Tutorial: criar e implantar um projeto SQL
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Banco de Dados SQL no Microsoft Fabric
Banco de Dados SQL no Microsoft Fabric
O ciclo de desenvolvimento de um projeto de banco de dados SQL permite que o desenvolvimento de banco de dados seja integrado a fluxos de trabalho de CI/CD (integração contínua e implantação contínua) familiarizados como uma prática recomendada de desenvolvimento. Embora a implantação de um projeto de banco de dados SQL possa ser feita manualmente, é recomendável usar um pipeline de implantação para automatizar o processo de implantação, de modo que as implantações contínuas sejam executadas com base no desenvolvimento local contínuo sem esforço adicional.
Este artigo aborda a criação de um novo projeto SQL, a adição de objetos ao projeto e a configuração de um pipeline de implantação contínua para criar e implantar o projeto com o GitHub Actions. O tutorial é um superconjunto do conteúdo do artigo de Introdução a projetos SQL. Embora o tutorial implemente o pipeline de implantação no GitHub Actions, os mesmos conceitos se aplicam ao Azure DevOps, ao GitLab e a outros ambientes de automação.
Neste tutorial, você:
- Criar um novo projeto SQL
- Adicionar objetos ao projeto
- Compilar o projeto localmente
- Verificar o projeto para o controle do código-fonte
- Adicionar uma etapa de build de projeto a um pipeline de implantação contínua
- Adicionar uma etapa de implantação
.dacpaca um pipeline de implantação contínua
Se você já concluiu as etapas no artigo de Introdução a projetos SQL, pode pular para a etapa 4. No final deste tutorial, seu projeto SQL criará e implantará automaticamente as alterações em um banco de dados de destino.
Pré-requisitos
# install SqlPackage CLI
dotnet tool install -g Microsoft.SqlPackage
# install Microsoft.Build.Sql.Templates
dotnet new install Microsoft.Build.Sql.Templates
Verifique se você tem os seguintes itens para concluir a configuração do pipeline no GitHub:
Uma conta do GitHub, na qual você pode criar um repositório. Crie um gratuitamente.
O GitHub Actions está habilitado em seu repositório.
Observação
Para concluir a implantação de um projeto de banco de dados SQL, você precisa de acesso a uma instância do SQL ou do SQL Server do Azure. Você pode desenvolver localmente de graça com a edição do SQL Server Developer no Windows ou em contêineres.
Etapa 1: Criar um projeto
Começamos nosso projeto criando um novo projeto de banco de dados SQL antes de adicionar objetos manualmente a ele. Há outras maneiras de criar um projeto que permitem o preenchimento imediato do projeto com objetos de um banco de dados existente, como usar as ferramentas de comparação de esquema.
Selecione Arquivo, Novo e, em seguida, Projeto.
Na caixa de diálogo Novo Projeto, use o termo SQL Server na caixa de pesquisa. O resultado principal deve ser Projeto de Banco de Dados do SQL Server.

Selecione Avançar para prosseguir para a próxima etapa. Forneça um nome de projeto, que não precisa corresponder a um nome de banco de dados. Verifique e modifique o local do projeto conforme necessário.
Selecione Criar para criar o cluster. O projeto vazio será aberto e ficará visível no Gerenciador de Soluções para edição.
Selecione Arquivo, Novo e, em seguida, Projeto.
Na caixa de diálogo Novo Projeto, use o termo SQL Server na caixa de pesquisa. O resultado principal deve ser Projeto de Banco de Dados do SQL Server, estilo SDK (versão prévia).

Selecione Avançar para prosseguir para a próxima etapa. Forneça um nome de projeto, que não precisa corresponder a um nome de banco de dados. Verifique e modifique o local do projeto conforme necessário.
Selecione Criar para criar o cluster. O projeto vazio será aberto e ficará visível no Gerenciador de Soluções para edição.
Na exibição Projetos de Banco de Dados do VS Code ou do Azure Data Studio, selecione o botão Novo Projeto.
