Configurar o cluster de FCI (instância de cluster de failover) RHEL do SQL Server
Aplica-se a: ![]() SQL Server - Linux
SQL Server - Linux
Este guia fornece instruções para criar um cluster de failover de disco compartilhado de dois nós para o SQL Server no Red Hat Enterprise Linux. A camada de clustering baseia-se no complemento de HA do RHEL (Red Hat Enterprise Linux) criado com base no Pacemaker. A Instância do SQL Server está ativa em um nó ou no outro.
Observação
O acesso ao complemento de HA do Red Hat e à documentação exige uma assinatura.
Como mostra o diagrama a seguir, o armazenamento é apresentado a dois servidores. Os componentes de clustering – Corosync e Pacemaker – coordenam a comunicação e o gerenciamento de recursos. Um dos servidores tem a conexão ativa com os recursos de armazenamento e o SQL Server. Quando o Pacemaker detecta uma falha, os componentes de clustering ficam responsáveis pela a movimentação dos recursos para o outro nó.
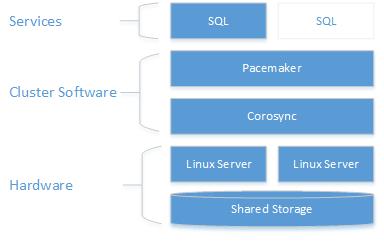
Para saber mais sobre configuração de cluster, opções de agentes de recursos e gerenciamento, acesse a Documentação de referência do RHEL.
Observação
Neste ponto, a integração do SQL Server com o Pacemaker não está tão acoplada quanto a do WSFC em Windows. No SQL Server, não há nenhum conhecimento sobre a presença do cluster, toda a orquestração ocorre de fora para dentro e o serviço é controlado como uma instância autônoma pelo Pacemaker. Também como exemplo, cluster dmvs sys.dm_os_cluster_nodes e sys.dm_os_cluster_properties não apresentarão registros.
Para usar uma cadeia de conexão que aponta para um nome do servidor de cadeia de caracteres e não usar o IP, elas precisarão se registrar no servidor DNS o IP usado para criar o recurso de IP virtual (conforme explicado nas seções a seguir) com o nome do servidor escolhido.
As seções a seguir descrevem as etapas necessárias para configurar uma solução de cluster de failover.
Pré-requisitos
Para concluir o cenário de ponta a ponta a seguir, você precisará de dois computadores para implantar o cluster de dois nós e outro servidor para configurar o servidor NFS. As etapas a seguir descrevem como esses servidores serão configurados.
Instalar e configurar o sistema operacional em cada nó de cluster
A primeira etapa é configurar o sistema operacional nos nós de cluster. Para esse passo a passo, use o RHEL com uma assinatura válida para o complemento de HA.
Instalar e configurar o SQL Server em cada nó de cluster
Instalar e configurar o SQL Server em ambos os nós. Para obter instruções detalhadas, confira Instalar o SQL Server em Linux.
Designe um nó como primário e o outro como secundário para fins de configuração. Use esses termos para seguir este guia.
No nó secundário, interrompa e desabilite o SQL Server.
O seguinte exemplo interrompe e desabilita o SQL Server:
sudo systemctl stop mssql-server sudo systemctl disable mssql-server
Observação
No momento da instalação, uma Chave Mestra do Servidor é gerada para a Instância do SQL Server e colocada em /var/opt/mssql/secrets/machine-key. No Linux, o SQL Server sempre é executado como uma conta local chamada mssql. Como é uma conta local, a identidade dela não é compartilhada entre os nós. Portanto, você precisa copiar a chave de criptografia do nó primário para cada nó secundário, de modo que cada conta mssql local possa acessá-la para descriptografar a Chave Mestra do Servidor.
