Guia de arquitetura de threads e tarefas
Aplica-se a:![]() SQL Server
SQL Server![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Instância Gerenciada SQL do Azure
Instância Gerenciada SQL do Azure
Agendamento de tarefas do sistema operacional
Os threads são as menores unidades de processamento executadas por um sistema operacional e permitem que a lógica do aplicativo seja separada em vários caminhos de execução simultâneos. Os threads são úteis quando aplicativos complexos têm muitas tarefas que podem ser executadas ao mesmo tempo.
Quando um sistema operacional executa uma instância de um aplicativo, ele cria uma unidade chamada processo para gerenciar a instância. O processo tem um thread de execução. Esta é a série de instruções de programação executadas pelo código do aplicativo. Por exemplo, se um aplicativo simples tiver um único conjunto de instruções que podem ser executadas em série, esse conjunto de instruções será tratado como uma única tarefa e haverá apenas um caminho de execução (ou thread) através do aplicativo. Aplicativos mais complexos podem ter várias tarefas que podem ser executadas simultaneamente em vez de em série. Um aplicativo pode fazer isso iniciando processos separados para cada tarefa, que é uma operação que consome muitos recursos, ou iniciar threads separados, que são relativamente menos intensivos em recursos. Além disso, cada thread pode ser agendado para execução independentemente dos outros threads associados a um processo.
Os threads permitem que aplicações complexas façam um uso mais eficaz de um processador (CPU), mesmo em computadores que têm uma única CPU. Com uma CPU, apenas um thread pode ser executado de cada vez. Se um thread executa uma operação de longa duração que não usa a CPU, como uma leitura ou gravação de disco, outro dos threads pode ser executado até que a primeira operação seja concluída. Ao ser capaz de executar threads enquanto outras threads aguardam a conclusão de uma operação, uma aplicação pode maximizar o uso da CPU. Isso é especialmente verdadeiro para aplicativos multiusuários com uso intensivo de E/S de disco, como um servidor de banco de dados. Os computadores que têm várias CPUs podem executar um thread por CPU ao mesmo tempo. Por exemplo, se um computador tiver oito CPUs, ele pode executar oito threads ao mesmo tempo.
Agendamento de tarefas do SQL Server
No âmbito do SQL Server, um de solicitação é a representação lógica de uma consulta ou batch. Uma solicitação também representa operações exigidas por threads do sistema, como ponto de verificação ou gravador de log. As solicitações existem em vários estados ao longo de sua vida útil e podem acumular esperas quando os recursos necessários para executar a solicitação não estão disponíveis, como bloqueios de ou travas de . Para obter mais informações sobre estados de solicitação, consulte sys.dm_exec_requests.
Tarefas
Uma tarefa representa a unidade de trabalho que precisa ser concluída para atender à solicitação. Uma ou mais tarefas podem ser atribuídas a uma única solicitação.
- As solicitações paralelas têm várias tarefas ativas que são executadas simultaneamente em vez de em série, com uma tarefa pai (ou tarefa de coordenação) e várias tarefas filho. Um plano de execução para uma solicitação paralela pode ter ramificações seriais - áreas do plano com operadores que não executam em paralelo. A tarefa pai também é responsável pela execução desses operadores seriais.
- As solicitações seriais têm apenas uma tarefa ativa em um determinado momento durante a execução. As tarefas existem em vários estados ao longo do seu ciclo de vida. Para obter mais informações sobre estados de tarefas, consulte sys.dm_os_tasks. As tarefas no estado SUSPENSO aguardam que os recursos necessários para executar a tarefa fiquem disponíveis. Para obter mais informações sobre tarefas em espera, consulte sys.dm_os_waiting_tasks.
Trabalhadores
Um processo de trabalho do SQL Server , também conhecido como worker ou thread, é uma representação lógica de um processo do sistema operacional. Ao executar solicitações seriais, o Mecanismo de Banco de Dados do SQL Server gera um trabalhador para executar a tarefa ativa (1:1). Ao executar solicitações paralelas no modo de linha , o Mecanismo de Banco de Dados do SQL Server atribui um trabalhador encarregado de coordenar os trabalhadores filhos responsáveis pela conclusão de tarefas atribuídas a eles (também 1:1), chamado de thread principal (ou thread de coordenação). A thread principal tem uma tarefa principal associada a ele. O thread pai é o ponto de entrada da solicitação e existe antes mesmo do mecanismo analisar uma consulta. As principais responsabilidades do segmento pai são:
- Coordene uma verificação paralela.
