Exercício – Criar e Preparar uma Rede Neural
Nesta unidade, irá utilizar o Keras para criar e preparar uma rede neural que analisa o texto em termos de sentimento. Para preparar uma rede neural, precisará de dados. Em vez de transferir um conjunto de dados externo, irá utilizar o conjunto de dados Classificação de sentimento de críticas de filmes do IMDB que é incluído no Keras. O conjunto de dados IMDB contém 50 000 críticas de filmes que foram classificadas individualmente como positivas (1) ou negativas (0). O conjunto de dados está dividido em 25 000 críticas para preparação e 25 000 críticas para testes. O sentimento expresso nessas críticas é a base para a qual a rede neural irá analisar o texto apresentado e pontuá-lo em termos de sentimento.
O conjunto de dados do IMDB é um dos vários conjuntos de dados úteis e incluídos no Keras. Para ver uma lista completa dos conjuntos de dados incorporados, veja https://keras.io/datasets/.
Escreva ou cole o seguinte código na primeira célula do bloco de notas e clique no botão Executar (ou prima Shift+Enter) para o executar e adicionar uma nova célula abaixo do mesmo:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Este código carrega o conjunto de dados do IMDB incluído no Keras e cria um dicionário que mapeia as palavras das 50 000 críticas a números inteiros, o que indica a frequência relativa de ocorrência das palavras. Cada palavra recebe um número inteiro exclusivo. A palavra mais comum recebe o número 1, a segunda palavra mais comum recebe o número 2 e assim sucessivamente.
load_datatambém devolve um par de cadeias de identificação que contêm as críticas de filmes (neste exemplo,x_trainex_test) e os 1s e 0s a classificar estas críticas como positivas e negativas (y_trainey_test).Confirme que vê a mensagem "Using TensorFlow backend" (A utilizar o back-end do TensorFlow), que indica que o Keras está a utilizar o TensorFlow como back-end.
Carregar o conjunto de dados do IMDB
Se quiser que o Keras utilize o Microsoft Cognitive Toolkit, também conhecido como CNTK, como back-end, pode fazê-lo ao adicionar linhas de código no início do bloco de notas. Por exemplo, veja CNTK e Keras no Azure Notebooks.
O que carregou a função
load_dataexatamente? A variável chamadax_trainé uma lista de 25 000 listas, sendo que cada uma representa uma crítica de filme.x_test( também é uma lista de 25.000 listas representando 25.000 avaliações.x_trainserá usada para treinamento, enquantox_testserá usada para testes.) Mas as listas internas – as que representam críticas de filmes – não contêm palavras; eles contêm números inteiros. Eis como isto é descrito na documentação do Keras:
O motivo pelo qual as listas internas contêm números em vez de texto é que uma rede neural não é preparada com texto, mas sim com números. Especificamente, é preparada com tensores. Neste caso, cada crítica é um tensor unidimensional (imagine uma matriz unidimensional) que contém números inteiros que identificam as palavras contidas na crítica. Para demonstrar, escreva a seguinte instrução do Python numa célula vazia e execute-a para ver os números inteiros que representam a primeira crítica no conjunto de preparação:
x_train[0]
Números inteiros que incluem a primeira crítica no conjunto de preparação do IMDB
O primeiro número na lista (1) não representa uma palavra. Marca o início da crítica e é igual para todas as críticas no conjunto de dados. Os números 0 e 2 também estão reservados e deve subtrair 3 dos outros números para mapear um número inteiro numa crítica ao número inteiro correspondente no dicionário. O segundo número (14) referencia a palavra que corresponde ao número 11 no dicionário, o terceiro número representa a palavra atribuída ao número 19 no dicionário e assim por diante.
Curioso para ver o aspeto de dicionário? Execute a seguinte instrução numa nova célula de bloco de notas:
imdb.get_word_index()Só é apresentado um subconjunto das entradas do dicionário, mas no total o dicionário contém mais de 88 000 palavras e os números inteiros que correspondem às mesmas. O resultado que vir não corresponderá provavelmente ao resultado na captura de ecrã, porque o dicionário é gerado novamente sempre que
load_dataé chamado.
