Como lidar com a latência do caudal
Já discutimos várias técnicas de otimização utilizadas na cloud para reduzir a latência. Algumas das medidas que estudámos incluem o dimensionamento horizontal ou vertical de recursos e a utilização de um balanceador de carga para encaminhar pedidos para os recursos disponíveis mais próximos. Esta página analisa com maior detalhe por que razão, num grande datacenter ou numa grande aplicação na cloud, é importante minimizar a latência para todos os pedidos e não apenas otimizar para o caso geral. Vamos estudar como até mesmo alguns valores atípicos de alta latência podem prejudicar significativamente o desempenho observado de um grande sistema. Esta página abrange também várias técnicas para criar serviços que fornecem respostas previsíveis de baixa latência, mesmo que os componentes individuais não o garantam. Este é um problema especialmente significativo para aplicações interativas, em que a latência pretendida para uma interação é inferior a 100 ms.
O que é a latência de cauda?
Na sua maioria, as aplicações na cloud são sistemas grandes e distribuídos que muitas vezes dependem da paralelização para reduzir a latência. Uma técnica comum consiste em distribuir um pedido recebido num nó raiz (por exemplo, um servidor Web front-end) para muitos nós de folha (servidores de computação back-end). A melhoria do desempenho é impulsionada pelo paralelismo da computação distribuída e também pelo facto de se evitarem custos extremamente elevados associados à movimentação de dados. Simplesmente movemos a computação para o local onde os dados estão armazenados. É claro que cada nó de folhas opera simultaneamente em centenas ou mesmo milhares de pedidos paralelos.
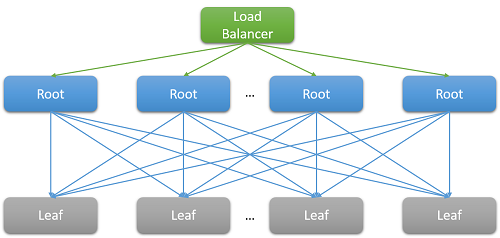
Figura 7: Latência devido à expansão
Considere a pesquisa de um filme na Netflix como exemplo. À medida que um utilizador começa a escrever na caixa de pesquisa, esta ação gerará vários eventos paralelos a partir do servidor Web raiz. No mínimo, estes eventos incluem os seguintes pedidos:
- Ao motor de preenchimento automático, para prever efetivamente a pesquisa que está a ser feita com base em tendências anteriores e no perfil do utilizador.
- Ao motor de correção, que encontra erros na consulta escrita com base num modelo de linguagem constantemente em adaptação.
- Resultados da pesquisa individuais para cada uma das palavras que compõem uma consulta com várias palavras, que têm de ser combinadas com base na classificação e relevância dos filmes.
- Pós-processamento e filtragem adicionais de resultados para ir ao encontro das preferências de "pesquisa segura" do utilizador.
Estes exemplos são extremamente comuns. Sabe-se que um único pedido do Facebook contacta milhares de servidores na cache da memória, enquanto uma única pesquisa no Bing contacta muitas vezes mais de dez mil servidores de índice.
É evidente que a necessidade de dimensionamento levou a uma grande distribuição ramificada no back-end para cada pedido individual entregue pelo front-end. Para serviços que se espera que sejam "reativos" para manter a sua base de utilizadores, a heurística mostra que se esperam respostas em 100 ms. À medida que o número de servidores necessários para resolver uma consulta aumenta, o tempo geral depende frequentemente da resposta com pior desempenho de um nó de folha para um nó raiz. Pressupondo que todos os nós de folha têm de terminar a execução antes de um resultado poder ser devolvido, a latência geral tem de ser sempre maior do que a latência do componente individual mais lento.
Como a maioria dos processos estocásticos, o tempo de resposta de um único nó de folha pode ser expresso como uma distribuição. Décadas de experiência mostraram que, no caso geral, a maioria (>99%) das solicitações de um sistema de nuvem bem configurado será executada extremamente rapidamente. No entanto, muitas vezes, há muito poucos valores atípicos num sistema que são executados com extrema lentidão.
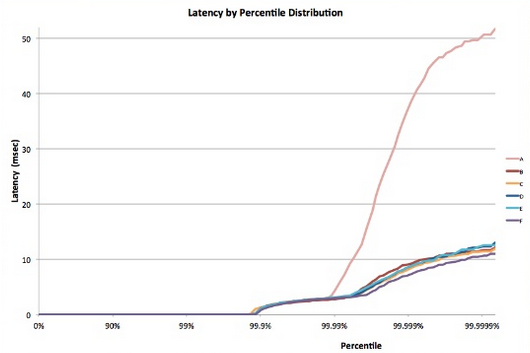
Figura 8: Exemplode latência de cauda 5
Considere um sistema em que todos os nós de folha têm um tempo de resposta médio de 1 ms, mas há uma probabilidade de 1% de o tempo de resposta ser superior a 1000 ms (um segundo). Se cada consulta for tratada por apenas um nó de folha, a probabilidade de a consulta demorar mais do que um segundo é também de 1%. No entanto, à medida que aumentamos o número de nós para 100, a probabilidade de a consulta terminar dentro de um segundo cai para 36,6%, o que significa que há 63,4% de probabilidade de a duração da consulta ser determinada pela cauda (1% mais baixo) da distribuição da latência.