- Inicie trabalhadores filhos em paralelo.
- Colete linhas de threads paralelas e envie-as para o cliente.
- Execute agregações locais e globais.
Observação
Se um plano de consulta tiver ramificações seriais e paralelas, uma das tarefas paralelas será responsável pela execução da ramificação serial.
O número de threads de trabalho criados para cada tarefa depende:
Se a solicitação era elegível para paralelismo, conforme determinado pelo Otimizador de Consulta.
Qual é o grau de paralelismo (DOP) realmente disponível no sistema com base na carga atual. Isso pode diferir do DOP estimado, que se baseia na configuração do servidor para o grau máximo de paralelismo (MAXDOP). Por exemplo, a configuração do servidor para MAXDOP pode ser 8, mas o DOP disponível em tempo de execução pode ser apenas 2, o que afeta o desempenho da consulta. A pressão de memória e a falta de trabalhadores são duas condições que reduzem o DOP disponível em tempo de execução.
Observação
O limite de grau máximo de paralelismo (MAXDOP) , definido por, é atribuído para cada tarefa, e não para cada solicitação. Isso significa que, durante a execução de uma consulta paralela, uma única solicitação pode gerar várias tarefas até o limite MAXDOP e cada tarefa usará um trabalhador. Para obter mais informações sobre MAXDOP, consulte Configurar o grau máximo de paralelismo Opção de configuração do servidor.
Agendadores
Um agendador , também conhecido como agendador SOS, gerencia threads de trabalho que exigem tempo de processamento para realizar tarefas. Cada agendador é mapeado para um processador individual (CPU). O tempo que um trabalhador pode permanecer ativo em um agendador é chamado de OS quantum, com um máximo de 4 ms. Depois que seu tempo quântico expira, um trabalhador cede seu tempo para outros trabalhadores que precisam acessar recursos da CPU e altera seu estado. Essa cooperação entre os trabalhadores para maximizar o acesso aos recursos da CPU é chamada de agendamento cooperativo , também conhecido como agendamento não preventivo. Por sua vez, a alteração no estado do trabalhador é propagada para a tarefa associada a esse trabalhador e para a solicitação associada à tarefa. Para obter mais informações sobre estados de trabalho, consulte sys.dm_os_workers. Para obter mais informações sobre agendadores, consulte sys.dm_os_schedulers.
Em resumo, um pedido pode gerar uma ou mais tarefas para realizar unidades de trabalho. Cada tarefa é atribuída a um thread de trabalho que é responsável pela conclusão da tarefa. Cada thread de trabalho deve ser agendado (colocado em um agendador de ) para a execução ativa da tarefa.
Considere o seguinte cenário:
- A Tarefa 1 é uma tarefa de longa execução, por exemplo, uma consulta de leitura de dados usando leitura antecipada em tabelas armazenadas no disco. O Worker 1 descobre que suas páginas de dados necessárias já estão no Buffer Pool, portanto, ele não precisa ceder para esperar pelas operações de E/S e pode consumir seu quantum completo antes de produzir.
- O trabalhador 2 está fazendo tarefas mais curtas de submilissegundos e, portanto, é obrigado a ceder antes que seu quantum completo se esgote.
Neste cenário e até ao SQL Server 2014 (12.x), é permitido ao Trabalhador 1 basicamente monopolizar o agendador por ter mais tempo quântico geral.
A partir do SQL Server 2016 (13.x), o agendamento cooperativo inclui o agendamento LDF (Large Deficit First). Com o agendamento LDF, os padrões de uso quântico são monitorados e um thread de trabalho não monopoliza um agendador. No mesmo cenário, o Trabalhador 2 pode consumir quantums repetidos antes que o Trabalhador 1 tenha mais quantum, evitando assim que o Trabalhador 1 monopolize o agendador de forma prejudicial.
