Criar serviços cloud tolerantes a falhas
Uma grande parte do datacenter e da gestão do serviço cloud envolve a conceção e manutenção de um serviço fiável baseado em partes pouco fiáveis. A figura seguinte mostra parte de uma preparação para novas contratações e deve fornecer uma ideia do grande número (e tipos) de falhas que são detetadas regularmente num grande datacenter.

Figura 2: Problemas de confiabilidade mostrados em uma apresentação de treinamento
Uma falha num sistema ocorre em resultado de um estado inválido introduzido no sistema devido a uma falha. Os sistemas normalmente desenvolvem falhas de um dos seguintes tipos:
- Falhas transitórias: Falhas temporárias no sistema que se corrigem com o tempo.
- Falhas permanentes: Falhas que não podem ser recuperadas e geralmente exigem substituição de recursos.
- Falhas intermitentes: Falhas que ocorrem periodicamente em um sistema.
As falhas podem afetar a disponibilidade do sistema, ao diminuírem os serviços ou o desempenho das funcionalidades do sistema. Um sistema tolerante a falhas tem a capacidade de desempenhar a sua função mesmo na presença de falhas no sistema. Na cloud, um sistema tolerante a falhas é muitas vezes considerado o sistema que fornece serviços de forma consistente com tempo de inatividade mais baixo do que os contratos de nível de serviço (SLA) permitem.
Por que motivo é a tolerância a falhas importante?
As falhas em grandes sistemas fundamentais podem resultar em perdas monetárias significativas para todas as partes envolvidas. A própria natureza dos sistemas de computação na cloud é o facto de terem uma arquitetura em camadas. Assim, uma falha numa camada dos recursos da cloud pode desencadear uma falha noutras camadas acima ou ocultar o acesso às camadas abaixo.
Por exemplo, uma falha em qualquer componente de hardware do sistema pode afetar a execução normal de uma aplicação SaaS (software como serviço) que está a ser executada numa máquina virtual que utiliza os recursos com falhas. As falhas num sistema em qualquer camada têm uma relação direta com os SLAs entre os fornecedores em cada nível.
Medidas proativas
Os fornecedores de serviços tomam várias medidas para conceber o sistema de forma específica para evitar problemas conhecidos ou falhas previsíveis.
Perfis e testes
Os testes de carga e esforço aos recursos na cloud de modo a entender possíveis causas de falha são essenciais para garantir a disponibilidade dos serviços. O perfil destas métricas ajuda a conceber um sistema que possa suportar com êxito a carga esperada sem qualquer comportamento imprevisível.
Excesso de aprovisionamento
O excesso de aprovisionamento é a prática de implementação de recursos em volumes maiores do que a utilização planeada geral dos recursos num determinado momento. Em situações em que as necessidades exatas do sistema não podem ser necessariamente previstas, os recursos com excesso de aprovisionamento podem ser uma estratégia aceitável para lidar com picos de cargas inesperados.
Por exemplo, considere uma plataforma de comércio eletrónico que tem uma carga média consistente nos seus servidores durante todo o ano, mas durante a época de férias a expetativa é que o padrão de carga aumente rapidamente. Nestes momentos de pico, é aconselhável fornecer recursos extra com base nos dados históricos para a utilização máxima. Um rápido aumento do tráfego é normalmente difícil de acomodar num curto espaço de tempo. Como abordado em secções posteriores, existe um custo de tempo associado ao dimensionamento dinâmico, que envolve os passos demorados de detetar uma mudança no padrão de carga e fornecer recursos adicionais para acomodar a nova carga. Ambos os passos vão precisar de tempo. Este atraso de tempo no ajuste pode ser suficiente para sobrecarregar e, na pior das hipóteses, o sistema falha ou, na melhor das hipóteses, a qualidade do serviço degrada-se.
O excesso de aprovisionamento é também uma tática utilizada para se defender contra ataques DoS (denial of service) ou DDoS (DoS distribuído), que ocorre quando os atacantes geram pedidos concebidos para sobrecarregar um sistema, ao enviar-lhe grandes volumes de tráfego como uma tentativa de fazer o sistema falhar. Em qualquer ataque, leva sempre algum tempo para que o sistema detete e tome medidas corretivas. Embora esta análise dos padrões de pedido esteja a ser feita, o sistema já está sob ataque e precisa de ser capaz de acomodar o tráfego acrescido até que uma estratégia de mitigação possa ser implementada.
