"Exercício - Criar um fluxo de dados de mapeamento do Azure Data Factory"
Transformando dados com o fluxo de dados de mapeamento
Você pode executar nativamente transformações de dados com o código do Azure Data Factory gratuitamente usando a tarefa Mapeando Fluxo de Dados. O mapeamento de fluxos de dados fornece uma experiência totalmente visual sem necessidade de codificação. Seus fluxos de dados serão executados em seu próprio cluster de execução para processamento de dados escalonado. As atividades de fluxo de dados podem ser operacionalizadas por meio dos recursos existentes de agendamento, controle, fluxo e monitoramento do Data Factory.
Ao criar fluxos de dados, você pode habilitar o modo de depuração, que ativa um pequeno cluster interativo do Spark. Ative o modo de depuração alternando o controle deslizante na parte superior do módulo de criação. Os clusters de depuração levam alguns minutos para aquecer, mas podem ser usados para visualizar interativamente a saída da sua lógica de transformação.

Com o Fluxo de Dados de Mapeamento adicionado e o cluster do Spark em execução, isso permitirá que você execute a transformação e execute e visualize os dados. Nenhuma codificação é necessária, pois o Azure Data Factory lida com toda a tradução de código, otimização de caminho e execução de seus trabalhos de fluxo de dados.
Adicionando dados de origem ao fluxo de dados de mapeamento
Abra a tela Mapeamento de fluxo de dados. Clique no botão Adicionar fonte na tela Fluxo de dados. No menu suspenso do conjunto de dados de origem, selecione sua fonte de dados, neste caso, o conjunto de dados ADLS Gen2 é usado neste exemplo
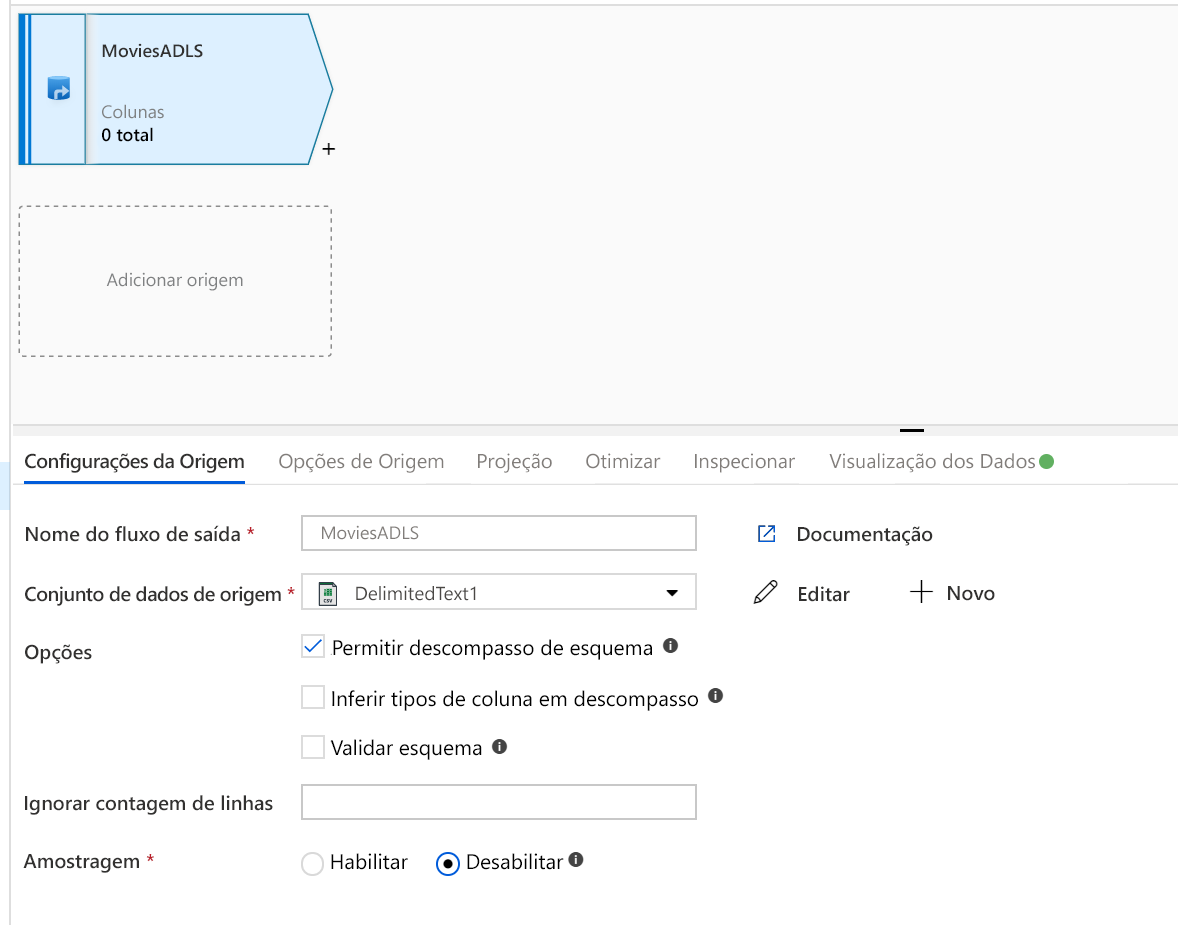
Há alguns pontos a observar:
- Se o conjunto de dados estiver apontando para uma pasta com outros arquivos e você quiser usar apenas um arquivo, talvez seja necessário criar outro conjunto de dados ou utilizar parametrização para garantir que apenas um arquivo específico seja lido
- Se você não importou seu esquema em seu ADLS, mas já ingeriu seus dados, vá para a guia 'Esquema' do conjunto de dados e clique em 'Importar esquema' para que seu fluxo de dados conheça a projeção do esquema.
O Mapeamento de Fluxo de Dados segue uma abordagem ELT (extrair, carregar, transformar) e funciona com conjuntos de dados de preparo que estão todos no Azure. Atualmente, os seguintes conjuntos de dados podem ser usados em uma transformação de origem:
- Azure Blob Storage (JSON, Avro, Texto, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Texto, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Texto, Parquet)
- Azure Synapse Analytics
- Base de Dados SQL do Azure
- Azure Cosmos DB
O Azure Data Factory tem acesso a mais de 80 conectores nativos. Para incluir dados dessas outras fontes em seu fluxo de dados, use a Atividade de cópia para carregar esses dados em uma das áreas de preparo suportadas.
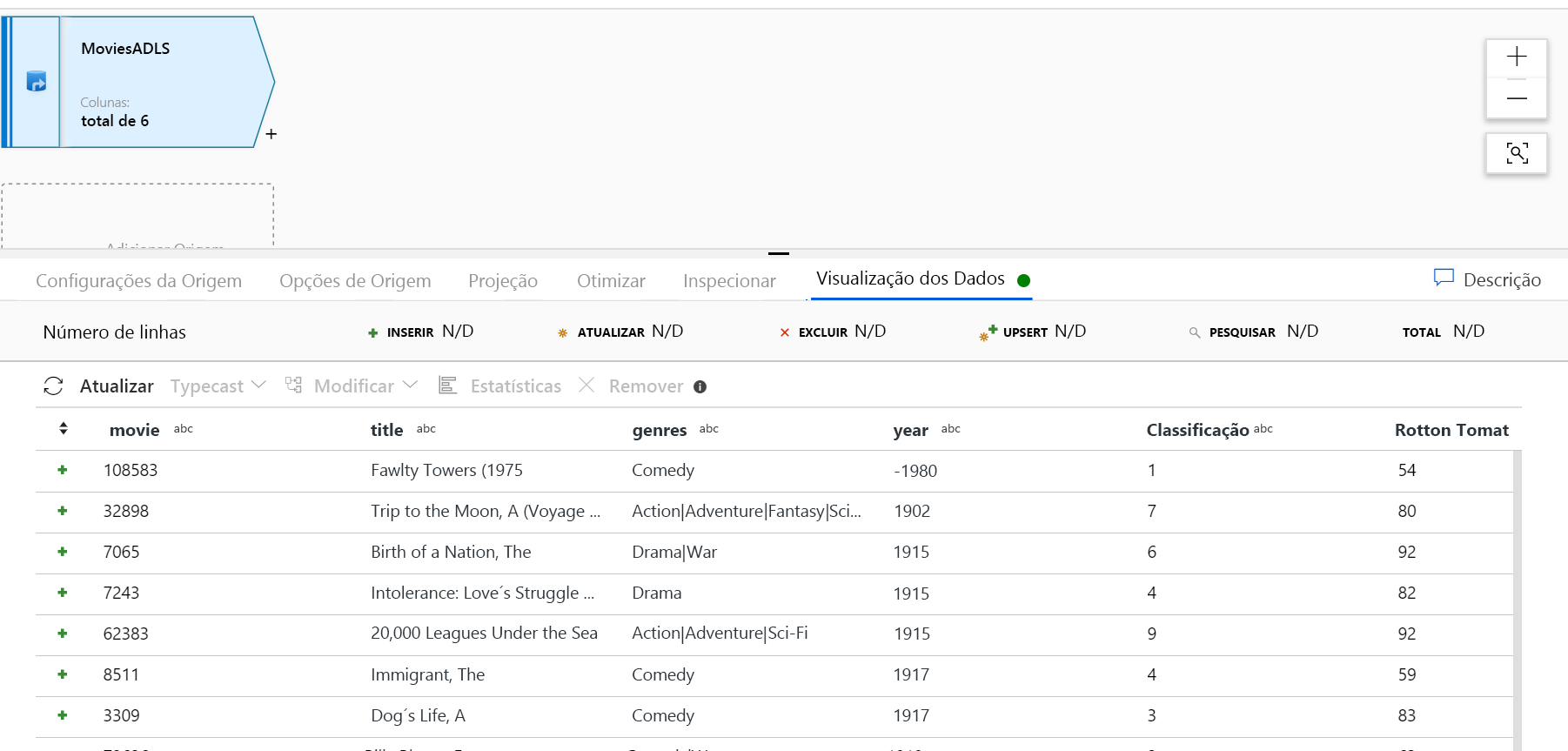
Depois que o cluster de depuração estiver aquecido, verifique se os dados foram carregados corretamente na guia Visualização de dados. Depois de clicar no botão de atualização, o Mapeamento de Fluxo de Dados mostrará um instantâneo da aparência dos dados em cada transformação.
Usando transformações no fluxo de dados de mapeamento
Agora que você moveu os dados para o Azure Data Lake Store Gen2, está pronto para criar um Fluxo de Dados de Mapeamento que transformará seus dados em escala por meio de um cluster de faísca e, em seguida, os carregará em um Data Warehouse.