Cronograma de tarefas paralelas
Imagine um SQL Server configurado com MaxDOP 8 e o CPU Affinity está configurado para 24 CPUs (agendadores) nos nós NUMA 0 e 1. Os agendadores 0 a 11 pertencem ao nó NUMA 0, os agendadores 12 a 23 pertencem ao nó NUMA 1. Um aplicativo envia a seguinte consulta (solicitação) para o Mecanismo de Banco de Dados:
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
Dica
A consulta de exemplo pode ser executada usando o banco de dados de exemplo AdventureWorks2016_EXT banco de dados. As tabelas Sales.SalesOrderHeader e Sales.SalesOrderDetail foram ampliadas 50 vezes e renomeadas para Sales.SalesOrderHeaderBulk e Sales.SalesOrderDetailBulk.
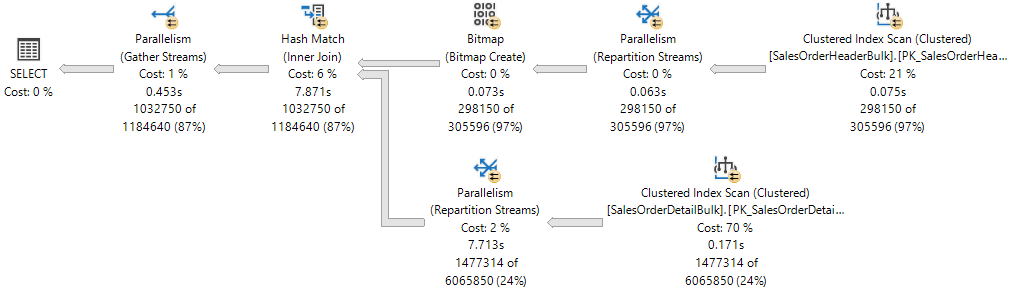
O plano de execução mostra um Hash Join entre duas tabelas, e cada um dos operadores executados em paralelo, conforme indicado pelo círculo amarelo com duas setas. Cada operador de paralelismo é uma ramificação diferente no plano. Portanto, há três ramos no plano de execução a seguir.
Observação
Se você pensar em um plano de execução como uma árvore, uma ramificação é uma área do plano que agrupa um ou mais operadores entre operadores de paralelismo, também chamados de iteradores do Exchange. Para obter mais informações sobre operadores de planos, consulte Showplan Logical and Physical Operators Reference.
Embora existam três ramificações no plano de execução, em qualquer ponto durante a execução apenas duas ramificações podem executar simultaneamente neste plano de execução:
- A ramificação onde uma verificação de índice clusterizado de é usada no
Sales.SalesOrderHeaderBulk(entrada de compilação da junção) é executada sozinha. - Em seguida, a ramificação onde é usada uma verificação de índice clusterizado no
Sales.SalesOrderDetailBulk(entrada de teste da associação) executa-se simultaneamente com a ramificação onde o bitmap foi criado e, atualmente, está sendo executada a correspondência de hash .
O XML do Showplan mostra que 16 worker threads foram reservadas e usadas no nó NUMA 0.
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
A reserva de threads garante que o Mecanismo de Banco de Dados tenha threads de trabalho suficientes para executar todas as tarefas necessárias para a solicitação. Os threads podem ser reservados em vários nós NUMA ou ser reservados em apenas um nó NUMA. A reserva de thread é feita em tempo de execução antes do início da execução e depende da carga do agendador. O número de tarefas reservadas é, de forma genérica, derivado da fórmula concurrent branches * runtime DOP e exclui a tarefa principal. Cada ramificação é limitada a um número de threads de trabalho igual ao MaxDOP. Neste exemplo, há duas ramificações simultâneas e MaxDOP é definido como 8, portanto, 2 * 8 = 16.
Para referência, observe o plano de execução ao vivo do Live Query Statistics, onde uma ramificação foi concluída e duas ramificações estão sendo executadas simultaneamente.