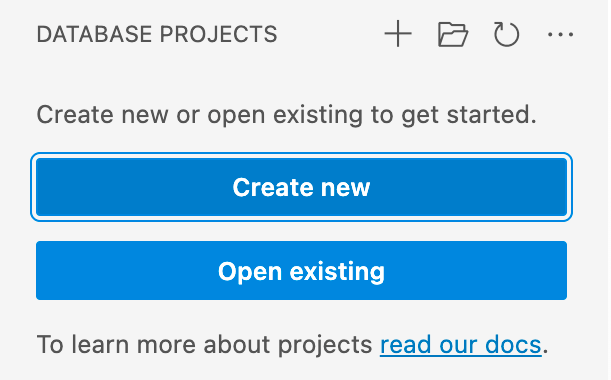
O primeiro prompt determina qual modelo de projeto usar, principalmente com base no fato de a plataforma de destino ser SQL Server ou SQL do Azure. Se solicitada a seleção de uma versão específica do SQL, escolha a versão que corresponde ao banco de dados de destino, mas se a versão do banco de dados de destino for desconhecida, escolha a versão mais recente, pois o valor pode ser modificado posteriormente.
Insira um nome de projeto na entrada de texto exibida, que não precisa corresponder a um nome de banco de dados.
Na caixa de diálogo "Selecionar uma Pasta" exibida, selecione um diretório para a pasta do projeto, o arquivo .sqlproj e outros conteúdos.
Quando perguntado se deseja criar um projeto no estilo SDK (versão prévia), selecione Sim.
Depois de concluído, o projeto vazio será aberto e ficará visível na exibição Projetos de banco de dados para edição.
Com os modelos .NET para projetos Microsoft.Build.Sql instalados, você pode criar um novo projeto de banco de dados SQL na linha de comando. A opção -n especifica o nome do projeto e a opção -tp especifica a plataforma de destino do projeto.
Use a opção -h para ver todas as opções disponíveis.
# install Microsoft.Build.Sql.Templates
dotnet new sqlproject -n MyDatabaseProject
Etapa 2: adicionar objetos ao projeto
No Gerenciador de Soluções, clique com o botão direito do mouse no nó do projeto e selecione Adicionar, em seguida, selecione Tabela. A caixa de diálogo Adicionar Novo Item é exibida, onde você pode especificar o nome da tabela. Selecione Adicionar para criar a tabela no projeto SQL.
A tabela é aberta no designer de tabela do Visual Studio com a definição de tabela de modelo, onde você pode adicionar colunas, índices e outras propriedades de tabela. Salve o arquivo quando terminar de fazer as edições iniciais.
Mais objetos de banco de dados podem ser adicionados por meio da caixa de diálogo Adicionar Novo Item, como exibições, procedimentos armazenados e funções. Acesse a caixa de diálogo clicando com o botão direito do mouse no nó do projeto no Gerenciador de Soluções e selecionando Adicionar e, em seguida, o tipo de objeto desejado. Os arquivos no projeto podem ser organizados em pastas por meio da opção Nova pasta em Adicionar.
No Gerenciador de Soluções, clique com o botão direito do mouse no nó do projeto e selecione Adicionar, e depois em Novo Item. A caixa de diálogo Adicionar Novo Item é exibida, selecione Mostrar Todos os Modelos e, em seguida, Tabela. Especifique o nome da tabela como o nome do arquivo e selecione Adicionar para criar a tabela no projeto SQL.
A tabela é aberta no editor de consultas do Visual Studio com a definição da tabela de modelo, onde você pode adicionar colunas, índices e outras propriedades da tabela. Salve o arquivo quando terminar de fazer as edições iniciais.
Mais objetos de banco de dados podem ser adicionados por meio da caixa de diálogo Adicionar Novo Item, como exibições, procedimentos armazenados e funções. Acesse a caixa de diálogo clicando com o botão direito do mouse no nó do projeto no Gerenciador de Soluções e selecionando Adicionar e, em seguida, o tipo de objeto desejado depois de Exibir Todos os Modelos. Os arquivos no projeto podem ser organizados em pastas por meio da opção Nova pasta em Adicionar.
Na exibição Projetos de Banco de Dados do VS Code ou do Azure Data Studio, clique com o botão direito do mouse no nó do projeto e selecione Adicionar Tabelas. Na caixa de diálogo exibida, especifique o nome da tabela.
A tabela é aberta no editor de texto com a definição da tabela de modelo, onde você pode adicionar colunas, índices e outras propriedades da tabela. Salve o arquivo quando terminar de fazer as edições iniciais.
Mais objetos de banco de dados podem ser adicionados por meio do menu de contexto no nó do projeto, como exibições, procedimentos armazenados e funções. Acesse a caixa de diálogo clicando com o botão direito do mouse no nó do projeto na exibição Projetos de Banco de Dados do VS Code ou do Azure Data Studio e, em seguida, no tipo de objeto desejado. Os arquivos no projeto podem ser organizados em pastas por meio da opção Nova pasta em Adicionar.
