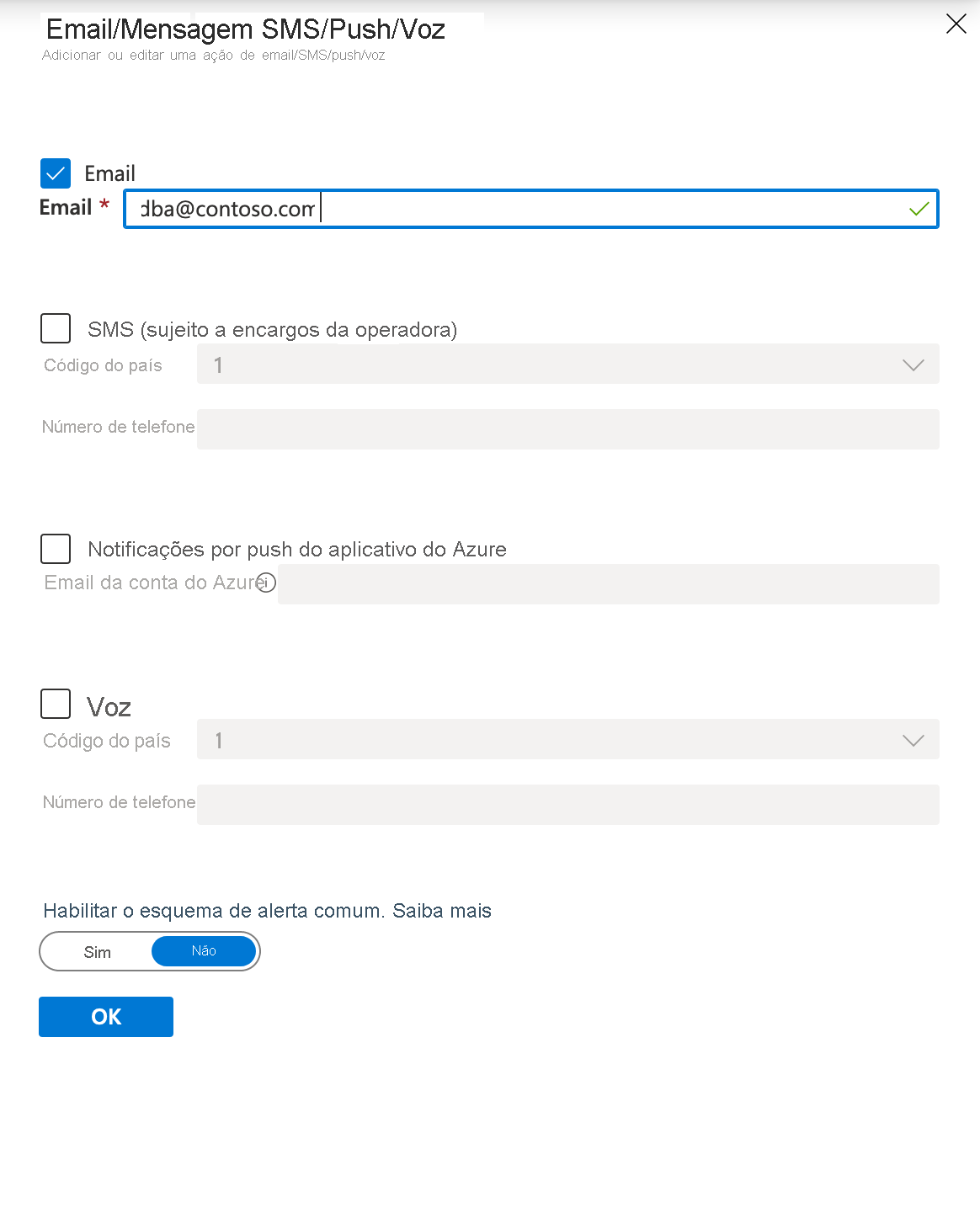
Você pode configurar os detalhes do e-mail ou SMS como pode ser visto abaixo. Você pode acessar essa tela clicando em Editar detalhes em Configurar ou adicionando uma nova ação, que também abrirá a tela de configuração.