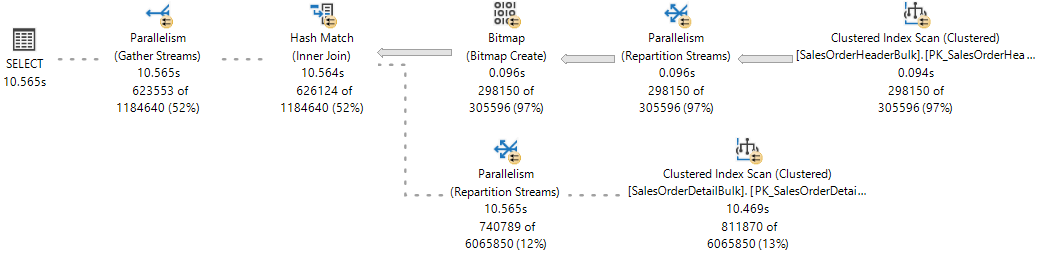
O Mecanismo de Banco de Dados do SQL Server atribui um thread de trabalho para executar uma tarefa ativa (1:1), que pode ser observada durante a execução da consulta consultando o sys.dm_os_tasks DMV, como visto no exemplo a seguir:
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
Dica
A coluna parent_task_address é sempre NULL para a tarefa pai.
Dica
Em um Mecanismo de Banco de Dados do SQL Server muito ocupado, é possível ver várias tarefas ativas que estão acima do limite definido por threads reservados. Essas tarefas podem pertencer a um ramo que não está mais sendo usado e estão em um estado transitório, aguardando limpeza.
Aqui está o conjunto de resultados. Note que existem 17 tarefas ativas para as ramificações que estão a ser executadas no momento: 16 tarefas subordinadas correspondentes às sequências reservadas, mais a tarefa mãe ou de coordenação.
| endereço_da_tarefa_pai | task_address | estado_da_tarefa | scheduler_id | endereço_do_trabalhador |
|---|---|---|---|---|
| NULO | 0x000001EF4758ACA8 |
SUSPENSO | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | SUSPENSO | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | SUSPENSO | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | SUSPENSO | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | SUSPENSO | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | SUSPENSO | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | SUSPENSO | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | SUSPENSO | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | SUSPENSO | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | SUSPENSO | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | SUSPENSO | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | SUSPENSO | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | SUSPENSO | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | SUSPENSO | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | SUSPENSO | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | SUSPENSO | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | SUSPENSO | 11 | 0x000001EF6BD72160 |
Observe que cada uma das 16 tarefas filho tem um thread de trabalho diferente atribuído (visto na coluna worker_address), mas todos os trabalhadores são atribuídos ao mesmo pool de oito agendadores (0,5,6,7,8,9,10,11) e que a tarefa pai é atribuída a um agendador fora desse pool (3).
Importante
Quando o primeiro conjunto de tarefas paralelas em uma determinada ramificação for agendado, o Mecanismo de Banco de Dados usará esse mesmo pool de agendadores para quaisquer tarefas adicionais em outras ramificações. Isso significa que o mesmo conjunto de agendadores será usado para todas as tarefas paralelas em todo o plano de execução, limitado apenas pelo MaxDOP.
O Mecanismo de Banco de Dados do SQL Server sempre tentará atribuir agendadores do mesmo nó NUMA para execução de tarefas e atribuí-los sequencialmente (de forma round-robin) se os agendadores estiverem disponíveis. No entanto, o thread de trabalho atribuído à tarefa pai pode ser colocado em um nó NUMA diferente de outras tarefas.
Um thread de trabalho só pode permanecer ativo no agendador durante seu quantum (4 ms) e deve produzir seu agendador depois que o quantum tiver decorrido, para que um thread de trabalho atribuído a outra tarefa possa se tornar ativo. Quando o quantum de um trabalhador expira e não está mais ativo, a respetiva tarefa é colocada numa fila FIFO em estado RUNNABLE, até que se mova para um estado RUNNING novamente, assumindo que a tarefa não requer acesso a recursos que não estão disponíveis no momento, como um trinco ou bloqueio, caso em que a tarefa seria colocada em estado SUSPENSO em vez de RUNNABLE, até que esses recursos estejam disponíveis.
Dica
Para a saída do DMV vista acima, todas as tarefas ativas estão no estado SUSPENSO. Mais detalhes sobre as tarefas de espera estão disponíveis consultando o sys.dm_os_waiting_tasks DMV.