Dicionário a mapear palavras a números inteiros
Como já reparou, cada crítica no conjunto de dados é codificada como uma coleção de números inteiros em vez de palavras. É possível efetuar a codificação inversa de uma crítica para que possa ver o texto original da mesma? Introduza as seguintes instruções numa nova célula e execute-as para mostrar a primeira crítica em
x_trainem formato textual:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))Na saída, ">" marca o início da revisão, enquanto "?" marca palavras que não estão entre as 10.000 palavras mais comuns no conjunto de dados. Estas palavras "desconhecidas" são representadas pelo algarismo 2 na lista de números inteiros que representam uma crítica. Lembra-se do parâmetro
num_wordsque passou paraload_data? É aí que entra em ação. Não reduz o tamanho do dicionário, mas restringe o intervalo de números inteiros utilizado para codificar as críticas.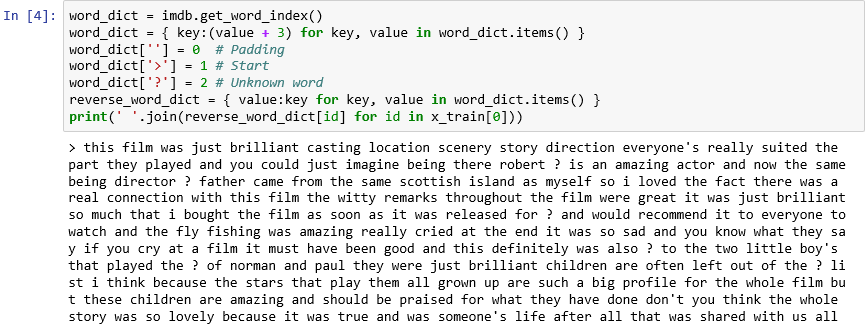
A primeira crítica em formato textual
As críticas são "puras", na medida em que as letras foram convertidas em minúsculas e os carateres de pontuação foram removidos. No entanto, não estão prontas para preparar uma rede neural para analisar texto em termos de sentimento. Quando preparar uma rede neural com uma coleção de tensores, cada tensor tem de ter o mesmo tamanho. De momento, as listas que representam as críticas em
x_trainex_testtêm tamanhos diferentes.Felizmente, o Keras inclui uma função que utiliza uma lista de listas como entrada e converte as listas internas num tamanho especificado ao truncá-las, se for necessário, ou preenchê-las com zeros. Introduza o seguinte código no bloco de notas e execute-o para forçar todas as listas que representam críticas de filmes na
x_trainex_testa um tamanho de 500 números inteiros:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Agora que os dados de preparação e testes estão prontos, está na altura de criar o modelo! Execute o seguinte código no bloco de notas para criar uma rede neural que efetua análises de sentimento:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Confirme que o resultado tem este aspeto:
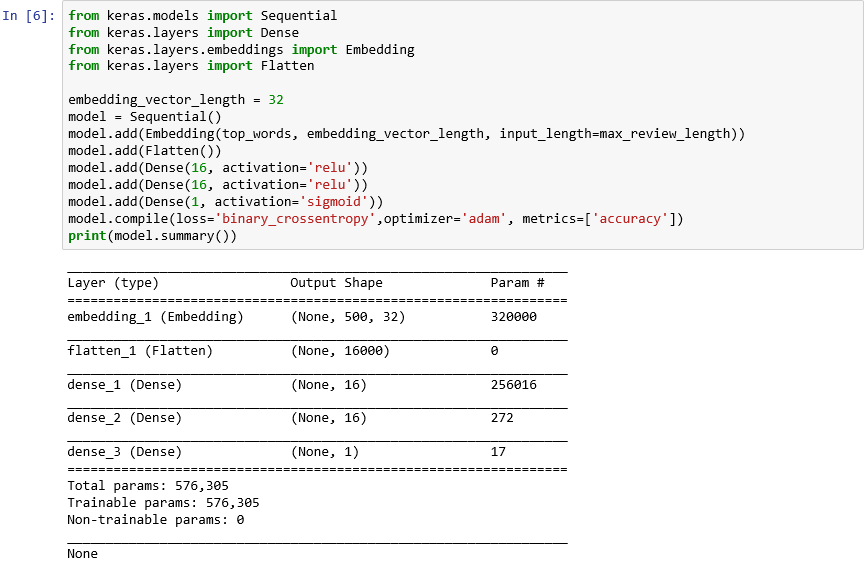
Criar uma rede neural com o Keras
Este código é a essência de como constrói uma rede neural com o Keras. Primeiro, instancia um objeto
Sequentialque representa um modelo "sequencial": um modelo que é composto por uma pilha de camadas ponto a ponto, na qual o resultado de uma camada fornece informações para a próxima.As próximas instruções adicionam camadas ao modelo. A primeira é uma camada de incorporação, que é crucial para redes neurais que processam palavras. Essencialmente, a camada de incorporação mapeia as matrizes multidimensionais, que contêm os índices de palavras de números inteiros, a matrizes de pontos flutuantes que contêm menos dimensões. Também permite que palavras com significados semelhantes sejam tratadas de forma idêntica. A abordagem completa das incorporações de palavras está para além do âmbito deste laboratório, mas pode saber mais ao ler Why You Need to Start Using Embedding Layers (Porque é Que Precisa de Começar a Utilizar Camadas de Incorporação). Se preferir uma explicação mais científica, veja Efficient Estimation of Word Representations in Vector Space (Estimativa Eficiente de Representações de Palavras no Espaço de Vetores). A chamada para Aplanar após a adição da camada de incorporação reformula o resultado para a entrada para a próxima camada.