No nó primário, crie um logon do SQL Server para o Pacemaker e conceda a permissão de logon para executar
sp_server_diagnostics. O Pacemaker usa essa conta para verificar qual nó está executando o SQL Server.sudo systemctl start mssql-serverConecte-se ao banco de dados
masterdo SQL Server com a conta SA e execute o seguinte:USE [master] GO CREATE LOGIN [<loginName>] with PASSWORD= N'<loginPassword>' ALTER SERVER ROLE [sysadmin] ADD MEMBER [<loginName>]Alternativamente, você pode definir as permissões em um nível mais granular. O logon do Pacemaker exige que
VIEW SERVER STATEconsulte o status de integridade comsp_server_diagnostics,setupadmineALTER ANY LINKED SERVERpara atualizar o nome da instância de FCI com o nome do recurso executandosp_dropserveresp_addserver.No nó primário, interrompa e desabilite o SQL Server.
Configure o arquivo de hosts para cada nó de cluster. O arquivo de host precisa incluir o endereço IP e o nome de cada nó de cluster.
Verifique o endereço IP de cada nó. O script a seguir mostra o endereço IP do nó atual.
sudo ip addr showDefina o nome do computador em cada nó. Dê a cada nó um nome exclusivo que tenha 15 caracteres ou menos. Defina o nome do computador adicionando-o a
/etc/hosts. O script a seguir permite que você edite/etc/hostscomvi.sudo vi /etc/hostsO exemplo a seguir mostra
/etc/hostscom adições para dois nós chamadossqlfcivm1esqlfcivm2.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 sqlfcivm1 10.128.16.77 sqlfcivm2
Na próxima seção, você configurará o armazenamento compartilhado e moverá os arquivos de banco de dados para esse armazenamento.
Configurar o armazenamento compartilhado e mover arquivos de banco de dados
Há várias de soluções para fornecer armazenamento compartilhado. Este passo a passo demonstra como configurar o armazenamento compartilhado com o NFS. Recomendamos seguir as melhores práticas e usar o Kerberos para proteger o NFS (encontre um exemplo aqui: https://www.certdepot.net/rhel7-use-kerberos-control-access-nfs-network-shares/).
Aviso
Se você não proteger o NFS, qualquer pessoa que possa acessar sua rede e falsificar o endereço IP de um nó SQL poderá acessar seus arquivos de dados. Como sempre, verifique se você tem o modelo de risco do sistema antes de usá-lo em produção. Outra opção de armazenamento é usar o compartilhamento de arquivo SMB.
Configurar o armazenamento compartilhado com o NFS
Importante
Não há suporte para a hospedagem de arquivos de banco de dados em um servidor NFS com a versão <4 nesta versão. Isso inclui o uso do NFS para o clustering de failover de disco compartilhado, bem como bancos de dados em instâncias não clusterizadas. Estamos trabalhando para habilitar outras versões do servidor NFS nas versões futuras.
Execute as seguintes etapas no servidor NFS:
Instalar
nfs-utilssudo yum -y install nfs-utilsHabilite e inicie o
rpcbindsudo systemctl enable rpcbind && sudo systemctl start rpcbindHabilite e inicie o
nfs-serversudo systemctl enable nfs-server && sudo systemctl start nfs-serverEdite
/etc/exportspara exportar o diretório que você deseja compartilhar. Você precisa de uma linha para cada compartilhamento desejado. Por exemplo:/mnt/nfs 10.8.8.0/24(rw,sync,no_subtree_check,no_root_squash)Exportar os compartilhamentos
sudo exportfs -ravVerifique se os caminhos são compartilhados/exportados e execute-os por meio do servidor NFS
sudo showmount -eAdicionar uma exceção no SELinux
sudo setsebool -P nfs_export_all_rw 1Abra o firewall do servidor.
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload
Configurar todos os nós de cluster para se conectar ao armazenamento compartilhado do NFS
Execute as etapas a seguir em todos os nós de cluster.
Instalar
nfs-utilssudo yum -y install nfs-utilsAbra o firewall em clientes e no servidor NFS
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadVerifique se você pode ver os compartilhamentos NFS nos computadores cliente
sudo showmount -e <IP OF NFS SERVER>Repita essas etapas em todos os nós de cluster.