Em resumo, uma solicitação paralela gera várias tarefas. Cada tarefa deve ser atribuída a um único thread de trabalho. Cada thread de trabalho deve ser atribuído a um único agendador. Portanto, o número de agendadores em uso não pode exceder o número de tarefas paralelas por ramificação, que é definido pela configuração MaxDOP ou dica de consulta. O fio de coordenação não contribui para o limite do MaxDOP.
Alocação de threads para CPUs
Por padrão, cada instância do SQL Server inicia cada thread e o sistema operacional distribui threads de instâncias do SQL Server entre os processadores (CPUs) em um computador, com base na carga. Se a afinidade de processo tiver sido habilitada no nível do sistema operacional, o sistema operacional atribuirá cada thread a uma CPU específica. Por outro lado, o Mecanismo de Base de Dados do SQL Server atribui os threads de trabalho do SQL Server a agendadores , que distribuem os threads uniformemente entre as CPUs, de forma circular.
Para realizar multitarefas, por exemplo, quando vários aplicativos acessam o mesmo conjunto de CPUs, o sistema operacional às vezes move threads de trabalho entre CPUs diferentes. Embora eficiente do ponto de vista do sistema operacional, essa atividade pode reduzir o desempenho do SQL Server sob cargas pesadas do sistema, pois cada cache do processador é repetidamente recarregado com dados. A atribuição de CPUs a threads específicos pode melhorar o desempenho nessas condições, eliminando recargas de processadores e reduzindo a migração de threads entre CPUs (reduzindo assim a comutação de contexto); Essa associação entre um thread e um processador é chamada de afinidade de processador. Se a afinidade tiver sido ativada, o sistema operacional atribuirá cada thread a uma CPU específica.
A opção máscara de afinidade é definida utilizando ALTER SERVER CONFIGURATION. Quando a máscara de afinidade não está definida, a instância do SQL Server aloca threads de trabalho uniformemente entre os agendadores que não foram mascarados.
Atenção
Não configure a afinidade da CPU no sistema operacional, bem como a máscara de afinidade no SQL Server. Essas configurações estão tentando obter o mesmo resultado e, se as configurações forem inconsistentes, você pode ter resultados imprevisíveis. Para obter mais informações, consulte a opção máscara de afinidade.
O pool de threads ajuda a otimizar o desempenho quando um grande número de clientes está conectado ao servidor. Normalmente, um thread de sistema operacional separado é criado para cada solicitação de consulta. No entanto, com centenas de conexões com o servidor, o uso de um thread por solicitação de consulta pode consumir grandes quantidades de recursos do sistema. A opção max worker threads permite que o SQL Server crie um pool de threads de trabalho para atender a um número maior de solicitações de consulta, o que melhora o desempenho.
Utilização da opção de pooling leve
A sobrecarga envolvida na troca de contextos de thread pode não ser muito grande. A maioria das instâncias do SQL Server não vê diferenças de desempenho entre definir a opção de pool leve como 0 ou 1. As únicas instâncias do SQL Server que podem beneficiar de pooling leve são aquelas executadas num computador com as seguintes características:
- Um grande servidor multi-CPU
- Todas as CPUs estão funcionando perto da capacidade máxima
- Há um alto nível de mudança de contexto
Esses sistemas podem ver um pequeno aumento no desempenho se o valor de pooling leve for definido como 1.
Importante
Não use o modo de agendamento de fibra durante operações de rotina. Isso pode diminuir o desempenho inibindo os benefícios regulares da troca de contexto e porque alguns componentes do SQL Server não podem funcionar corretamente no modo de fibra. Para obter mais informações, consulte pooling leve.
Execução de roscas e fibras
O Microsoft Windows usa um sistema de prioridade numérica que varia de 1 a 31 para agendar threads para execução. Zero é reservado para uso do sistema operacional. Quando vários threads estão aguardando para serem executados, o Windows despacha o thread com a prioridade mais alta.
Por padrão, cada instância do SQL Server é uma prioridade de 7, que é chamada de prioridade normal. Esse padrão dá aos threads do SQL Server uma prioridade alta o suficiente para obter recursos de CPU suficientes sem afetar negativamente outros aplicativos.
