Classificar os dados
Uma loja de retalho online pode ter diferentes tipos de dados. Cada tipo de dados pode se beneficiar de uma solução de armazenamento diferente.
Os dados da aplicação podem ser classificados de uma de três formas: estruturados, semiestruturados e não estruturados. Aqui, você aprenderá como classificar seus dados para poder escolher a solução de armazenamento apropriada para o tipo de dados.
Abordagens para armazenar dados na cloud
O vídeo a seguir apresenta suas opções para armazenar dados na nuvem:
Dados estruturados
Em dados estruturados, às vezes chamados de dados relacionais, todos os dados têm os mesmos campos ou propriedades. Todos os dados têm a mesma organização e forma, ou esquema. O esquema compartilhado permite que esse tipo de dados seja facilmente pesquisado usando linguagens de consulta como SQL (Structured Query Language). Esse recurso torna esse estilo de dados perfeito para aplicativos como sistemas de CRM, reservas e gerenciamento de estoque.
Os dados estruturados geralmente são armazenados em tabelas de banco de dados com linhas e colunas. Na tabela, uma coluna de chave indica como uma linha de uma tabela se relaciona com os dados em outra linha de outra tabela. Na imagem a seguir, uma tabela com dados sobre notas obtém dados de uma tabela de nomes de alunos e uma tabela de dados de classe usando colunas de chave.
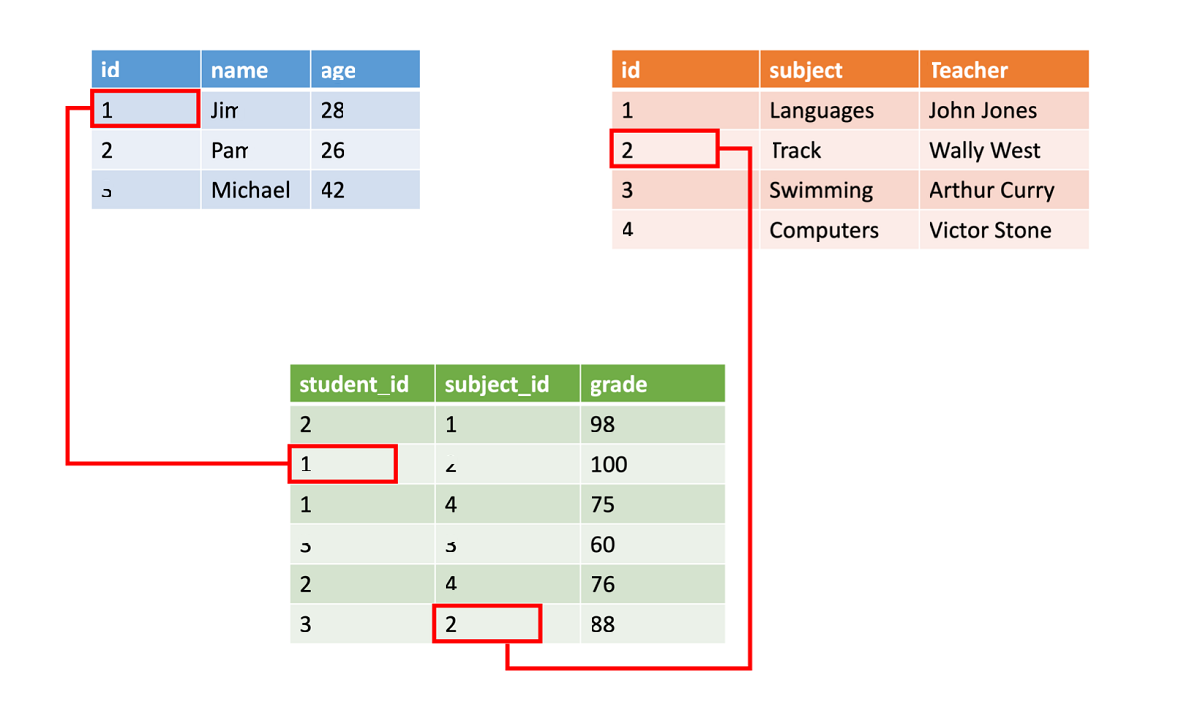
Os dados estruturados são simples na medida em que são fáceis de introduzir, consultar e analisar. Todos os dados estão no mesmo formato. No entanto, forçar uma estrutura consistente também significa que a evolução dos dados é mais difícil. Se você adicionar ou remover campos de dados, deverá atualizar cada registro para estar em conformidade com a nova estrutura.