As principais tarefas para o efeito são as seguintes:
Preparar o ambiente
Adicionando uma fonte de dados
Usando a transformação do fluxo de dados de mapeamento
Gravando em um coletor de dados
Tarefa 1: Preparar o ambiente
Ativar depuração de fluxo de dados Ative o controle deslizante de depuração de fluxo de dados localizado na parte superior do módulo de criação.
Nota
Os clusters de fluxo de dados levam de 5 a 7 minutos para aquecer.
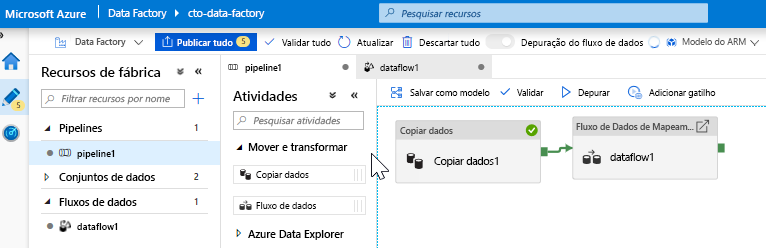
Adicione uma atividade de Fluxo de Dados. No painel Atividades, abra o acordeão Mover e Transformar e arraste a atividade Fluxo de Dados para a tela do pipeline. Na folha que aparece, clique em Criar novo fluxo de dados e selecione Mapeando fluxo de dados e, em seguida, clique em OK. Clique na guia pipeline1 e arraste a caixa verde da sua atividade de Cópia para a Atividade de fluxo de dados para criar uma condição de sucesso. Você verá o seguinte na tela:
Tarefa 2: Adicionando uma fonte de dados
Adicione uma fonte ADLS. Clique duas vezes no objeto Mapping Data Flow na tela. Clique no botão Adicionar fonte na tela Fluxo de dados. Na lista suspensa Conjunto de dados de origem, selecione o conjunto de dados ADLSG2 usado na atividade Copiar
- Se o conjunto de dados estiver apontando para uma pasta com outros arquivos, talvez seja necessário criar outro conjunto de dados ou utilizar parametrização para garantir que apenas o arquivo moviesDB.csv seja lido
- Se você não importou seu esquema em seu ADLS, mas já ingeriu seus dados, vá para a guia 'Esquema' do conjunto de dados e clique em 'Importar esquema' para que seu fluxo de dados conheça a projeção do esquema.
