Usar a API de conversão de texto em fala
Da mesma forma que suas APIs de fala para texto , o serviço Azure AI Speech oferece outras APIs REST para síntese de fala:
- A API de conversão de texto em fala , que é a principal maneira de realizar a síntese de fala.
- A API de síntese em lote, que é projetada para suportar operações em lote que convertem grandes volumes de texto em áudio - por exemplo, para gerar um audiolivro a partir do texto de origem.
Você pode saber mais sobre as APIs REST na documentação da API REST de texto para fala. Na prática, a maioria dos aplicativos habilitados para fala interativos usa o serviço de Fala do Azure AI por meio de um SDK específico de linguagem (de programação).
Usando o SDK de Fala do Azure AI
Assim como acontece com o reconhecimento de fala, na prática, a maioria dos aplicativos habilitados para fala interativos são criados usando o SDK de Fala do Azure AI.
O padrão para implementar a síntese de fala é semelhante ao do reconhecimento de fala:
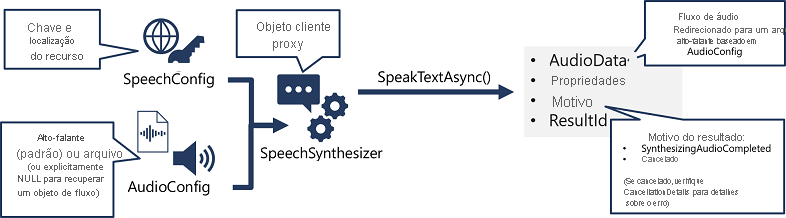
- Use um objeto SpeechConfig para encapsular as informações necessárias para se conectar ao seu recurso Azure AI Speech. Especificamente, a sua localização e chave.
- Opcionalmente, use um AudioConfig para definir o dispositivo de saída para a fala a ser sintetizada. Por padrão, esse é o alto-falante padrão do sistema, mas você também pode especificar um arquivo de áudio ou, definindo explicitamente esse valor como um valor nulo, você pode processar o objeto de fluxo de áudio que é retornado diretamente.
- Use o SpeechConfig e AudioConfig para criar um objeto SpeechSynthesizer. Este objeto é um cliente proxy para a API de conversão de texto em fala .
- Use os métodos do objeto SpeechSynthesizer para chamar as funções subjacentes da API. Por exemplo, o método SpeakTextAsync() usa o serviço Azure AI Speech para converter texto em áudio falado.
- Processe a resposta do serviço Azure AI Speech. No caso do método SpeakTextAsync , o resultado é um objeto SpeechSynthesisResult que contém as seguintes propriedades:
- AudioData
- Propriedades
- Razão
- ResultId
Quando a fala foi sintetizada com êxito, a propriedade Reason é definida como a enumeração SynthesizingAudioCompleted e a propriedade AudioData contém o fluxo de áudio (que, dependendo do AudioConfig pode ter sido enviado automaticamente para um alto-falante ou arquivo).