Dados semiestruturados
Os dados semiestruturados são menos organizados do que os dados estruturados. Os dados semiestruturados não são armazenados em um formato relacional porque os campos não se encaixam perfeitamente em tabelas, linhas e colunas. Os dados semiestruturados contêm etiquetas que tornam a organização e hierarquia dos dados mais evidentes. Um exemplo são os pares chave/valor. Os dados semiestruturados também são chamados de dados não relacionais ou não apenas SQL (NoSQL).
Uma linguagem de serialização de dados define dados semiestruturados. Na classificação de dados, a serialização é o processo de conversão de dados em um formato que pode ser transmitido ou armazenado.
Os desenvolvedores de software usam linguagens de serialização de dados para gravar dados armazenados na memória em um arquivo, que pode ser enviado para outro sistema, analisado e lido. O emissor e o recetor não precisam saber detalhes sobre o outro sistema. Ambos os sistemas podem entender os dados se usarem a mesma linguagem de serialização.
Linguagens de serialização comuns
Três linguagens de serialização comuns são XML, JSON e YAML.
XML
Extensible Markup Language (XML) foi uma das primeiras linguagens de dados a ser amplamente utilizada. O XML é baseado em texto, o que o torna facilmente legível por humanos e por máquina. Os analisadores XML estão disponíveis para quase todas as plataformas de desenvolvimento populares.
Você pode usar XML para expressar relações. XML tem padrões para esquema, transformação e até mesmo exibição na Web.
Aqui está um exemplo do nome, idade e hobbies de uma pessoa expressos em XML:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML expressa a forma dos dados usando tags que são definidas dentro de chaves angulares. As tags vêm em duas formas: elementos como <FirstName> e atributos que podem ser expressos em texto como Age="23". Os elementos podem ter elementos filhos para expressar relações. Por exemplo, a <Hobbies> tag expressa uma coleção de Hobby elementos.
A linguagem XML é flexível e pode expressar dados complexos facilmente. No entanto, tende a ser mais detalhado, o que o torna maior para armazenar, processar e passar por uma rede. Como resultado, existem outros formatos que se tornaram mais populares.
JSON
JavaScript Object Notation (JSON) tem uma especificação leve e usa chaves para indicar a estrutura de dados. Em comparação com o XML, o JSON é menos detalhado e é mais fácil para os seres humanos lerem. JSON freqüentemente é usado por serviços Web para retornar dados.
Aqui está o nome, idade e hobbies da mesma pessoa expressos em JSON:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
O formato JSON não é tão formal quanto XML. Está mais próximo de um modelo de par chave/valor do que de uma expressão de dados formal. Como você pode adivinhar pelo nome, a linguagem de programação JavaScript tem suporte interno para este formato, por isso é popular para desenvolvimento web. Tal como a linguagem XML, outras linguagens têm analisadores que pode utilizar para trabalhar com este formato de dados. A desvantagem do JSON é que ele tende a ser mais orientado para o programador, então é mais difícil para pessoas não técnicas lerem e modificarem.
YAML
YAML Ain't Markup Language (YAML) é uma linguagem de serialização de dados desenvolvida mais recentemente. Um dos benefícios de usar YAML é que é mais fácil para os seres humanos lerem do que algumas outras línguas. A separação de linhas e o recuo definem a estrutura de dados. O formato YAML reduz a dependência de caracteres estruturais como parênteses, vírgulas e colchetes.