Replicação
Os componentes críticos do sistema podem ser duplicados através de componentes adicionais de hardware e software para lidar silenciosamente com falhas em partes do sistema sem que todo o sistema falhe. A replicação tem duas estratégias básicas:
- Replicação ativa, onde todos os recursos replicados estão ativos simultaneamente e respondem e processam todos os pedidos. Isto significa que, para qualquer pedido do cliente, todos os recursos recebem o mesmo pedido, todos os recursos respondem ao mesmo pedido e a ordem dos pedidos mantém o estado em todos os recursos.
- A replicação passiva, onde apenas a unidade principal processa os pedidos e as unidades secundárias apenas mantêm o estado e assumem a tarefa assim que a unidade principal falha. O cliente só está em contacto com o recurso principal, que transmite a mudança do estado a todos os recursos secundários. A desvantagem da replicação passiva é que pode haver pedidos abandonados ou QoS degradada na mudança da instância principal para a instância secundária.
Há também uma estratégia híbrida, denominada semi-ativa, que é muito semelhante à estratégia ativa. A diferença é que apenas o resultado do recurso principal é exposto ao cliente. Os resultados dos recursos secundários são suprimidos e registados, e estão prontos para serem mudados assim que ocorrer uma falha do recurso principal. A figura seguinte mostra as diferenças entre as estratégias de replicação.
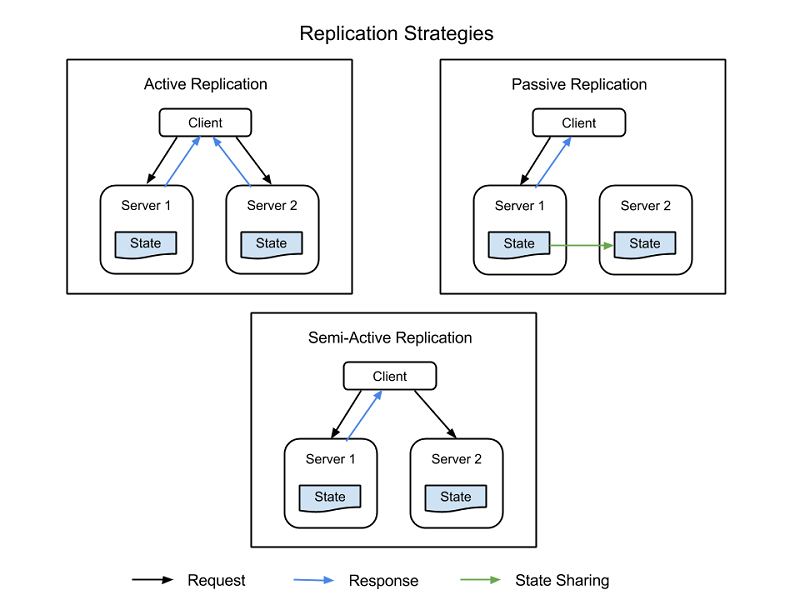
Figura 3: Estratégias de replicação
Um fator importante a ter em conta na replicação é o número de recursos secundários a utilizar. Embora isto varie de aplicação para aplicação com base na importância do sistema, existem 3 níveis formais de replicação:
- N+1: Isso basicamente significa que, para um aplicativo que precisa de nós N para funcionar corretamente, um recurso extra é provisionado como à prova de falhas.
- 2N: Neste nível, um nó extra para cada nó necessário para a função normal é provisionado como um fail-safe.
- 2N+1: Neste nível, um nó extra para cada nó necessário para a função normal, e um nó adicional em geral, é provisionado como um fail-safe.
Medidas reativas
Além de medidas preditivas, os sistemas podem tomar medidas reativas e lidar com falhas conforme e quando acontecem:
Verificações e monitorização
Todos os recursos são constantemente monitorizados de forma a verificar se há comportamentos imprevisíveis ou perda de recursos. Com base nas informações de monitorização, as estratégias de recuperação ou reconfiguração são concebidas de forma a reiniciar recursos ou trazer novos recursos. A monitorização pode ajudar na identificação de falhas nos sistemas. As falhas que fazem com que um serviço esteja indisponível são chamadas falhas de sistema e as que induzem um comportamento irregular/incorreto no sistema são chamadas falhas bizantinas.
Existem várias táticas de monitorização que são utilizadas para verificar falhas dentro de um sistema. Duas destas táticas são:
- Ping-echo: O serviço de monitoramento solicita a cada recurso seu estado e recebe uma janela de tempo para responder.
