Implantar um cluster de Big Data do SQL Server no modo do Active Directory Domain Services
Este artigo descreve como implantar um cluster de Big Data do SQL Server no modo do Active Directory. As etapas deste artigo exigem acesso a um domínio do Active Directory. Antes de prosseguir, você precisará concluir os requisitos explicados em Implantar Clusters de Big Data do SQL Server no modo do Active Directory.
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Preparar a implantação
Para a implantação de um cluster de Big Data com a integração com o AD, algumas informações adicionais precisam ser fornecidas para a criação de objetos relacionados aos clusters de Big Data no AD.
Usando o perfil kubeadm-prod (ou openshift-prod da versão CU5 em diante), você terá automaticamente os espaços reservados para as informações relacionadas à segurança e ao ponto de extremidade que são necessárias para a integração ao AD.
Além disso, você precisa fornecer credenciais que os Clusters de Big Data usarão para criar os objetos necessários no AD. Essas credenciais são fornecidas como variáveis de ambiente.
Tráfego e portas
Verifique se os firewalls ou aplicativos de terceiros permitem as portas necessárias para a comunicação com o Active Directory.
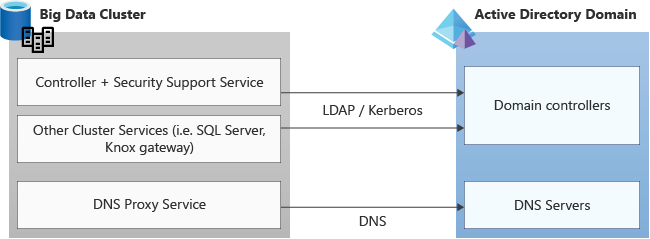
As solicitações são feitas nesses protocolos dos serviços de cluster Kubernetes para o domínio do Active Directory e vice-versa, portanto, devem ter permissão de entrada e saída em qualquer firewall ou aplicativo de terceiros que escuta as portas necessárias para TCP e UDP. Os números de porta padrão que o Active Directory usa:
| Serviço | Porta |
|---|---|
| DNS | 53 |
| LDAP LDAPS |
389 636 |
| Kerberos | 88 |
| Protocolo de alteração de senha do Kerberos/AD | 464 |
| Porta do Catálogo Global via LDAP via LDAPS |
3268 3269 |
Definir variáveis de ambiente de segurança
As variáveis de ambiente a seguir fornecem as credenciais para os Clusters de Big Data de serviço de domínio, que serão usados para configurar a integração com o AD. Essa conta também é usada pelos Clusters de Big Data para manter os objetos do AD no futuro.
export DOMAIN_SERVICE_ACCOUNT_USERNAME=<AD principal account name>
export DOMAIN_SERVICE_ACCOUNT_PASSWORD=<AD principal password>
Fornecer parâmetros de segurança e ponto de extremidade
Além das variáveis de ambiente para as credenciais, você também precisa fornecer informações de segurança e de ponto de extremidade para que a integração com o AD funcione. Os parâmetros necessários fazem parte automaticamente do perfil de implantação kubeadm-prod/openshift-prod.
A integração com o AD requer os seguintes parâmetros. Adicione esses parâmetros aos arquivos control.json e bdc.json usando os comandos config replace mostrados mais adiante neste artigo. Todos os exemplos a seguir estão usando o domínio de exemplo contoso.local.
security.activeDirectory.ouDistinguishedName: nome diferenciado de uma UO (unidade organizacional) a que todas as contas do AD criadas pela implantação do cluster serão adicionadas. Se o nome do domínio forcontoso.local, o nome diferenciado da UO seráOU=BDC,DC=contoso,DC=local.security.activeDirectory.dnsIpAddresses: contém a lista de endereços IP de servidores DNS do domínio.security.activeDirectory.domainControllerFullyQualifiedDns: lista de FQDNs do controlador de domínio. O FQDN contém o nome do computador/host do controlador de domínio. Se tiver vários controladores de domínio, você poderá fornecer uma lista aqui. Exemplo:HOSTNAME.CONTOSO.LOCAL.Importante
Quando vários controladores de domínio estão atendendo a um domínio, use o controlador de domínio primário como a primeira entrada na lista
domainControllerFullyQualifiedDnsna configuração de segurança. Para obter o nome do controlador de domínio primário, digitenetdom query fsmono prompt de comando e clique em ENTER.Parâmetro opcional
security.activeDirectory.realm: na maioria dos casos, o realm é igual ao nome de domínio. Para casos em que eles não são iguais, use esse parâmetro para definir o nome do realm (por exemplo,CONTOSO.LOCAL). O valor fornecido para esse parâmetro precisa ser totalmente qualificado.Parâmetro opcional
security.activeDirectory.netbiosDomainName: esse é o nome NETBIOS do domínio do AD. Na maioria dos casos, esse será o primeiro rótulo do nome de domínio do AD. Para casos em que ele difere, use esse parâmetro para definir o nome NETBIOS do domínio. Esse valor não deve conter pontos. Normalmente, esse nome é usado para qualificar as contas de usuário no domínio. Por exemplo, CONTOSO\user, em que CONTOSO é o nome de domínio NETBIOS.Observação
O suporte para uma configuração em que o nome de domínio Active Directory é diferente do nome NETBIOS do domínio Active Directory usando o security.activeDirectory.netbiosDomainName foi habilitado desde a versão CU9 do SQL Server 2019.
security.activeDirectory.domainDnsName: nome do domínio DNS que será usado para o cluster (por exemplo,contoso.local).security.activeDirectory.clusterAdmins: esse parâmetro usa um grupo do AD. O escopo do grupo do AD precisa ser universal ou global. Os membros desse grupo terão a função de clusterbdcAdmin, que fornecerá permissões de administrador no cluster. Isso significa que eles têm permissõessysadminno SQL Server, permissõessuperuserno HDFS e permissões de administrador quando conectados ao ponto de extremidade do controlador.Importante
Crie esse grupo no AD antes do início da implantação. Se o escopo desse grupo do AD for o local do domínio, a implantação falhará.
security.activeDirectory.clusterUsers: lista dos grupos do AD que são usuários comuns (sem permissões de administrador) no cluster de Big Data. A lista pode incluir grupos do AD que têm o escopo definido como grupos universais ou globais. Eles não podem ser grupos locais de domínio.