Os arquivos podem ser adicionados ao projeto criando-os no diretório do projeto ou nas pastas aninhadas. A extensão do arquivo deve ser .sql e a organização por tipo de objeto ou esquema e tipo de objeto é recomendada.
O modelo base de uma tabela pode ser usado como ponto de partida para criar um novo objeto de tabela no projeto:
CREATE TABLE [dbo].[Table1]
(
[Id] INT NOT NULL PRIMARY KEY
)
Etapa 3: compilar o projeto
O processo de build valida as relações entre objetos e a sintaxe em relação à plataforma de destino especificada no arquivo de projeto. A saída do artefato do processo de build é um arquivo .dacpac, que pode ser usado para implantar o projeto em um banco de dados de destino e contém o modelo compilado do esquema de banco de dados.
No Gerenciador de Soluções, clique com o botão direito do mouse no nó do projeto e selecione Compilar.
A janela de saída é aberta automaticamente para exibir o processo de build. Se houver erros ou avisos, eles serão exibidos na janela de saída. Em uma compilação bem-sucedida, o artefato de compilação (arquivo .dacpac) é criado, sua localização é incluída na saída da compilação (o padrão é bin\Debug\projectname.dacpac).
No Gerenciador de Soluções, clique com o botão direito do mouse no nó do projeto e selecione Compilar.
A janela de saída é aberta automaticamente para exibir o processo de build. Se houver erros ou avisos, eles serão exibidos na janela de saída. Em uma compilação bem-sucedida, o artefato de compilação (arquivo .dacpac) é criado, sua localização é incluída na saída da compilação (o padrão é bin\Debug\projectname.dacpac).
Na exibição Projetos de Banco de Dados do VS Code ou do Azure Data Studio, clique com o botão direito do mouse no nó do projeto e selecione Compilar.
A janela de saída é aberta automaticamente para exibir o processo de build. Se houver erros ou avisos, eles serão exibidos na janela de saída. Em uma compilação bem-sucedida, o artefato de compilação (arquivo .dacpac) é criado, sua localização é incluída na saída da compilação (o padrão é bin/Debug/projectname.dacpac).
Os projetos de banco de dados SQL podem ser criados a partir da linha de comando usando o comando dotnet build.
dotnet build
# optionally specify the project file
dotnet build MyDatabaseProject.sqlproj
A saída do build inclui quaisquer erros ou avisos e os arquivos específicos e números de linha onde eles ocorrem. Em uma compilação bem-sucedida, o artefato de compilação (arquivo .dacpac) é criado, sua localização é incluída na saída da compilação (o padrão é bin/Debug/projectname.dacpac).
Etapa 4: verificar o projeto para o controle do código-fonte
Inicializaremos nosso projeto como um repositório Git e faremos commit dos arquivos do projeto no controle do código-fonte. Essa etapa é necessária para permitir que o projeto seja compartilhado com outras pessoas e usado em um pipeline de implantação contínua.
No menu Git no Visual Studio, selecione Criar Repositório Git.
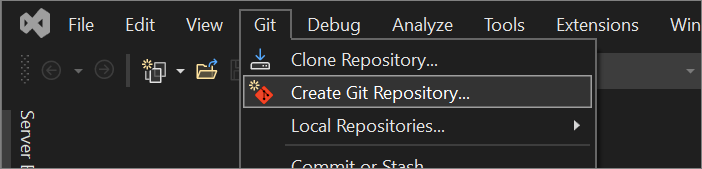
No diálogo Criar um repositório Git, em Efetuar push para uma nova seção remota, escolha GitHub.
Na seção Criar um repositório GitHub do diálogo Criar um repositório Git, insira o nome do repositório que você deseja criar. Se você ainda não entrou na sua conta do GitHub, também pode fazer isso nessa tela.
