Exercício - Usar dados de disputa do Azure Data Factory
A funcionalidade Power Query no Azure Data Factory permite-lhe trabalhar com dados e articulá-los. É um objeto que pode ser adicionado ao designer de tela como uma atividade em um pipeline do Azure Data Factory para executar a preparação de dados sem código. Ele permite que indivíduos que não estão familiarizados com as tecnologias tradicionais de preparação de dados, como Spark ou SQL Server, e linguagens como Python e T-SQL preparem dados em escala de nuvem iterativamente.
A funcionalidade Power Query utiliza uma interface de tipo de grelha para preparação básica de dados que é semelhante à estética do Excel, conhecida como Editor de Mashup Online. O editor também permite que usuários mais avançados executem a preparação de dados mais complexos usando fórmulas. Primeiro, você precisa criar um serviço vinculado a uma fonte de dados antes de poder acessar os dados
As fórmulas funcionam com o Power Query Online e disponibilizam as funções do Power Query M para utilizadores do data factory. Em seguida, o Power Query traduz a linguagem M gerada pelo Editor de Mashup Online em código spark para execução em escala de nuvem.
Esse recurso permite que engenheiros de dados e analistas de dados explorem e preparem conjuntos de dados de forma interativa. Além disso, eles podem trabalhar interativamente com a linguagem M e visualizar o resultado antes de visualizá-lo no contexto de um pipeline mais amplo.
Para adicionar uma atividade do Power Query no Azure Data Factory, clique no ícone de adição e selecione Power Query no painel de recursos de fábrica.

Adicione um conjunto de dados de origem para seu fluxo de dados de disputa e selecione um conjunto de dados de coletor. As seguintes fontes de dados são suportadas.
| Conector | Formato dos dados | Authentication type |
|---|---|---|
| Armazenamento de Blobs do Azure | CSV, Parquet | Chave de Conta |
| Armazenamento do Azure Data Lake Ger1 | CSV | Principal de Serviço |
| Azure Data Lake Storage Gen2 | CSV, Parquet | Chave de conta, Entidade de serviço |
| Base de Dados SQL do Azure | Autenticação do SQL | |
| Azure Synapse Analytics | Autenticação do SQL |
Depois de selecionar uma fonte, clique em criar.

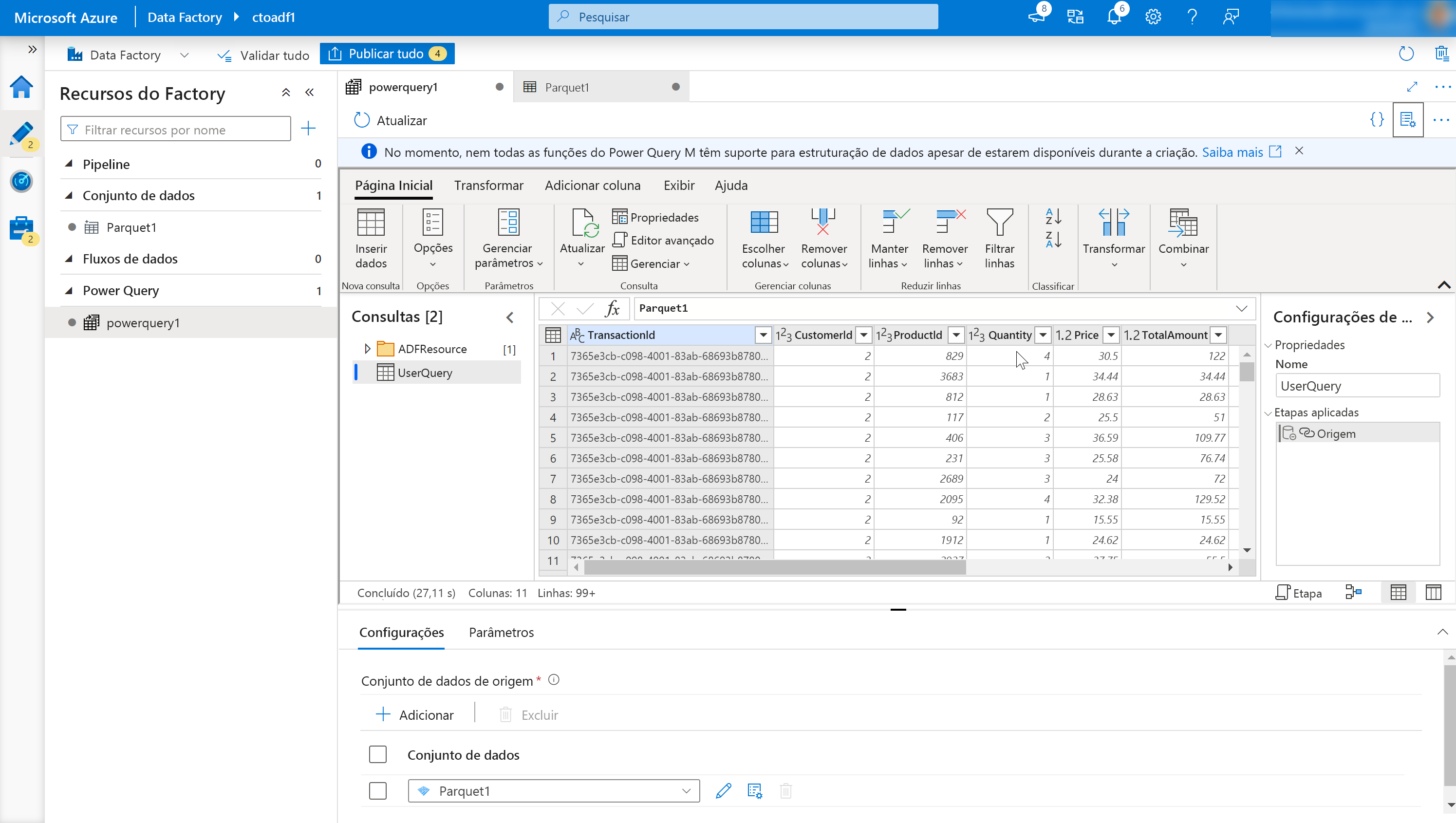
Isso abre o Editor de Mashup Online.

É composto pelos seguintes componentes:
Lista de conjuntos de dados.
Isso fornecerá os conjuntos de dados que foram definidos como a fonte para a disputa de dados.
Barra de ferramentas Função Wrangling.
A barra de ferramentas contém uma variedade de funções de disputa de dados que o usuário pode acessar para manipular os dados, incluindo:
- Gestão de colunas.
- Transformação de tabelas.
- Redução de linhas.
- Adicionar colunas.
- Combinação de tabelas.
Cada item é sensível ao contexto e contém subfunções específicas para ele.
Cabeçalhos de coluna.
Além de ter a capacidade de renomear colunas, clicar com o botão direito do mouse na coluna exibirá itens sensíveis ao contexto para gerenciar colunas.
Definições.
Isso permite que você adicione ou edite fontes de dados e coletores de dados e modifique a configuração para a tarefa de dados de disputa.
Janela de passos.
Esta janela mostra as etapas que foram aplicadas à saída de disputa. No exemplo no gráfico, a etapa chamada "Source" foi aplicada a saída wrangling chamada "UserQuery".
Lista de saída do Power Query.
Lista a saída de disputa de dados que foi definida.
Botão Publicar.
Permite publicar o trabalho que foi criado.
Uma tarefa do Power Query pode ser adicionada ao designer de telas tal como uma tarefa Copiar Atividade ou uma tarefa de Mapeamento de Fluxo de Dados e pode ser gerida e monitorizada da mesma forma.