$(.99^{100})$
Se simularmos isto para uma variedade de casos, vemos que à medida que o número de servidores aumenta, o impacto de uma única consulta lenta é mais pronunciado (note que o grafo abaixo está a aumentar monotonicamente). Além disso, como a probabilidade destes valores atípicos diminui de 1% para 0,01%, o sistema é substancialmente inferior.
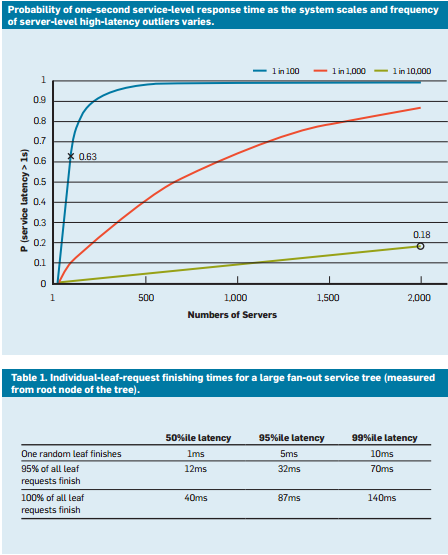
Figura 9: Estudo recente de probabilidade de tempo de resposta que mostra os percentis 50, 95 e 99 para latência de solicitações4
Assim como projetamos nossos aplicativos para serem tolerantes a falhas para lidar com problemas de confiabilidade de recursos, deve ficar claro agora por que é importante que os aplicativos sejam "tolerantes à cauda". Para sermos capazes de fazer isso, devemos entender as fontes dessas longas variabilidades de desempenho e identificar mitigações sempre que possível e soluções alternativas onde não.
Variabilidade na nuvem: fontes e mitigações
Para resolver a variabilidade do tempo de resposta que conduz a este problema de latência de cauda, temos de conhecer as origens da variabilidade do desempenho.1
- Uso de recursos compartilhados: muitas VMs diferentes (e aplicativos dentro dessas VMs) disputam um pool compartilhado de recursos de computação. Em casos raros, é possível que esta disputa conduza a uma baixa latência para alguns pedidos. No caso de tarefas críticas, pode fazer sentido utilizar instâncias dedicadas e executar periodicamente testes de referência durante a inatividade para garantir que um comportamento correto.
- Daemons em segundo plano e manutenção: Já falamos sobre a necessidade de processos em segundo plano para criar pontos de verificação, criar backups, atualizar logs, coletar lixo e lidar com a limpeza de recursos. No entanto, estes podem prejudicar o desempenho do sistema durante a execução. Para mitigar isto, é importante sincronizar perturbações derivadas dos threads de manutenção para minimizar o impacto no fluxo do tráfego. Isto fará com que toda a variação ocorra num período curto e bem conhecido e não aleatoriamente ao longo da vida útil da aplicação.
- Enfileiramento: Outra fonte comum de variabilidade é a explosão dos padrões de chegada do tráfego. 1 Esta variabilidade é exacerbada se o SO utilizar um algoritmo de agendamento diferente do FIFO. Os sistemas Linux, muitas vezes, agendam threads fora da ordem para otimizar o débito geral e maximizar a utilização do servidor. Estudos demonstram que a utilização do agendamento FIFO no SO reduz a latência de cauda à custa da redução do débito geral do sistema.
- Incast tudo-para-todos: O padrão mostrado na Figura 8 acima é conhecido como comunicação tudo-para-todos. Como a maioria das comunicações de rede é feita através de TCP, isto resulta em milhares de pedidos e respostas simultâneos entre o servidor Web front-end e todos os nós de processamento back-end. Este é um padrão de comunicação extremamente rápido que, muitas vezes, resulta num tipo especial de falha de congestionamento conhecido como colapso incast de TCP.1, 2 A súbita resposta intensa de milhares de servidores resulta em muitos pacotes ignorados e retransmitidos, acabando por causar uma avalanche de rede de tráfego para pacotes de dados muito pequenos. Os grandes datacenters e aplicações na cloud precisam, muitas vezes, de utilizar controladores de rede personalizados para ajustar dinamicamente o período de receção de TCP e o temporizador de retransmissão. Os routers também podem ser configurados para ignorar o tráfego que excede uma velocidade específica e reduzir o tamanho do envio.
- Gerenciamento de energia e temperatura: Finalmente, a variabilidade é um subproduto de outras técnicas de redução de custos, como o uso de estados ociosos ou redução de frequência da CPU. Um processador pode, muitas vezes, passar uma quantidade de tempo não trivial a aumentar verticalmente a partir de um estado de inatividade. A desativação destas otimizações de custos resulta na uma maior utilização da energia e dos custos, mas a uma menor variabilidade. Isto não é um problema tão grande na cloud pública porque os modelos de preços raramente têm em consideração as métricas de utilização internas dos recursos do cliente.