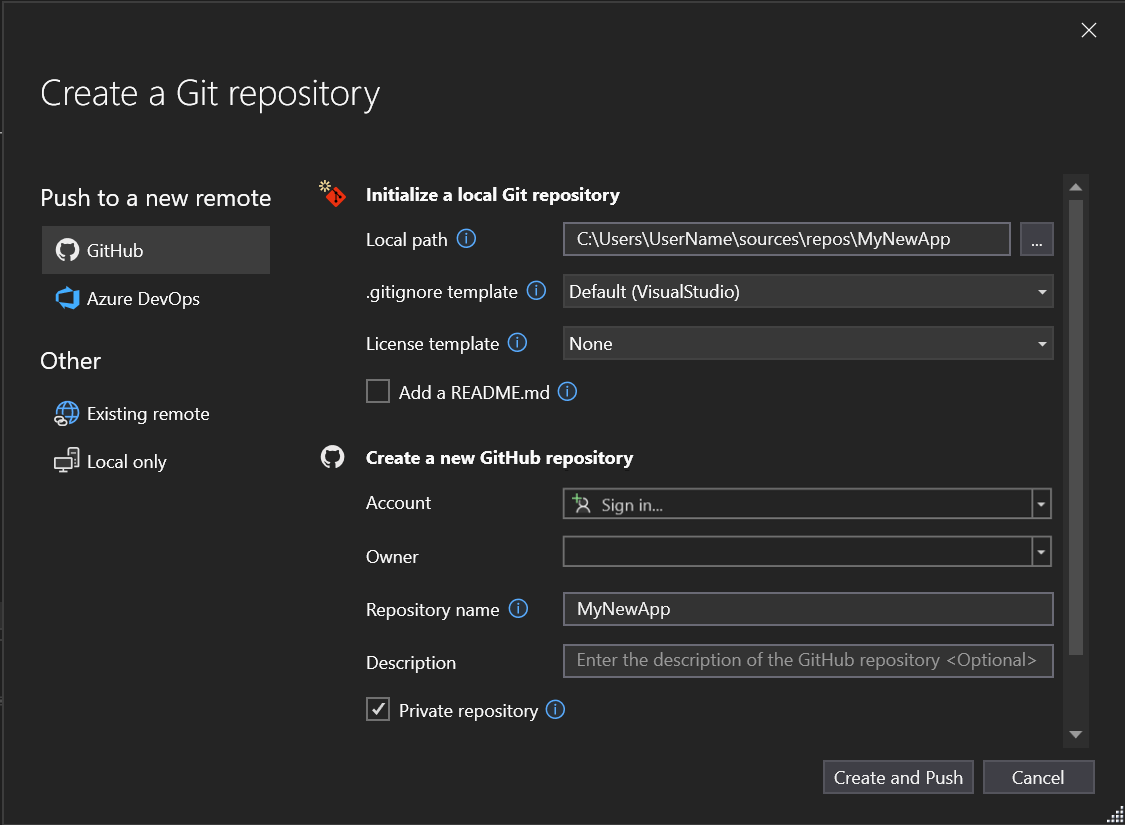
Em Inicializar um Repositório Git local, você deve usar a opção de modelo .gitignore para especificar intencionalmente arquivos não rastreados que você deseja que o Git ignore. Para saber mais sobre o .gitignore, confira Como ignorar arquivos. E para saber mais sobre licenciamento, confira Como licenciar um repositório.
Depois de entrar e inserir as informações do repositório, selecione o botão Criar e Efetuar Push para criar seu repositório e adicionar seu aplicativo.

No Gerenciador de Soluções, clique com o botão direito do mouse no nó do projeto e selecione Publicar….
A caixa de diálogo de publicação é aberta, onde você estabelece a conexão do banco de dados de destino. Se você não tiver uma instância SQL existente para implantação, o LocalDB ((localdb)\MSSQLLocalDB) será instalado com o Visual Studio e poderá ser usado para teste e desenvolvimento.
Especifique um nome de banco de dados e selecione Publicar para implantar o projeto no banco de dados de destino ou Gerar Script para gerar um script para revisar antes de executar.
Você pode inicializar um repositório local e publicá-lo diretamente no GitHub do VS Code ou do Azure Data Studio. Essa ação cria um novo repositório em sua conta do GitHub e envia suas alterações de código local para o repositório remoto em uma única etapa.
Use o botão Publicar no GitHub na exibição Controle do Código-Fonte no VS Code ou no Azure Data Studio. Em seguida, será solicitado que você especifique um nome e uma descrição para o repositório e também se deseja torná-lo público ou privado.

Como alternativa, você pode inicializar um repositório local e enviá-lo por push para o GitHub seguindo as etapas fornecidas ao criar um repositório vazio no GitHub.