As três camadas seguintes adicionadas ao modelo são camadas densas, também conhecidas como camadas totalmente ligadas. Estas são as camadas tradicionais que são comuns em redes neurais. Cada camada contém n nós ou neurônios, e cada neurônio recebe entrada de cada neurônio na camada anterior, daí o termo "totalmente conectado". São essas camadas que permitem que uma rede neural "aprenda" com os dados de entrada, adivinhando iterativamente a saída, verificando os resultados e ajustando as conexões para produzir melhores resultados. As duas primeiras camadas densas nesta rede contêm 16 neurónios cada. Este número foi escolhido aleatoriamente; poderá conseguir melhorar a precisão do modelo ao experimentar tamanhos diferentes. A camada densa final contém apenas um neurónio, porque o objetivo final da rede é prever um resultado, nomeadamente uma classificação de sentimento de 0,0 a 1,0.
O resultado é a rede neural ilustrada abaixo. A rede contém uma camada de entrada, uma camada de saída e duas camadas ocultas (as camadas densas contêm 16 neurónios cada). Para comparação, algumas das redes neurais mais sofisticadas atualmente têm mais de 100 camadas. Um exemplo é a ResNet-152 da Microsoft Research, cuja precisão na identificação de objetos em fotografias excede a humana em algumas ocasiões. Pode construir o ResNet-152 com o Keras, mas precisa de um cluster de computadores equipados com GPU para o preparar de raiz.
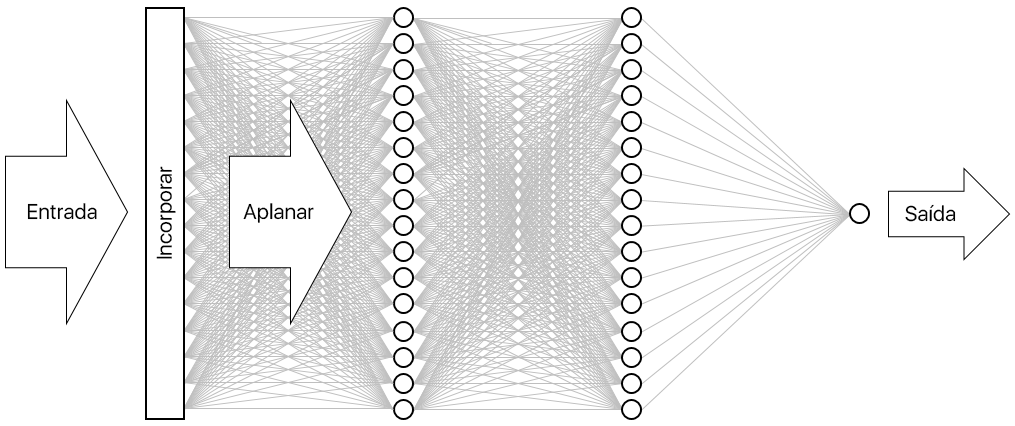
Visualizar a rede neural
A chamada para a função compile "compila" o modelo ao especificar parâmetros importantes, como qual o otimizador a utilizar e quais as métricas a utilizar para avaliar a precisão do modelo em cada passo da preparação. A preparação só começa quando chamar a função
fitdo modelo, pelo que a chamadacompileé normalmente executada rapidamente.Agora, chame a função fit para preparar a rede neural:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)A preparação deve demorar cerca de 6 minutos ou um pouco mais de 1 minuto por época. O
epochs=5indica ao Keras que efetue 5 passagens para a frente e para trás através do modelo. Com cada passagem, o modelo aprende com os dados de preparação e mede ("valida") o grau de aprendizagem com os dados de teste. Em seguida, faz ajustes e regressa para a próxima passagem ou época. Isto é refletido no resultado da funçãofit, que mostra a precisão de preparação (acc) e a precisão de validação (val_acc) para cada época.O
batch_size=128indica ao Keras para utilizar os 128 exemplos de preparação em simultâneo para preparação a rede. Os tamanhos de lote maiores aceleram o tempo de preparação (menos passagens necessárias em cada época para consumir todos os dados de preparação), mas por vezes os tamanhos de lote menores aumentam a precisão. Depois de concluir este laboratório, poderá querer voltar atrás e voltar a preparar o modelo com um tamanho de lote de 32 para ver o efeito, se houver, na precisão do modelo. Este duplica aproximadamente o tempo de preparação.