Algumas experiências permitiram concluir que a variabilidade destes sistemas é muito pior na cloud pública3, normalmente devido ao isolamento de desempenho imperfeito dos recursos virtuais e do processador partilhado. Isto é exacerbado se muitas tarefas sensíveis à latência forem executadas no mesmo nó físico das tarefas associadas à utilização intensiva da CPU.
Viver com variabilidade: Soluções de engenharia
Muitas das origens de variabilidade acima mencionadas não têm nenhuma solução à prova de falhas. Como tal, em vez de tentar acabar com todas as origens que aumentam a cauda da latência, as aplicações na cloud têm de ser concebidas para serem tolerantes à cauda. Isto é obviamente semelhante à forma como concebemos aplicações para que estas sejam tolerantes a falhas, uma vez que não podemos esperar corrigir todas as possíveis falhas. Seguem-se algumas das técnicas habitualmente utilizadas para lidar com esta variabilidade.
- Resultados "bons o suficiente": Muitas vezes, quando o sistema está esperando para receber resultados de milhares de nós, a importância de qualquer resultado individual pode ser considerada bastante baixa. Como tal, muitas aplicações podem optar simplesmente por responder aos utilizadores com resultados que chegam num período de latência curto e particular e descartar o resto.
- Canárias: Outra alternativa que é frequentemente usada para caminhos de código raros é testar uma solicitação em um pequeno subconjunto de nós folha para testar se ela causa uma falha ou falha que pode afetar todo o sistema. A consulta de distribuição ramificada apenas é gerada na íntegra se a proteção não causar uma falha. Isto é semelhante ao que acontece quando se liberta um canário numa mina de carvão para testar se esta é segura para as pessoas.
- Liberdade condicional induzida por latência e verificações de saúde: É claro que uma grande parte das solicitações para um sistema são muito comuns para testar usando um canário. Estes pedidos são mais propensos a ter uma cauda longa se um dos nós de folha estiver a ter um mau desempenho. Para contrariar esta situação, o sistema tem de monitorizar periodicamente o estado de funcionamento e a latência de cada nó de folha e não encaminhar pedidos para nós que demonstrem ter um baixo desempenho (devido a manutenção ou falhas).
- QoS diferencial: Classes de serviço separadas podem ser criadas para solicitações interativas, permitindo que elas tenham prioridade em qualquer fila. As aplicações insensíveis à latência conseguem tolerar tempos de espera mais longos para as suas operações.
- Cobertura de solicitação: esta é uma solução simples para reduzir o impacto da variabilidade, encaminhando a mesma solicitação para várias réplicas e usando a resposta que chega primeiro. Claro que isto pode duplicar ou triplicar a quantidade de recursos necessários. Para reduzir o número de pedidos limitados, o segundo pedido só pode ser enviado se a primeira resposta estiver pendente durante um período superior ao percentil 95 da latência esperada para esse pedido. Isto faz com que a carga extra seja apenas cerca de 5%, mas reduz significativamente a cauda da latência (no caso típico mostrado na Figura 9, em que a latência do percentil 95 é muito inferior à latência do percentil 99).
- Execução especulativa e replicação seletiva: Tarefas em nós que estão particularmente ocupados podem ser lançadas especulativamente em outros nós folha subutilizados. Isto é especialmente eficaz se uma falha num determinado nó fizer com que este fique sobrecarregado.
- Soluções baseadas em UX: Finalmente, o atraso pode ser inteligentemente escondido do usuário através de uma interface de usuário bem projetada que reduz a sensação de atraso experimentada por um usuário humano. As técnicas para o fazer podem incluir a utilização de animações, a apresentação de resultados precoces ou o envolvimento do utilizador através do envio de mensagens relevantes.
A utilização destas técnicas permite melhorar significativamente a experiência dos utilizadores finais de uma aplicação na cloud para resolver o problema peculiar de uma cauda longa.
Referências
- Li, J., Sharma, N. K., Portos, D. R., & Gribble, S. D. (2014). Tales of the Tail: Hardware, SO e Application-Level Sources of Tail Latency from the Proceedings of the ACM Symposium on Cloud Computing, ACM
- Wu, Haitao e Feng, Zhenqian e Guo, Chuanxiong e Zhang, Yongguang (2013). ICTCP: Incast Congestion Control for TCP in Data-Center Networks, IEEE/ACM Transactions on Networking (TON), IEEE Press
- Xu, Yunjing e Musgrave, Zachary e Noble, Brian e Bailey, Michael (2013). Bobtail: Evitando Caudas Longas na Nuvem, 10th USENIX Conference on Networked Systems Design and Implementation, USENIX Association
- Dean, Jeffrey e Barroso, Luiz André (2013). A cauda em escala, Comunicações do ACM, ACM
- Tene, Gil (2014). [Entendendo a latência - algumas lições e ferramentas importantes] (https://www.infoq.com/presentations/latency-lessons-tools/, QCon Londres