Para obter mais informações sobre como usar o NFS, confira os seguintes recursos:
- Servidores NFS e firewall | Stack Exchange
- Como montar um volume do NFS | Guia de Administradores de Rede do Linux
- Configuração do servidor NFS | Portal do Cliente do Red Hat
Montar o diretório de arquivos de banco de dados para que ele aponte para o armazenamento compartilhado
Somente no nó primário, salve os arquivos de banco de dados em uma localização temporária. O script a seguir, cria um diretório temporário, copia os arquivos de banco de dados para o novo diretório e remove os arquivos de banco de dados antigos. Enquanto o SQL Server é executado como o usuário local
mssql, você precisa verificar se, após a transferência de dados para o compartilhamento montado, o usuário local tem acesso de leitura/gravação ao compartilhamento.sudo su mssql mkdir /var/opt/mssql/tmp cp /var/opt/mssql/data/* /var/opt/mssql/tmp rm /var/opt/mssql/data/* exitEm todos os nós de cluster, edite o arquivo
/etc/fstabpara incluir o comando mount.<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrO script a seguir mostra um exemplo da edição.
10.8.8.0:/mnt/nfs /var/opt/mssql/data nfs timeo=14,intr
Observação
Se estiver usando um recurso do sistema de arquivos (FS), conforme recomendado aqui, não haverá necessidade de preservar o comando de montagem em /etc/fstab. O Pacemaker se encarregará de montar a pasta quando ele iniciar o recurso clusterizado do FS. Com a ajuda do isolamento, ele garantirá que o FS nunca seja montado duas vezes.
Execute o comando
mount -apara o sistema atualizar os caminhos montados.Copie o banco de dados e os arquivos de log que você salvou em
/var/opt/mssql/tmppara o compartilhamento recém-montado/var/opt/mssql/data. Essa etapa só precisa ser realizada no nó primário. Conceda permissões de leitura/gravação ao usuário localmssql.sudo chown mssql /var/opt/mssql/data sudo chgrp mssql /var/opt/mssql/data sudo su mssql cp /var/opt/mssql/tmp/* /var/opt/mssql/data/ rm /var/opt/mssql/tmp/* exitVerifique se o SQL Server é iniciado com êxito com o novo caminho de arquivo. Faça isso em cada nó. Neste ponto, apenas um nó deve executar o SQL Server por vez. Eles não podem ser executados ao mesmo tempo, porque tentarão acessar os arquivos de dados simultaneamente (para evitar a inicialização acidental do SQL Server em ambos os nós, use um recurso de cluster do sistema de arquivos para garantir que o compartilhamento não seja montado duas vezes por nós diferentes). Os comandos a seguir iniciam o SQL Server, verificam o status e, em seguida, interrompem o SQL Server.
sudo systemctl start mssql-server sudo systemctl status mssql-server sudo systemctl stop mssql-server
Nesse ponto, ambas as instâncias do SQL Server são configuradas para serem executadas com os arquivos de banco de dados no armazenamento compartilhado. A próxima etapa é configurar o SQL Server para o Pacemaker.
Instalar e configurar o Pacemaker em cada nó de cluster
Em ambos os nós de cluster, crie um arquivo para armazenar o nome de usuário do SQL Server e a senha para o logon do Pacemaker. O comando a seguir cria e popula este arquivo:
sudo touch /var/opt/mssql/secrets/passwd echo '<loginName>' | sudo tee -a /var/opt/mssql/secrets/passwd echo '<loginPassword>' | sudo tee -a /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 600 /var/opt/mssql/secrets/passwdEm ambos os nós de cluster, abra as portas de firewall do Pacemaker. Para abrir essas portas com o
firewalld, execute o seguinte comando:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSe você estiver usando outro firewall que não tenha uma configuração de alta disponibilidade interna, as portas a seguir precisarão ser abertas para que o Pacemaker possa se comunicar com outros nós no cluster:
- TCP: portas 2224, 3121 e 21064
- UDP: porta 5405
Instale os pacotes do Pacemaker em cada nó.