Depois que o cluster de depuração estiver aquecido, verifique se os dados foram carregados corretamente na guia Visualização de dados. Depois de clicar no botão de atualização, o Mapeamento de Fluxo de Dados mostrará um instantâneo da aparência dos dados em cada transformação.
Tarefa 3: Usando a transformação do fluxo de dados de mapeamento
Adicione uma transformação Select para renomear e soltar uma coluna. Na visualização dos dados, você deve ter notado que a coluna "Rotton Tomatoes" está incorreta. Para nomeá-la corretamente e soltar a coluna Classificação não utilizada, você pode adicionar uma transformação Select clicando no ícone + ao lado do nó de origem do ADLS e escolhendo Select em Schema modifier.
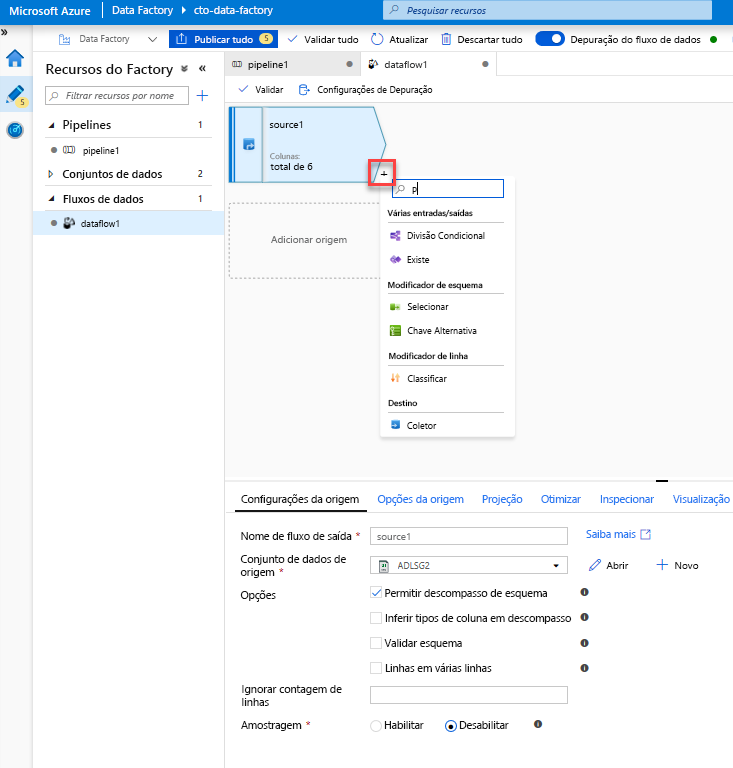
No campo Nome como, altere 'Rotton' para 'Rotten'. Para soltar a coluna Classificação, passe o mouse sobre ela e clique no ícone da reciclagem.
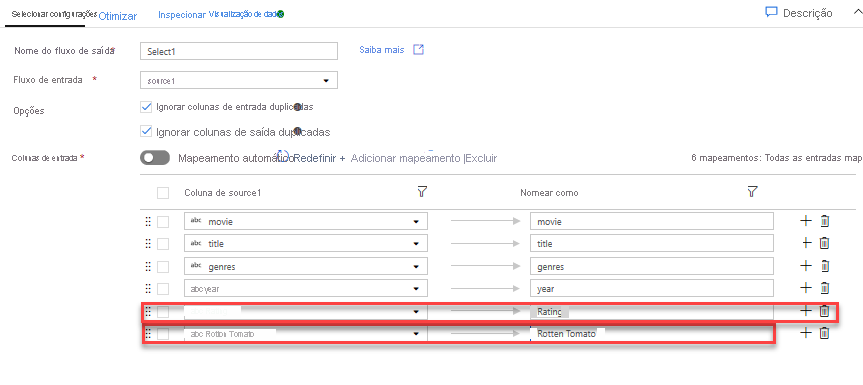
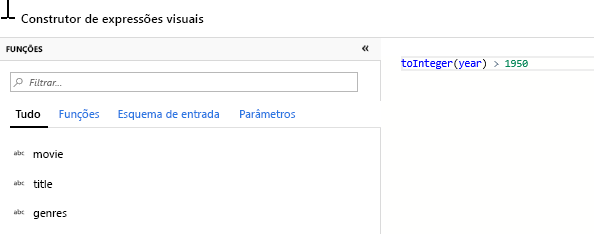
Adicione uma Transformação de Filtro para filtrar anos indesejados. Digamos que você só está interessado em filmes feitos depois de 1951. Você pode adicionar uma transformação Filtro para especificar uma condição de filtro clicando no ícone + ao lado da transformação Selecionar e escolhendo Filtrar em Modificador de linha. Clique na caixa de expressão para abrir o construtor de expressões e insira sua condição de filtro. Usando a sintaxe da linguagem de expressão Mapping Data Flow, toInteger(year) > 1950 converterá o valor do ano da cadeia de caracteres em um inteiro e filtrará linhas se esse valor estiver acima de 1950.