Preparar o modelo
Este modelo é invulgar, na medida em que aprende bem em poucas épocas. A precisão do treinamento aumenta rapidamente para perto de 100%, enquanto a precisão da validação aumenta por uma ou duas épocas e depois se nivela. Você geralmente não quer treinar um modelo por mais tempo do que o necessário para que essas precisões se estabilizem. Há um risco de sobreajuste, que resulta numa boa execução do modelo em relação a dados de teste, mas não tão boa em dados concretos. Uma indicação de que um modelo tem sobreajuste é uma cada vez maior discrepância entre a precisão de preparação e a precisão de validação. Para uma ótima introdução ao overfitting, consulte Overfitting in Machine Learning: What It Is and How to Prevent It.
Para visualizar as alterações na precisão de preparação e validação à medida que a preparação evolui, execute as seguintes instruções numa nova célula de bloco de notas:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()Os dados de precisão são provenientes do objeto
historydevolvido pela funçãofitdo modelo. Com base no gráfico que vê, recomendaria aumentar o número de épocas de preparação, diminuí-lo ou mantê-lo?Outra forma de verificar a existência de sobreajuste é comparar a perda de preparação com a perda de validação à medida que a preparação avança. Os problemas de otimização como este procuram minimizar uma função de perda. Pode ler mais aqui. Para uma determinada época, a perda de preparação muito maior do que a perda de validação pode ser uma prova de sobreajuste. No passo anterior, utilizou as propriedades
acceval_accda propriedadehistorydo objetohistorypara desenhar a precisão de preparação e validação. A mesma propriedade também contém valores com os nomeslosseval_loss, que representam as perdas de preparação e validação, respetivamente. Se quisesse desenhar estes valores para produzir um gráfico semelhante ao mostrado abaixo, como modificaria o código acima para o fazer?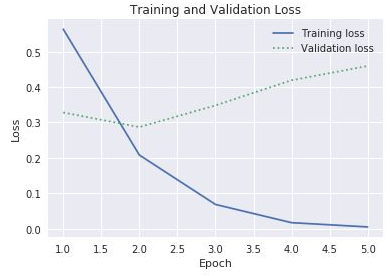
Perda de preparação e validação
Uma vez que o intervalo entre as perdas de preparação e validação começa a aumentar na terceira época, o que diria se alguém sugerisse que aumentasse o número de épocas para 10 ou 20?
Conclua ao chamar o método
evaluatedo modelo para determinar com que precisão o modelo é capaz de quantificar o sentimento expressado no texto com base nos dados de teste emx_test(críticas) ey_test(Os algarismos 0 e 1, ou "etiquetas", que indicam quais as críticas positivas e negativas):scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))O que é a precisão calculada do seu modelo?
É provável que tenha conseguido uma precisão de 85% a 90%. É aceitável, considerando que criou o modelo do início (em vez de utilizar uma rede neural pré-preparada) e o tempo de preparação foi pouco, mesmo sem uma GPU. É possível obter precisões de 95% ou superiores com arquiteturas de redes neurais alternativas, particularmente redes neurais recorrentes (RNN) que utilizam camadas de Memória de Longo/Curto Prazo (LSTM). O Keras torna mais fácil construir estas redes, mas pode aumentar exponencialmente o tempo de preparação. O modelo que criou tem um equilíbrio razoável entre a precisão e o tempo de preparação. No entanto, se quiser saber mais sobre a criação de RNN com o Keras, veja Understanding LSTM and its Quick Implementation in Keras for Sentiment Analysis (Compreender o LSTM e a Implementação Rápida no Keras para Análise de Sentimentos).