Importante
Esse recurso será removido em uma versão futura do SQL Server. Evite usar esse recurso em novos trabalhos de desenvolvimento e planeje modificar aplicativos que atualmente usam esse recurso.
A opção de configuração de aumento de prioridade pode ser usada para aumentar a prioridade dos threads de uma instância do SQL Server para 13. Isto é referido como alta prioridade. Essa configuração dá aos threads do SQL Server uma prioridade mais alta do que a maioria dos outros aplicativos. Assim, os threads do SQL Server geralmente serão despachados sempre que estiverem prontos para serem executados e não forem antecipados por threads de outros aplicativos. Isso pode melhorar o desempenho quando um servidor está executando apenas instâncias do SQL Server e nenhum outro aplicativo. No entanto, se ocorrer uma operação com uso intensivo de memória no SQL Server, é provável que outros aplicativos não tenham uma prioridade alta o suficiente para antecipar o thread do SQL Server.
Se você estiver executando várias instâncias do SQL Server em um computador e ativar o aumento de prioridade para apenas algumas das instâncias, o desempenho de todas as instâncias em execução com prioridade normal poderá ser afetado negativamente. Além disso, o desempenho de outros aplicativos e componentes no servidor pode diminuir se o aumento de prioridade estiver ativado. Por conseguinte, só deve ser utilizado em condições rigorosamente controladas.
Adicionar CPU a quente
Hot add CPU é a capacidade de adicionar dinamicamente CPUs a um sistema em execução. A adição de CPUs pode ocorrer fisicamente adicionando novo hardware, logicamente por particionamento de hardware online ou virtualmente por meio de uma camada de virtualização. O SQL Server oferece suporte à adição dinâmica de CPU.
Requisitos para adicionar CPU a quente:
- Requer que o hardware suporte a adição a quente de CPU.
- Requer uma versão suportada do Windows Server Datacenter ou Enterprise edition. A partir do Windows Server 2012, o hot add é suportado na edição Standard.
- Requer o SQL Server Enterprise Edition.
- O SQL Server não pode ser configurado para usar o NUMA flexível. Para obter mais informações sobre o soft NUMA, consulte Soft-NUMA (SQL Server).
O SQL Server não usa CPUs automaticamente depois que elas são adicionadas. Isso impede que o SQL Server use CPUs que podem ser adicionadas para alguma outra finalidade. Depois de adicionar CPUs, execute a instrução RECONFIGURE, para que o SQL Server reconheça as novas CPUs como recursos disponíveis.
Observação
Se a máscara affinity64 estiver configurada, a máscara affinity64 deverá ser modificada para usar as novas CPUs.
Práticas recomendadas para executar o SQL Server em computadores com mais de 64 CPUs
Atribuição de threads de hardware a CPUs
Não use as opções de configuração de servidor de máscara de afinidade e máscara de afinidade64 para vincular processadores a threads específicos. Essas opções são limitadas a 64 CPUs. Em vez disso, use a opção SET PROCESS AFFINITY do ALTER SERVER CONFIGURATION.
Gerenciamento do tamanho do arquivo de log de transações
Não confie no crescimento automático para aumentar o tamanho do arquivo de log de transações. Aumentar o log de transações deve ser um processo serial. A extensão do log pode impedir que as operações de gravação de transações prossigam até que a extensão do log seja concluída. Em vez disso, pré-aloque espaço para os arquivos de log definindo o tamanho do arquivo para um valor grande o suficiente para suportar a carga de trabalho típica no ambiente.
Definir o grau máximo de paralelismo para operações de índice
O desempenho de operações de índice, como a criação ou reconstrução de índices, pode ser melhorado em computadores com muitas CPUs, ao definir temporariamente o modelo de recuperação do banco de dados como um modelo de recuperação em massa ou simples. Essas operações de índice podem gerar atividade de log significativa e a contenção de log pode afetar a escolha de melhor grau de paralelismo (DOP) feita pelo SQL Server.
Além de ajustar o grau máximo de paralelismo (MAXDOP) opção de configuração do servidor, considere ajustar o paralelismo para operações de índice usando a opção MAXDOP. Para obter mais informações, consulte Configurar operações de índice paralelo. Para mais informações e diretrizes sobre como ajustar a opção de configuração do servidor para o grau máximo de paralelismo, consulte Configurar a opção de configuração do servidor para o grau máximo de paralelismo.