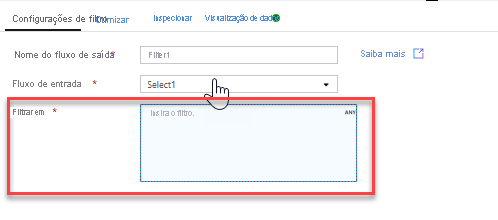
Você pode usar o painel de visualização de dados incorporado do construtor de expressões para verificar se sua condição está funcionando corretamente
Adicione uma Transformação Derive para calcular o gênero principal. Como você deve ter notado, a coluna de gêneros é uma cadeia delimitada por um caractere '|'. Se você se preocupa apenas com o primeiro gênero em cada coluna, você pode derivar uma nova coluna chamada PrimaryGenre por meio da transformação Coluna derivada clicando no ícone + ao lado da transformação Filtro e escolhendo Derivado em Modificador de esquema. Semelhante à transformação do filtro, a coluna derivada usa o construtor de expressões Mapeamento de Fluxo de Dados para especificar os valores da nova coluna.

Neste cenário, você está tentando extrair o primeiro gênero da coluna gêneros, que é formatada como 'genre1|genre2|...|gêneroN'. Use a função locate para obter o primeiro índice baseado em 1 do '|' na cadeia de gêneros. Usando a função iif , se esse índice for maior que 1, o gênero primário pode ser calculado através da função esquerda , que retorna todos os caracteres em uma cadeia de caracteres à esquerda de um índice. Caso contrário, o valor PrimaryGenre é igual ao campo genres. Você pode verificar a saída por meio do painel de visualização de dados do construtor de expressões.
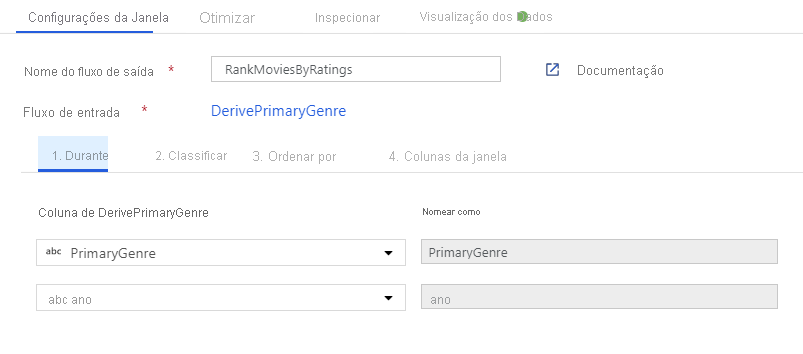
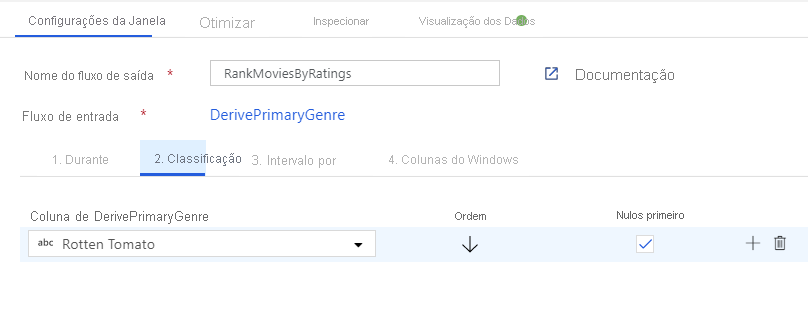
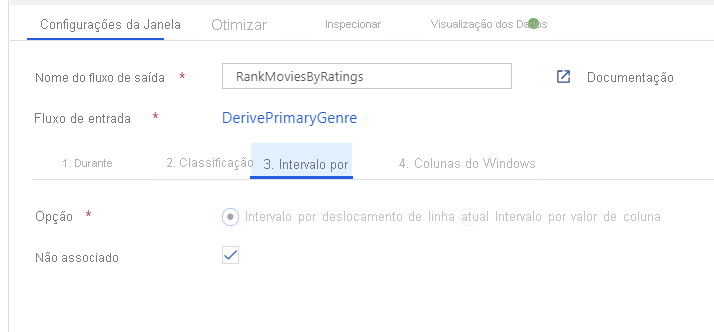
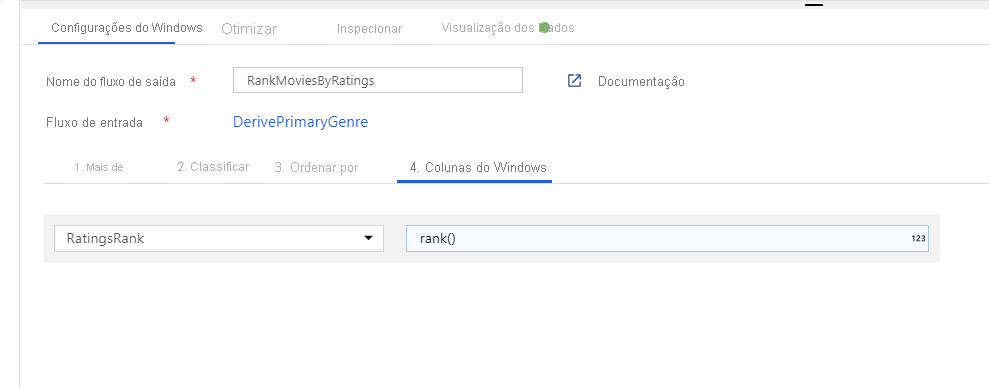
Classifique filmes através de uma Transformação de Janela. Digamos que você está interessado em como um filme se classifica dentro de seu ano para seu gênero específico. Você pode adicionar uma transformação de janela para definir agregações baseadas em janela clicando no ícone + ao lado da transformação de coluna derivada e clicando em Janela em Modificador de esquema. Para