Inicialize um novo repositório Git no diretório do projeto e confirme os arquivos do projeto no controle do código-fonte.
git init
git add .
git commit -m "Initial commit"
Crie um novo repositório no GitHub e envie o repositório local por push para o repositório remoto.
git remote add origin <repository-url>
git push -u origin main
Etapa 5: Adicionar uma etapa de build de projeto a um pipeline de implantação contínua
Os projetos SQL são apoiados por uma biblioteca .NET e, como resultado, os projetos são criados com o comando dotnet build. Esse comando é um elemento básico até mesmo dos pipelines mais básicos de CI/CD (integração contínua e implantação contínua). A etapa de build pode ser adicionada a um pipeline de implantação contínua que criamos no GitHub Actions.
Na raiz do repositório, crie um novo diretório chamado
.github/workflows. Esse diretório conterá o arquivo de fluxo de trabalho que define o pipeline de implantação contínua.No diretório
.github/workflows, crie um novo arquivo nomeadosqlproj-sample.yml.Adicione o seguinte conteúdo ao arquivo
sqlproj-sample.yml, editando o nome do projeto para corresponder ao nome e ao caminho do seu projeto:name: sqlproj-sample on: push: branches: [ "main" ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Setup .NET uses: actions/setup-dotnet@v4 with: dotnet-version: 8.0.x - name: Build run: dotnet build MyDatabaseProject.sqlprojConfirme o arquivo de fluxo de trabalho no repositório e envie as alterações por push para o repositório remoto.
No GitHub, acesse a página principal do repositório. Abaixo do nome do seu repositório, clique em Ações. Na barra lateral esquerda, selecione o fluxo de trabalho que você criou agora. Uma execução recente do fluxo de trabalho deve aparecer na lista de execuções de fluxo de trabalho a partir do momento em que você enviou o arquivo de fluxo de trabalho por push para o repositório.
Mais informações sobre os conceitos básicos da criação do seu primeiro fluxo de trabalho do GitHub Actions estão disponíveis no Início rápido do GitHub Actions.
Etapa 6: adicionar uma etapa de implantação .dacpac a um pipeline de implantação contínua
O modelo compilado de um esquema de banco de dados em um arquivo .dacpac pode ser implantado em um banco de dados de destino usando a ferramenta de linha de comando SqlPackage ou outras ferramentas de implantação. O processo de implantação determina as etapas necessárias para atualizar o banco de dados de destino para corresponder ao esquema definido no .dacpac, criando ou alterando objetos conforme necessário com base nos objetos já existentes no banco de dados. Por exemplo, para implantar um arquivo .dacpac em um banco de dados de destino com base em uma cadeia de conexão:
sqlpackage /Action:Publish /SourceFile:bin/Debug/MyDatabaseProject.dacpac /TargetConnectionString:{yourconnectionstring}

O processo de implantação é idempotente, o que significa que pode ser executado várias vezes sem causar problemas. O pipeline que estamos criando criará e implantará nosso projeto SQL sempre que uma alteração for verificada no branch main do nosso repositório. Em vez de executar o comando SqlPackage diretamente em nosso pipeline de implantação, podemos usar uma tarefa de implantação que abstrai o comando e fornece recursos adicionais, como registro em log, tratamento de erros e configuração de tarefas. A tarefa de implantação GitHub sql-action pode ser adicionada a um pipeline de implantação contínua no GitHub Actions.
Observação
A execução de uma implantação a partir de um ambiente de automação requer a configuração do banco de dados e do ambiente de forma que a implantação possa acessar o banco de dados e autenticar. No Banco de Dados SQL do Azure ou no SQL Server em uma VM, isso pode exigir a configuração de uma regra de firewall para permitir que o ambiente de automação se conecte ao banco de dados, bem como fornecer uma cadeia de conexão com as credenciais necessárias. As diretrizes são fornecidas na documentação do GitHub sql-action.