Com um grupo de ação, há várias maneiras de responder ao alerta. As seguintes opções estão disponíveis para definir a ação a ser tomada:
- Runbook de Automatização
- Função do Azure
- E-mail da Função do Azure Resource Manager
- E-mail/SMS/Push/Voz
- ITSM
- Aplicação Lógica do Azure
- Webhook Seguro
- Webhook
Há duas categorias para essas ações: notificação, que significa notificar um administrador ou grupo de administradores de um evento, e automação, que está executando uma ação definida para responder a uma condição de desempenho.
Rever dados de desempenho mais antigos
Um dos benefícios de utilizar o Azure Monitor é a capacidade de revisar de forma fácil e rápida as métricas anteriores que foram coletadas. Se você examinar um recurso, anotará um seletor de data/hora no canto superior direito. As Métricas do Azure Monitor serão mantidas por 93 dias, após os quais serão limpas, no entanto, você tem a opção de arquivá-las no Armazenamento do Azure.
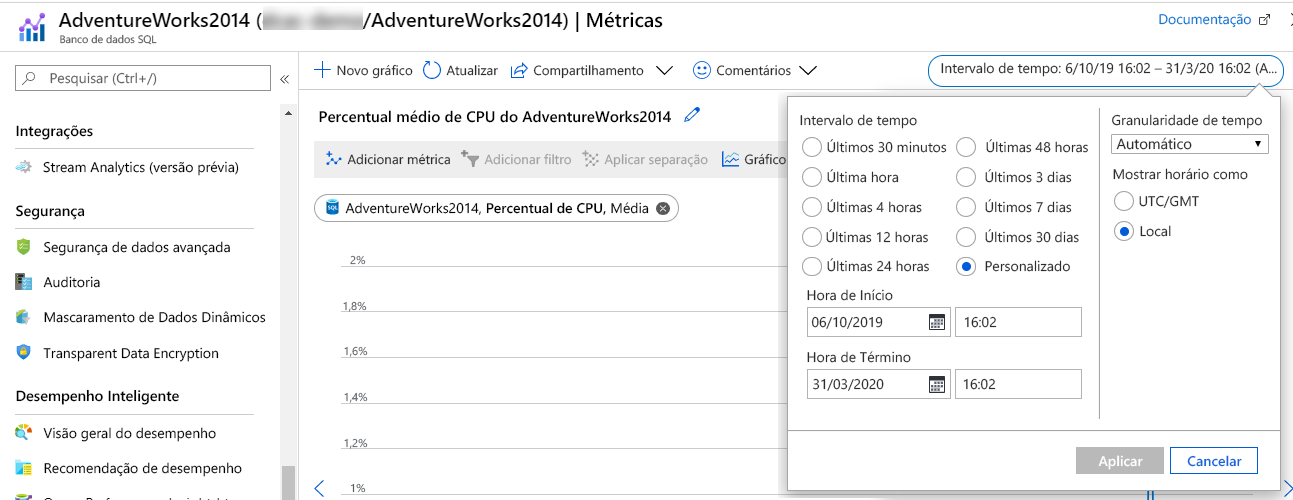
Você também pode selecionar uma janela de tempo menor, como os últimos 30 minutos, última hora, últimas 4 horas ou últimas 12 horas, como exemplo. A flexibilidade do monitor do Azure permite que os administradores identifiquem rapidamente problemas, bem como potencialmente diagnostiquem problemas passados.
Métricas importantes do SQL Server
O Microsoft SQL Server é um software bem instrumentado que coleta uma grande quantidade de metadados de desempenho. O mecanismo de banco de dados tem métricas que podem ser monitoradas para ajudar a identificar e melhorar problemas relacionados ao desempenho. Algumas métricas do sistema operacional só podem ser visualizadas no monitor de desempenho, enquanto outras podem ser acessadas por meio de consultas T-SQL, em particular, selecionando entre as exibições de gerenciamento dinâmico (DMVs). Existem algumas métricas que são expostas em ambos os locais, portanto, saber onde identificar métricas específicas é importante. Um exemplo de dados que só podem ser capturados de DMVs é a latência de leitura/gravação de dados e arquivos de log de transações, conforme exposto em sys.dm_os_volume_stats. Por outro lado, um exemplo de uma métrica do sistema operacional que não está disponível diretamente por meio do SQL Server são os segundos por disco lidos e gravados para o volume do disco. A combinação dessas duas métricas pode ajudá-lo a entender melhor se um problema de desempenho está relacionado à estrutura do banco de dados ou a um gargalo de armazenamento físico.