fazer isso, especifique o que você está exibindo, o que você está classificando, qual é o intervalo e como calcular suas novas colunas de janela. Neste exemplo, vamos analisar PrimaryGenre e year com um intervalo ilimitado, classificar por Rotten Tomato descendente, e calcular uma nova coluna chamada RatingsRank que é igual à classificação que cada filme tem dentro de seu gênero-ano específico.
Agregar classificações com uma Transformação Agregada. Agora que você reuniu e derivou todos os seus dados necessários, podemos adicionar uma transformação Agregada para calcular métricas com base em um grupo desejado clicando no ícone + ao lado da sua transformação de Janela e clicando em Agregar em Modificador de esquema. Como você fez na transformação da janela, vamos agrupar filmes por PrimaryGenre e ano
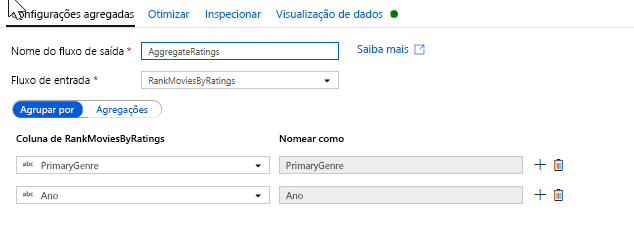
Na guia Agregações, você pode criar agregações calculadas sobre o grupo especificado por colunas. Para cada gênero e ano, vamos obter a classificação média do Rotten Tomatoes, o filme mais bem avaliado e mais baixo (utilizando a função de janela) e o número de filmes que estão em cada grupo. A agregação reduz significativamente o número de linhas em seu fluxo de transformação e apenas propaga o grupo por e agrega colunas especificadas na transformação.
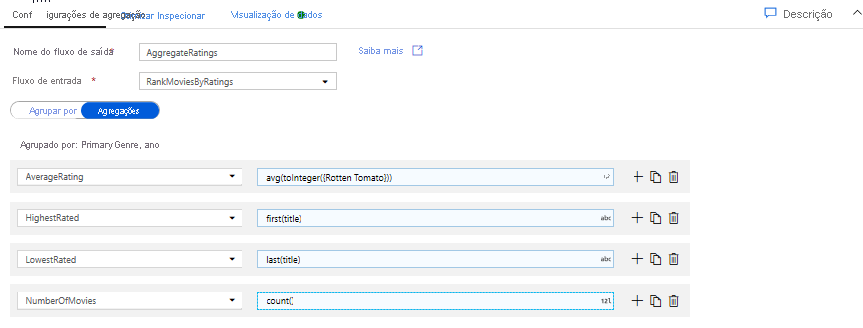
- Para ver como a transformação agregada altera seus dados, use a guia Visualização de dados
Especifique a condição Upsert por meio de uma transformação de linha Alter. Se você estiver gravando em um coletor tabular, poderá especificar políticas de inserção, exclusão, atualização e atualização em linhas usando a transformação Alterar linha clicando no ícone + ao lado da transformação Agregar e clicando em Alterar linha em Modificador de linha. Como você está sempre inserindo e atualizando, você pode especificar que todas as linhas sempre serão atualizadas.