Abra o arquivo
sqlproj-sample.ymlno diretório.github/workflows.Adicione a seguinte etapa ao arquivo
sqlproj-sample.ymlapós a etapa de compilação:- name: Deploy uses: azure/sql-action@v2 with: connection-string: ${{ secrets.SQL_CONNECTION_STRING }} action: 'publish' path: 'bin/Debug/MyDatabaseProject.dacpac'Antes de confirmar as alterações, adicione um segredo ao repositório que contém a cadeia de conexão com o banco de dados de destino. No repositório no GitHub.com, navegue até Configurações, depois, até Segredos. Selecione Novo segredo do repositório e adicione um segredo chamado
SQL_CONNECTION_STRINGcom o valor da cadeia de conexão ao banco de dados de destino.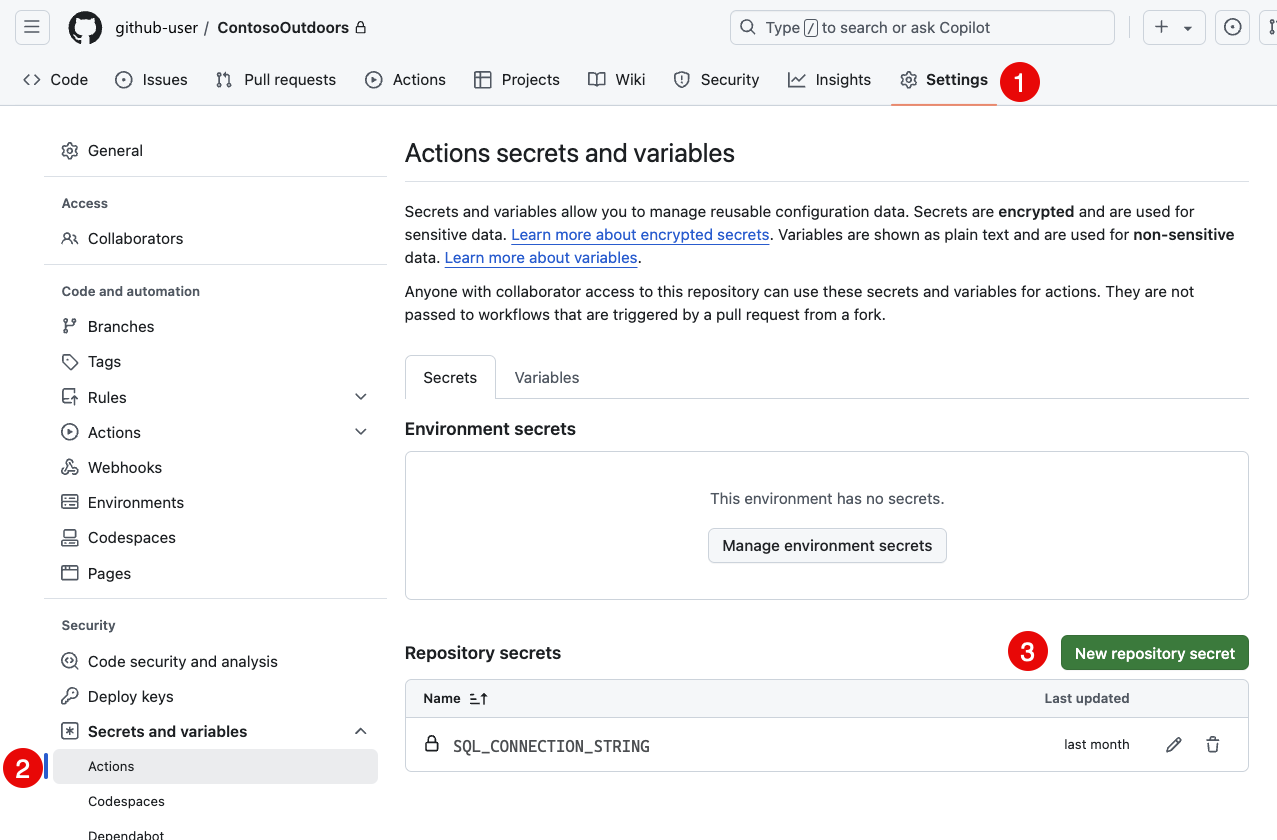
Confirme as alterações do repositório
sqlproj-sample.ymle envie as alterações para o repositório remoto.Navegue de volta para o histórico do fluxo de trabalho no GitHub.com e selecione a execução mais recente do fluxo de trabalho. A etapa de implantação deve estar visível na lista de etapas para a execução do fluxo de trabalho e o fluxo de trabalho retorna um código de êxito.
Verifique a implantação conectando-se ao banco de dados de destino e verificando se os objetos no projeto estão presentes no banco de dados.

As implantações do GitHub podem ser ainda mais protegidas estabelecendo uma relação de ambiente em um fluxo de trabalho e exigindo aprovação antes que uma implantação seja executada. Mais informações sobre proteção de ambiente e proteção de segredos estão disponíveis na Documentação do Github Actions.