- Heartbeat: Cada instância envia o status para o serviço de monitoramento em intervalos regulares, sem qualquer gatilho.
A monitorização das falhas bizantinas depende geralmente das propriedades do serviço fornecido. Os sistemas de monitorização podem verificar métricas básicas como latência, utilização de CPU e utilização da memória, e verificar os valores esperados para ver se a qualidade do serviço está a degradar. Além disso, os registos de supervisão específicos da aplicação são geralmente mantidos em cada ponto importante de execução do serviço e analisados periodicamente para ver se o serviço está a funcionar corretamente em todos os momentos (ou se há falhas injetadas no sistema).
Ponto de verificação e reinício
Vários modelos de programação na cloud implementam estratégias de ponto de verificação, através das quais o estado é guardado em várias fases de execução de forma a permitir a recuperação para o último ponto de verificação guardado. Nas aplicações de análise de dados, existem muitas vezes tarefas distribuídas paralelas de longa duração que são executadas em terabytes de conjuntos de dados para extrair informações. Uma vez que estas tarefas são executadas em vários pequenos segmentos de execução, cada passo na execução do programa pode guardar o estado geral de execução como um ponto de verificação. Em pontos de falha, nos quais os nós individuais não conseguem completar o seu trabalho, a execução pode ser reiniciada a partir de um ponto de verificação anterior. O maior desafio na identificação de pontos de verificação válidos que permitam a reversão é quando os processos paralelos estão a partilhar informações. Uma falha num dos processos pode provocar uma reversão em cascata noutro processo, uma vez que os pontos de verificação efetuados nesse processo podem resultar de uma falha nos dados partilhados pelo processo de falha. Aprenderá mais sobre tolerância a falhas para modelos de programação em módulos posteriores.
Casos práticos em testes de resiliência
Os serviços cloud precisam de ser criados tendo em consideração a redundância e a tolerância a falhas, uma vez que nenhum componente individual de um grande sistema distribuído pode garantir 100% de disponibilidade ou tempo de atividade.
Todas as falhas (incluindo falhas de dependências no mesmo nó, rack, datacenter ou implementações redundantes regionais) devem ser tratadas normalmente sem afetar a integridade do sistema. Testar a capacidade do sistema para lidar com falhas catastróficas é importante, uma vez que, por vezes, mesmo alguns segundos de tempo de inatividade ou degradação do serviço podem causar centenas de milhares, se não milhões, de dólares em perdas de receitas.
Os testes para falhas com tráfego real têm de ser feitos regularmente para que o sistema seja fortalecido e possa lidar com a situação quando ocorre uma indisponibilidade não planeada. Existem vários sistemas construídos para testar a resiliência. Um desses conjuntos de testes é o Simian Army (Exército Símio) criado pela Netflix.
O Simian Army é composto por serviços (referidos como macacos) na cloud para gerar vários tipos de falhas, detetar condições anormais e testar a capacidade do sistema de sobreviver a essas falhas. O objetivo é manter a cloud segura, protegida e altamente disponível. Alguns dos "macacos" encontrados no Simian Army são:
- Macaco do caos: uma ferramenta que escolhe aleatoriamente uma instância de produção e a desabilita para garantir que a nuvem sobreviva a tipos comuns de falha sem qualquer impacto no cliente. A Netflix descreve Chaos Monkey como "A ideia de libertar um macaco selvagem com uma arma no seu datacenter (ou região da nuvem) para abater instâncias aleatoriamente e mastigar cabos - enquanto continuamos a servir os nossos clientes sem interrupção." Esse tipo de teste com monitoramento detalhado pode expor várias formas de fraquezas no sistema, e estratégias de recuperação automáticas podem ser construídas com base nos resultados.
- Macaco de latência: um serviço que induz atrasos entre a comunicação RESTful de diferentes clientes e servidores, simulando degradação do serviço e tempo de inatividade.
- Macaco médico: um serviço que localiza instâncias que apresentam comportamentos não íntegros (por exemplo, carga de CPU) e as remove do serviço. Permite aos proprietários de serviço algum tempo para descobrirem a razão do problema e, eventualmente, termina a ocorrência.
- Gorila do caos: um serviço que pode simular a perda de toda uma zona de disponibilidade da AWS. Este é utilizado para testar se os serviços reequilibram automaticamente a funcionalidade entre as restantes zonas sem impacto ou intervenção manual visível pelo utilizador.