Compreender os conceitos de aprendizagem profunda
No cérebro, temos células nervosas chamadas neurónios, que estão ligadas entre si por extensões nervosas que passam sinais eletroquímicos através da rede.

Quando o primeiro neurônio da rede é estimulado, o sinal de entrada é processado e, se exceder um determinado limiar, o neurônio é ativado e passa o sinal para os neurônios aos quais está conectado. Estes neurónios, por sua vez, podem ser ativados e passar o sinal através do resto da rede. Ao longo do tempo, as conexões entre os neurônios são fortalecidas pelo uso frequente à medida que você aprende a responder de forma eficaz. Por exemplo, se lhe for mostrada uma imagem de um pinguim, as suas ligações neuronais permitem-lhe processar a informação na imagem e o seu conhecimento das características de um pinguim para o identificar como tal. Com o tempo, se forem mostradas várias imagens de vários animais, a rede de neurónios envolvidos na identificação de animais com base nas suas características torna-se mais forte. Em outras palavras, você fica melhor em identificar com precisão diferentes animais.
A aprendizagem profunda emula esse processo biológico usando redes neurais artificiais que processam entradas numéricas em vez de estímulos eletroquímicos.
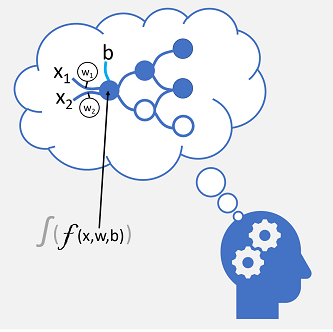
As conexões nervosas de entrada são substituídas por entradas numéricas que são tipicamente identificadas como x. Quando há mais de um valor de entrada, x é considerado um vetor com elementos chamados x 1, x 2 e assim por diante.
Associado a cada valor x está um peso (w), que é usado para fortalecer ou enfraquecer o efeito do valor x para simular a aprendizagem. Além disso, uma entrada de viés (b) é adicionada para permitir um controle refinado sobre a rede. Durante o processo de treinamento, os valores w e b são ajustados para ajustar a rede para que ela "aprenda" a produzir saídas corretas.
O próprio neurônio encapsula uma função que calcula uma soma ponderada de x, w e b. Esta função, por sua vez, é encerrada em uma função de ativação que restringe o resultado (muitas vezes a um valor entre 0 e 1) para determinar se o neurônio passa ou não uma saída para a próxima camada de neurônios na rede.
Treinando um modelo de aprendizagem profunda
Os modelos de aprendizagem profunda são redes neurais que consistem em várias camadas de neurónios artificiais. Cada camada representa um conjunto de funções que são executadas nos valores x com pesos w associados e vieses b, e a camada final resulta em uma saída do rótulo y que o modelo prevê. No caso de um modelo de classificação (que prevê a categoria ou classe mais provável para os dados de entrada), a saída é um vetor que contém a probabilidade para cada classe possível.
O diagrama a seguir representa um modelo de aprendizado profundo que prevê a classe de uma entidade de dados com base em quatro recursos (os valores x). A saída do modelo (os valores y ) é a probabilidade para cada um dos três rótulos de classe possíveis.
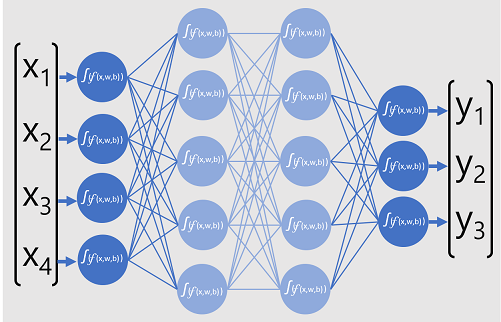
Para treinar o modelo, uma estrutura de aprendizagem profunda alimenta vários lotes de dados de entrada (para os quais os valores reais do rótulo são conhecidos), aplica as funções em todas as camadas de rede e mede a diferença entre as probabilidades de saída e os rótulos de classe conhecidos reais dos dados de treinamento. A diferença agregada entre as saídas de previsão e os rótulos reais é conhecida como perda.
Tendo calculado a perda agregada para todos os lotes de dados, a estrutura de aprendizagem profunda usa um otimizador para determinar como os pesos e vieses no modelo devem ser ajustados para reduzir a perda geral. Esses ajustes são então retropropagados para as camadas no modelo de rede neural e, em seguida, os dados são passados pela rede novamente e a perda recalculada. Este processo repete-se várias vezes (cada iteração é conhecida como uma época) até que a perda seja minimizada e o modelo tenha "aprendido" os pesos e enviesamentos certos para ser capaz de prever com precisão.
Durante cada época, os pesos e vieses são ajustados para minimizar a perda. O valor pelo qual eles são ajustados é regido pela taxa de aprendizado especificada para o otimizador. Se a taxa de aprendizagem for muito baixa, o processo de treinamento pode levar muito tempo para determinar os valores ideais; Mas se for muito alto, o otimizador pode nunca encontrar os valores ideais.