Executar carga de trabalho de inferência no NVIDIA Triton Inference Server
Agora estamos prontos para executar o script Python de exemplo no Triton Server. Se você olhar no demo diretório, verá uma coleção de pastas e arquivos.
demo/app Na pasta, há dois scripts Python. O primeiro, frame_grabber.py usa o Triton Inference Server. O segundo, frame_grabber_onnxruntime.py pode ser usado de forma independente. A utils pasta dentro do app diretório contém scripts Python para permitir a interpretação do tensor de saída do modelo.
Ambos os scripts Python são definidos para observar o image_sink diretório para quaisquer arquivos de imagem que são colocados lá. images-sampleNo , você encontra uma coleção de imagens que copiamos via linha de comando para o para processamentoimage_sink. Os scripts Python excluem automaticamente os arquivos do image_sink após a conclusão da inferência.
model-repo Na pasta, você encontra uma pasta para o nome do modelo (gtc_onnx), que contém o arquivo de configuração do modelo para o servidor Triton Inference e o arquivo de rótulo. Também está incluída uma pasta que indica a versão do modelo, que contém o modelo Open Neural Network Exchange (ONNX) que o servidor usa para inferência.
Se o modelo detetar os objetos nos quais treinou, o script Python criará uma anotação dessa inferência com uma caixa delimitadora, nome da marca e pontuação de confiança. O script salva a imagem na pasta com um nome exclusivo usando um carimbo images-annotated de data/hora, que podemos baixar para visualizar localmente. Dessa forma, você pode copiar as mesmas imagens repetidamente para o image_sink mas ter novas imagens anotadas criadas a cada execução para fins de ilustração.
Executar uma carga de trabalho de inferência no NVIDIA Triton Inference Server
Para começar a inferir, queremos abrir duas janelas no Terminal do Windows e
sshna máquina virtual de cada janela.Na primeira janela, execute o seguinte comando, mas primeiro altere o espaço reservado do <seu nome> de usuário com seu nome de usuário para a máquina virtual:
sudo docker run --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --rm -p8000:8000 -p8002:8002 -v/home/<your username>/demo/model-repo:/models nvcr.io/nvidia/tritonserver:20.11-py3 tritonserver --model-repository=/modelsNa segunda janela, copie o seguinte comando, alterando <seu nome> de usuário para seu valor, e defina o< limite> de probabilidade para o nível de confiança desejado entre 0 e 1. Por padrão, esse valor é definido como 0,6.
python3 demo/app/frame_grabber.py -u <your username> -p .07Na terceira janela, copie e cole este comando para copiar os arquivos de imagem da
images_samplepasta para aimage_sinkpasta:cp demo/images_sample/* demo/image_sink/Se você voltar para sua segunda janela, você pode ver a execução do modelo, incluindo as estatísticas do modelo e a inferência retornada na forma de um dicionário Python.
Aqui está uma exibição de exemplo do que você deve ver na segunda janela à medida que o script é executado:
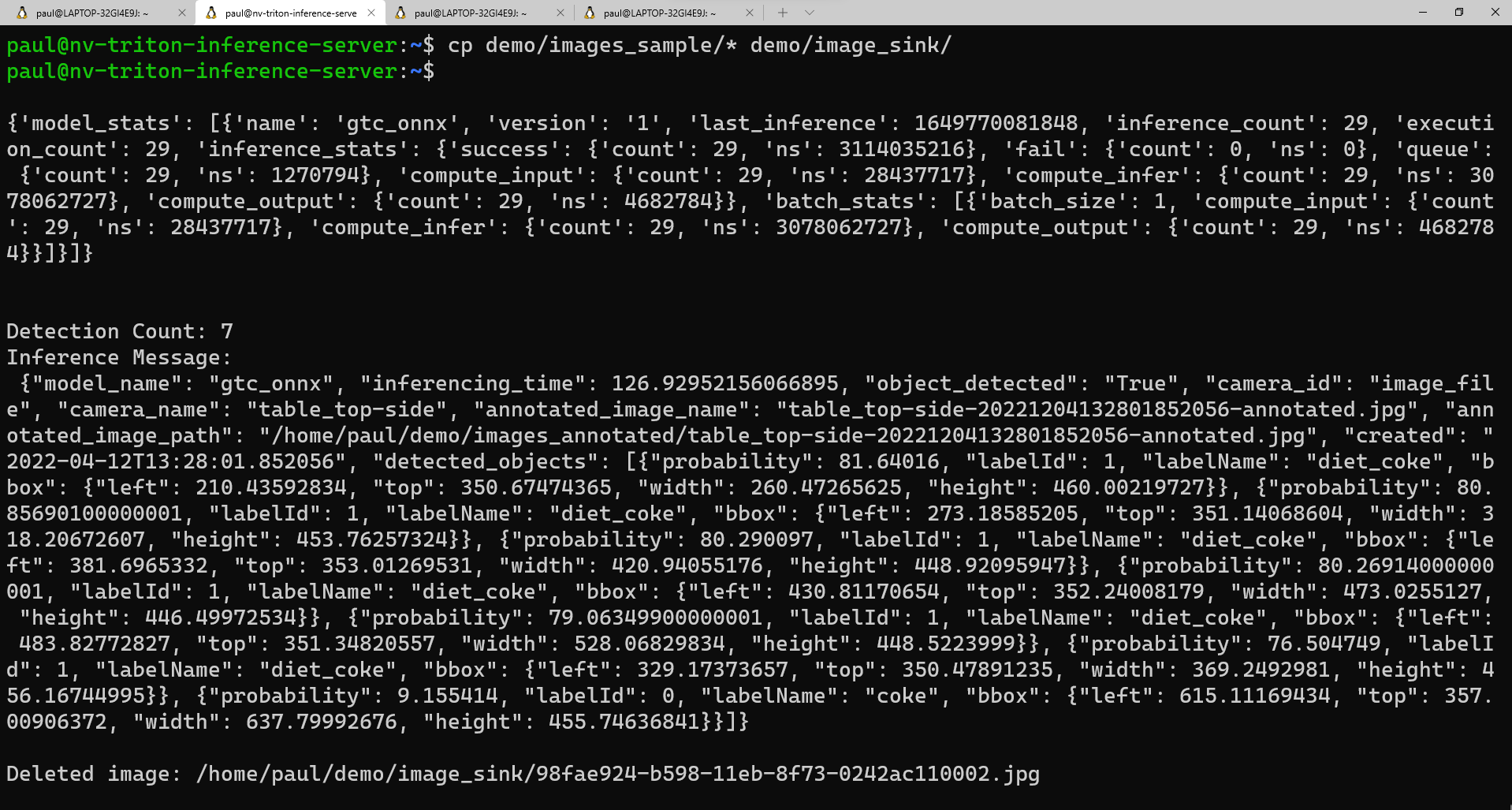
Se quiser ver uma lista das suas imagens anotadas, pode executar este comando:
ls demo/annotated_imagesPara fazer o download das imagens para a sua máquina local, primeiro queremos criar uma pasta para receber as imagens. Em uma janela de linha de comando,
cdpara o diretório no qual você deseja colocar a nova pasta e execute:mkdir annotated_img_download scp <your usename>@x.x.x.x:/home/<your username>/demo/images_annotated/* annotated_img_download/Este comando copia todos os arquivos da máquina virtual Ubuntu para o seu dispositivo local para visualização.