Tarefa 4: Gravando em um coletor de dados
- Escreva em um coletor do Azure Synapse Analytics. Agora que você terminou toda a sua lógica de transformação, você está pronto para escrever em um coletor.
Adicione um coletor clicando no ícone + ao lado da sua transformação Upsert e clicando em Coletor em Destino.
Na guia Coletor, crie um novo conjunto de dados de data warehouse por meio do botão + Novo.
Selecione Azure Synapse Analytics na lista de blocos.
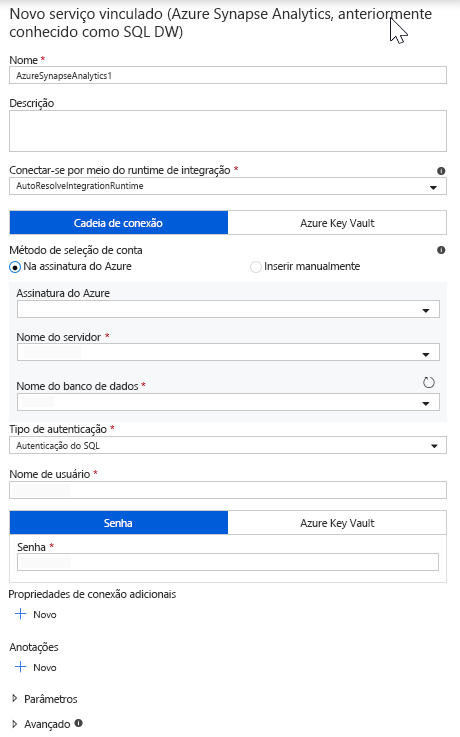
Selecione um novo serviço vinculado e configure sua conexão do Azure Synapse Analytics para se conectar ao banco de dados DWDB. Clique em Criar quando terminar.
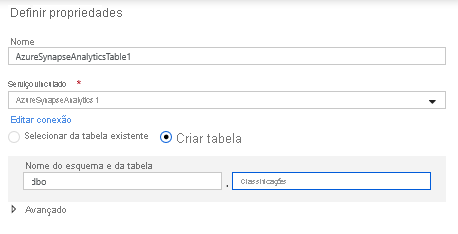
Na configuração do conjunto de dados, selecione Criar nova tabela e insira o esquema de Dbo e o nome da tabela de Classificações. Clique em OK depois de concluído.
Como uma condição de upsert foi especificada, você precisa ir para a guia Configurações e selecionar 'Permitir upsert' com base nas colunas principais PrimaryGenre e year.
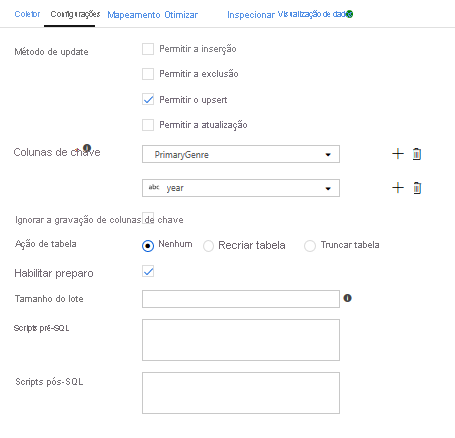
Neste ponto, você terminou de criar seu fluxo de dados de mapeamento de 8 transformações. É hora de executar o pipeline e ver os resultados!

Tarefa 5: Executando o pipeline
Vá para a guia pipeline1 na tela. Como o Azure Synapse Analytics no Fluxo de Dados usa PolyBase, você deve especificar uma pasta de preparo de blob ou ADLS. Na guia Configurações da atividade Executar fluxo de dados, abra o acordeão PolyBase e selecione o serviço vinculado ADLS e especifique um caminho de pasta de preparação.