sudo yum install pacemaker pcs fence-agents-all resource-agentsDefina a senha do usuário padrão criado ao instalar pacotes do Pacemaker e do Corosync. Use a mesma senha em ambos os nós.
sudo passwd haclusterHabilite e inicie o serviço
pcsde o Pacemaker. Isso permitirá que os nós reingressem no cluster após a reinicialização. Execute o comando a seguir em ambos os nós.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstalar o agente do recurso FCI para SQL Server. Execute os comandos a seguir em ambos os nós.
sudo yum install mssql-server-ha
Configurar um agente de isolamento
Um dispositivo STONITH fornece um agente de isolamento. Como configurar o Pacemaker no Red Hat Enterprise Linux no Azure fornece um exemplo de como criar um dispositivo STONITH para esse cluster no Azure. Modifique as instruções de seu ambiente.
Criar o cluster
Em um dos nós, crie o cluster.
sudo pcs cluster auth <nodeName1 nodeName2 ...> -u hacluster sudo pcs cluster setup --name <clusterName> <nodeName1 nodeName2 ...> sudo pcs cluster start --allConfigure os recursos de cluster para o SQL Server, o sistema de arquivos e os recursos de IP virtual e envie a configuração por push para o cluster. Você precisará das seguintes informações:
- Nome de recurso do SQL Server: um nome para o recurso clusterizado do SQL Server.
- Nome de recurso do IP flutuante: um nome para o recurso de endereço IP virtual.
- Endereço IP: o endereço IP que os clientes usam para se conectarem à instância clusterizada do SQL Server.
- Nome do recurso de sistema de arquivos: um nome para o recurso de sistema de arquivos.
- device: o caminho do compartilhamento NFS
- device: o caminho local que está montado no compartilhamento
- fstype: tipo de compartilhamento de arquivo (ou seja,
nfs)
Atualize os valores com base no script a seguir para o seu ambiente. Faça a execução em um nó para configurar e iniciar o serviço clusterizado.
sudo pcs cluster cib cfg sudo pcs -f cfg resource create <sqlServerResourceName> ocf:mssql:fci sudo pcs -f cfg resource create <floatingIPResourceName> ocf:heartbeat:IPaddr2 ip=<ip Address> sudo pcs -f cfg resource create <fileShareResourceName> Filesystem device=<networkPath> directory=<localPath> fstype=<fileShareType> sudo pcs -f cfg constraint colocation add <virtualIPResourceName> <sqlResourceName> sudo pcs -f cfg constraint colocation add <fileShareResourceName> <sqlResourceName> sudo pcs cluster cib-push cfgPor exemplo, o script a seguir cria um recurso clusterizado do SQL Server chamado
mssqlhae um recurso de IP flutuante com o endereço IP10.0.0.99. Ele também cria um recurso do sistema de arquivos e adiciona restrições para que todos os recursos sejam colocados no mesmo nó do recurso do SQL.sudo pcs cluster cib cfg sudo pcs -f cfg resource create mssqlha ocf:mssql:fci sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.0.0.99 sudo pcs -f cfg resource create fs Filesystem device="10.8.8.0:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs" sudo pcs -f cfg constraint colocation add virtualip mssqlha sudo pcs -f cfg constraint colocation add fs mssqlha sudo pcs cluster cib-push cfgDepois que a configuração for enviada por push, o SQL Server será iniciado em um nó.
Verifique se o SQL Server foi iniciado.
sudo pcs statusO exemplo a seguir mostra os resultados de quando o Pacemaker iniciou com êxito uma instância clusterizada do SQL Server.
fs (ocf::heartbeat:Filesystem): Started sqlfcivm1 virtualip (ocf::heartbeat:IPaddr2): Started sqlfcivm1 mssqlha (ocf::mssql:fci): Started sqlfcivm1 PCSD Status: sqlfcivm1: Online sqlfcivm2: Online Daemon Status: corosync: active/disabled pacemaker: active/enabled pcsd: active/enabled