Aqui estão os mesmos dados expressos no YAML:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Este formato é mais legível do que o JSON. Arquivos de configuração que as pessoas escrevem, mas programas analisam é um uso comum para ele. YAML é o mais novo desses formatos de dados.
É frequentemente usado para arquivos de configuração escritos por pessoas, mas analisados por programas.
O que são dados semiestruturados ou NoSQL?
O vídeo a seguir descreve dados semiestruturados e opções de armazenamento de dados NoSQL:
Dados não estruturados
A organização dos dados não estruturados é indefinida. Os dados não estruturados geralmente são entregues em formato de arquivo, como em arquivos de foto ou vídeo. O arquivo de vídeo em si pode ter uma estrutura geral e vir com metadados semiestruturados, mas os dados que formam o vídeo em si não são estruturados. Por conseguinte, fotografias, vídeos e outros ficheiros semelhantes são classificados como dados não estruturados.
Alguns exemplos de dados não estruturados:
- Arquivos de mídia, como fotos, vídeos e arquivos de áudio.
- Arquivos do Microsoft 365, como documentos do Word.
- Arquivos de texto.
- Ficheiros de registo.
Classificação de dados: avalie seus tipos de dados
Você pode classificar os dados de três maneiras: estruturados, semiestruturados e não estruturados. Compreender as diferenças para que você possa classificar seus dados ajuda a escolher a solução de armazenamento correta.
Dados estruturados são dados organizados que se encaixam perfeitamente em tabelas ou colunas de dados. Os dados semiestruturados ainda são organizados e têm propriedades e valores claros, mas são dados com variedade. Os dados não estruturados não se encaixam perfeitamente em tabelas ou colunas e não têm um esquema uniforme.
Vamos olhar para os conjuntos de dados usados em um negócio de varejo on-line e classificá-los.
Dados de catálogo de produtos
Os dados do catálogo de produtos de um negócio de varejo on-line são semiestruturados por natureza. Cada produto tem um SKU de produto, uma descrição, uma quantidade, um preço, opções de tamanho, opções de cor, uma foto e, possivelmente, um vídeo. Esses dados parecem relacionais para começar, porque todos têm a mesma estrutura. No entanto, à medida que introduz novos produtos ou diferentes tipos de produtos, convém adicionar campos de dados. Por exemplo, os novos tênis que você carrega são habilitados para Bluetooth para transmitir dados do sensor do tênis para um aplicativo de fitness no telefone do usuário. Este recurso parece ser uma tendência crescente, e você quer dar aos clientes a opção de filtrar sapatos "habilitados para Bluetooth". Você não quer atualizar todos os seus dados de calçado existentes com uma propriedade habilitada para Bluetooth. Você deseja adicionar esta nova propriedade apenas a sapatos novos.
Com a adição da propriedade habilitada para Bluetooth, os dados do seu sapato não são mais homogêneos. Você introduziu diferenças no esquema. Se essa alteração for a única exceção que você espera encontrar, você pode normalizar os dados existentes para que todos os produtos incluam um campo "habilitado para Bluetooth" para manter uma organização estruturada e relacional. No entanto, se for apenas um dos muitos campos de especialidade que você prevê oferecer suporte no futuro, a classificação dos dados será semiestruturada. As tags organizam os dados, mas cada produto no catálogo pode conter campos exclusivos.
A classificação dos dados do catálogo de produtos é semiestruturada.
Fotografias e vídeos
As fotografias e os vídeos apresentados nas páginas de produtos são dados não estruturados. Embora o arquivo de mídia possa conter metadados, o corpo do arquivo de mídia não está estruturado.
A classificação de dados para fotos e vídeos não é estruturada.
Dados comerciais
Os analistas comerciais querem implementar business intelligence para efetuar avaliações de pipeline do inventário e análises de dados de vendas. Para executar essas operações, os dados de vários meses precisam ser agregados e, em seguida, consultados. Devido à necessidade de agregar dados semelhantes, estes dados devem ser estruturados, de modo a que um mês possa ser comparado com o seguinte.
A classificação para dados corporativos é estruturada.