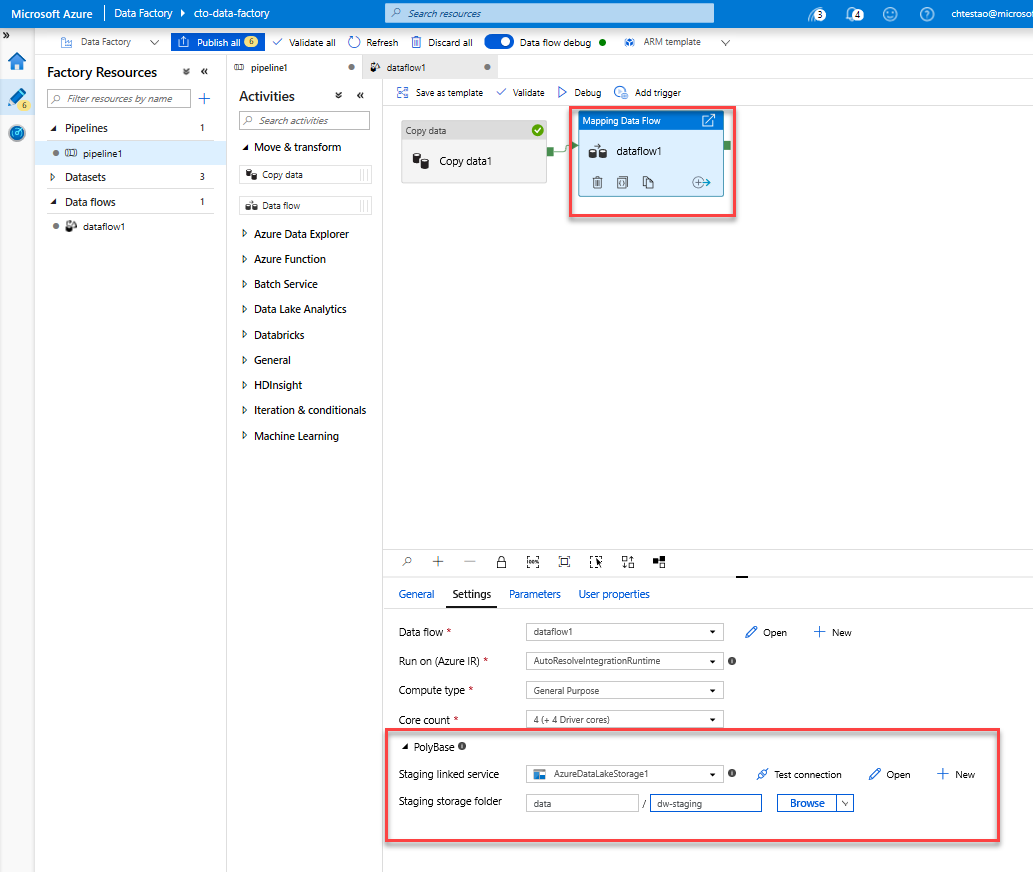
Antes de publicar seu pipeline, execute outra execução de depuração para confirmar que está funcionando conforme o esperado. Olhando para a guia Saída, você pode monitorar o status de ambas as atividades enquanto elas estão sendo executadas.
Quando ambas as atividades forem bem-sucedidas, você poderá clicar no ícone de óculos ao lado da atividade Fluxo de Dados para obter uma visão mais aprofundada da execução do Fluxo de Dados.
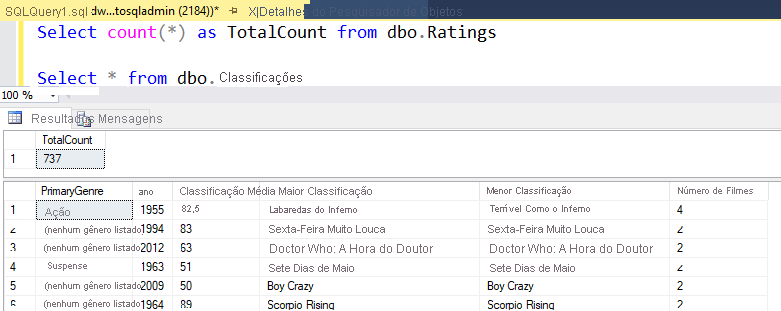
Se você usou a mesma lógica descrita neste laboratório, seu fluxo de dados gravará 737 linhas no DW SQL. Você pode entrar no SQL Server Management Studio para verificar se o pipeline funcionou corretamente e ver o que foi escrito.