Dimensionamento com KEDA
Dimensionamento automático orientado a eventos do Kubernetes
O Kubernetes Event-driven Autoscaling (KEDA) é um componente leve e de finalidade única que simplifica o dimensionamento automático de aplicativos. Você pode adicionar o KEDA a qualquer cluster do Kubernetes e usá-lo ao lado de componentes padrão do Kubernetes, como o Horizontal Pod Autoscaler (HPA) ou o Cluster Autoscaler, para estender sua funcionalidade. Com o KEDA, você pode segmentar aplicativos específicos que deseja aproveitar o dimensionamento controlado por eventos e permitir que outros aplicativos usem métodos de dimensionamento diferentes. O KEDA é uma opção flexível e segura para ser executado ao lado de qualquer número de aplicativos ou estruturas do Kubernetes.
Principais capacidades e características
- Crie aplicativos sustentáveis e econômicos com recursos de escala até zero
- Dimensione cargas de trabalho de aplicativos para atender à demanda usando escaladores KEDA
- Dimensionamento automático de aplicações com
ScaledObjects - Trabalhos de dimensionamento automático com
ScaledJobs - Use a segurança de nível de produção desacoplando o dimensionamento automático e a autenticação das cargas de trabalho
- Traga seu próprio escalador externo para usar configurações de dimensionamento automático personalizadas
Arquitetura
A KEDA fornece dois componentes principais:
-
Operador KEDA: Permite que os usuários finais dimensionem cargas de trabalho de zero para N instâncias com suporte para Implantações do Kubernetes, Jobs, StatefulSets, ou qualquer recurso do cliente que defina um
/scalesubrecurso. - Servidor de métricas: expõe métricas externas ao HPA, como mensagens em um tópico do Kafka ou eventos nos Hubs de Eventos do Azure, para impulsionar ações de dimensionamento automático. Devido a limitações upstream, o servidor de métricas KEDA deve ser o único adaptador de métricas instalado no cluster.
O diagrama a seguir mostra como o KEDA se integra ao Kubernetes HPA, fontes de eventos externas e Kubernetes API Server para fornecer funcionalidade de dimensionamento automático:
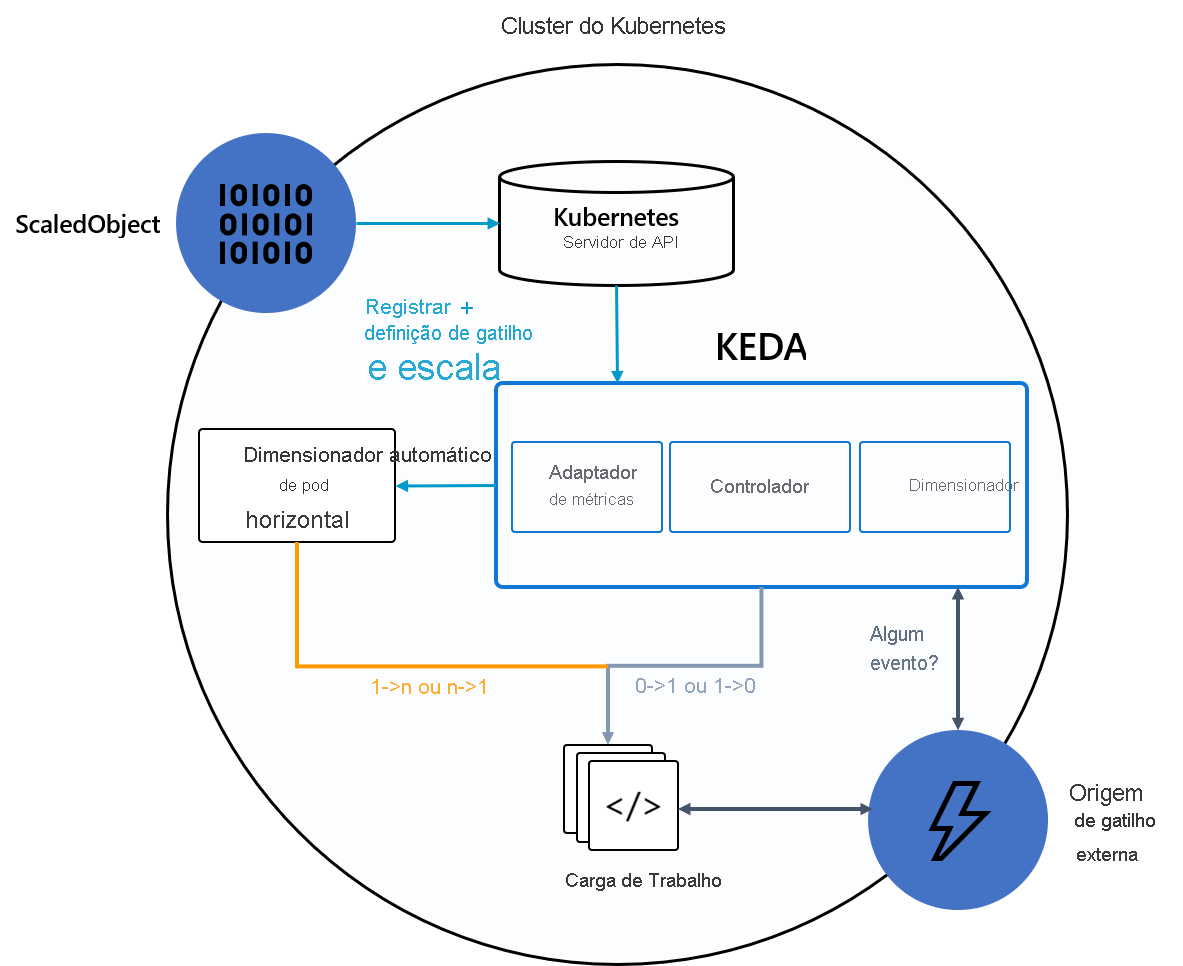
Gorjeta
Para obter mais informações, consulte a documentação oficial da KEDA.
Fontes de eventos e escaladores
Os escaladores KEDA podem detetar se uma implantação deve ser ativada ou desativada e alimentar métricas personalizadas para uma fonte de evento específica. Implantações e StatefulSets são a maneira mais comum de dimensionar cargas de trabalho com o KEDA. Você também pode dimensionar recursos personalizados que implementam o /scale subrecurso. Você pode definir a Implantação do Kubernetes ou StatefulSet que deseja que o KEDA dimensione com base em um gatilho de escala. A KEDA monitora esses serviços e os dimensiona automaticamente com base nos eventos que ocorrem.
Nos bastidores, o KEDA monitora a origem do evento e alimenta esses dados para o Kubernetes e o HPA para impulsionar o rápido dimensionamento de recursos. Cada réplica de um recurso extrai ativamente itens da fonte do evento. Com o KEDA e Deployments/StatefulSetso , você pode dimensionar com base em eventos e, ao mesmo tempo, preservar a conexão avançada e a semântica de processamento com a fonte do evento (por exemplo, processamento em ordem, tentativas, carta morta ou ponto de verificação).
Especificação de objeto dimensionado
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Especificação de trabalho dimensionada
Como alternativa ao dimensionamento de código controlado por eventos como Implantações, você também pode executar e dimensionar seu código como um Trabalho do Kubernetes. A principal razão para considerar essa opção é se você precisa processar execuções de longa duração. Em vez de processar vários eventos dentro de uma implantação, cada evento detetado agenda seu próprio trabalho do Kubernetes. Essa abordagem permite processar cada evento isoladamente e dimensionar o número de execuções simultâneas com base no número de eventos na fila.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}