Opção de número máximo de threads de trabalho
O SQL Server configura dinamicamente os threads de trabalho max opção de configuração do servidor na inicialização. O SQL Server usa o número de CPUs disponíveis e a arquitetura do sistema para determinar essa configuração de servidor durante a inicialização, usando uma fórmula de documentada.
Essa opção é uma opção avançada e deve ser alterada apenas por um administrador de banco de dados experiente ou profissional certificado do SQL Server. Se você suspeitar que há um problema de desempenho, provavelmente não é a disponibilidade de threads de trabalho. É mais provável que a causa seja algo como entrada/saída que faz com que os threads de trabalho esperem. É melhor encontrar a causa raiz de um problema de desempenho antes de alterar a configuração max worker threads. No entanto, se você precisar definir manualmente o número máximo de threads de trabalho, esse valor de configuração sempre deverá ser definido como um valor de pelo menos sete vezes o número de CPUs presentes no sistema. Para obter mais informações, consulte Configurar o limite máximo de threads de trabalho.
Evite o uso do Rastreamento do SQL e do SQL Server Profiler
Recomendamos que você não use o Rastreamento SQL e o SQL Profiler em um ambiente de produção. A sobrecarga para executar essas ferramentas também aumenta à medida que o número de CPUs aumenta. Se você precisar usar o Rastreamento SQL em um ambiente de produção, limite o número de eventos de rastreamento ao mínimo. Crie cuidadosamente o perfil e teste cada evento de rastreamento sob carga e evite usar combinações de eventos que afetem significativamente o desempenho.
Importante
O Rastreamento do SQL e o SQL Server Profiler estão obsoletos. O namespace Microsoft.SqlServer.Management.Trace que contém os objetos Trace e Replay do SQL Server está também descontinuado.
Esse recurso será removido em uma versão futura do SQL Server. Evite usar esse recurso em novos trabalhos de desenvolvimento e planeje modificar aplicativos que atualmente usam esse recurso.
Em vez disso, use Eventos Estendidos. Para obter mais informações sobre Extended Events, consulte Quick Start: Extended events in SQL Server and SSMS XEvent Profiler.
Observação
O SQL Server Profiler para cargas de trabalho do Analysis Services NÃO foi preterido e continuará a ter suporte.
Definir o número de ficheiros de dados tempdb
O número de arquivos depende do número de processadores (lógicos) na máquina. Como regra geral, se o número de processadores lógicos for menor ou igual a oito, use o mesmo número de arquivos de dados que os processadores lógicos. Se o número de processadores lógicos for maior que oito, use oito arquivos de dados e, se a contenção continuar, aumente o número de arquivos de dados em múltiplos de 4 até que a contenção seja reduzida a níveis aceitáveis ou faça alterações na carga de trabalho/código. Lembre-se também de outras recomendações para tempdb, disponíveis em Otimizar o desempenho do tempdb no SQL Server.
No entanto, considerando cuidadosamente as necessidades de simultaneidade do tempdb, você pode reduzir a sobrecarga de gerenciamento de banco de dados. Por exemplo, se um sistema tem 64 CPUs e geralmente apenas 32 consultas usam tempdb, aumentar o número de arquivos tempdb para 64 não melhorará o desempenho.
Componentes do SQL Server que podem usar mais de 64 CPUs
A tabela a seguir lista os componentes do SQL Server e indica se eles podem usar mais de 64 CPUs.
| Nome do processo | Programa executável | Use mais de 64 CPUs |
|---|---|---|
| Mecanismo de Banco de Dados do SQL Server | Sqlserver.exe | Sim |
| Serviços de Relatório | Rs.exe | Não |
| Serviços de análise | As.exe | Não |
| Serviços de integração | Is.exe | Não |
| Agente de Serviços | Sb.exe | Não |
| Full-Text Pesquisa | Fts.exe | Não |
| Agente do SQL Server | Sqlagent.exe | Não |
| SQL Server Management Studio | Ssms.exe | Não |
| Instalação do SQL Server | Setup.exe | Não |