Os grupos do AD dessa lista são mapeados para a função de cluster de Big Data bdcUser e precisam receber acesso ao SQL Server (confira Permissões do SQL Server) ou ao HDFS (confira Guia de permissões do HDFS). Quando conectados ao ponto de extremidade do controlador, esses usuários só poderão listar os pontos de extremidade disponíveis no cluster usando o comando azdata bdc endpoint list.
Para obter detalhes sobre como atualizar os grupos do AD para essas configurações, confira Gerenciar o acesso ao cluster de Big Data no modo do Active Directory.
Dica
Para habilitar a experiência de navegação HDFS quando conectado ao SQL Server mestre no Azure Data Studio, um usuário com a função bdcUser deve receber permissões de VIEW SERVER STATE, pois o Azure Data Studio usa a DMV sys.dm_cluster_endpoints a fim de obter o ponto de extremidade do gateway Knox necessário para se conectar ao HDFS.
Importante
Crie esses grupos no AD antes do início da implantação. Se o escopo de qualquer um desses grupos do AD for o local do domínio, a implantação falhará.
Importante
Se os usuários de domínio tiverem um grande número de associações a um grupo, você precisará ajustar os valores para a configuração do gateway httpserver.requestHeaderBuffer (o valor padrão é 8192) e a configuração do HDFS hadoop.security.group.mapping.ldap.search.group.hierarchy.levels (o valor padrão é 10) usando o arquivo de configuração de implantação bdc.json personalizado. Essa é uma melhor prática para evitar tempos limite de conexão para respostas de gateway e/ou HTTP com um código de status 431 (Campos de cabeçalho da solicitação muito grandes). Esta é uma seção do arquivo de configuração que mostra como definir os valores dessas configurações e quais são os valores recomendados para um número maior de associações a um grupo:
{
...
"spec": {
"resources": {
...
"gateway": {
"spec": {
"replicas": 1,
"endpoints": [{...}],
"settings": {
"gateway-site.gateway.httpserver.requestHeaderBuffer": "65536"
}
}
},
...
},
"services": {
...
"hdfs": {
"resources": [...],
"settings": {
"core-site.hadoop.security.group.mapping.ldap.search.group.hierarchy.levels": "4"
}
},
...
}
}
}
security.activeDirectory.enableAES Optional parameterParâmetro opcional: valor booliano que indica se AES 128 e AES 256 devem ser habilitados nas contas do AD geradas automaticamente. O valor padrão éfalse. Quando esse parâmetro for definido comotrue, os sinalizadores 'Esta conta dá suporte à criptografia Kerberos AES de 128 bits' e 'Esta conta dá suporte à criptografia Kerberos AES de 256 bits' serão marcados nos objetos do AD gerados automaticamente durante a implantação do cluster de Big Data.
Observação
O parâmetro security.activeDirectory.enableAES está disponível começando com os Clusters de Big Data do SQL Server CU13. Se o cluster de Big Data for uma versão anterior à CU13, as seguintes etapas serão necessárias:
- Execute o comando
azdata bdc rotate -n <your-cluster-name>. Esse comando rotacionará os keytabs no cluster, o que é necessário para garantir que as entradas AES nos keytabs estão corretas. Para obter mais informações, confira azdata bdc. Além disso,azdata bdc rotaterotacionará as senhas dos objetos do AD gerados automaticamente durante a implantação inicial na UO especificada. - Defina os sinalizadores a seguir "Esta conta dá suporte à criptografia Kerberos AES de 128 bits" e "Esta conta dá suporte à criptografia Kerberos AES de 256 bits" de cada objeto AD gerado automaticamente no UO que você forneceu durante a implantação inicial do cluster de Big Data. Isso pode ser feito executando o seguinte script
Get-ADUser -Filter * -SearchBase '<OU Path>' | Set-ADUser -replace @{ 'msDS-SupportedEncryptionTypes' = '24' }do PowerShell no seu controlador de domínio, o qual define os campos AES em cada conta na UO determinada no parâmetro<OU Path>.
Importante
Crie os grupos fornecidos para as configurações abaixo no AD antes do início da implantação. Se o escopo de qualquer um desses grupos do AD for o local do domínio, a implantação falhará.
Parâmetro opcional
security.activeDirectory.appOwners: lista dos grupos do AD que têm permissões para criar, excluir e executar qualquer aplicativo. A lista pode incluir grupos do AD que têm o escopo definido como grupos universais ou globais. Eles não podem ser grupos locais de domínio.Parâmetro opcional
security.activeDirectory.appReaders: lista dos grupos do AD que têm permissões para executar qualquer aplicativo. A lista pode incluir grupos do AD que têm o escopo definido como grupos universais ou globais. Eles não podem ser grupos locais de domínio.
A tabela abaixo mostra o modelo de autorização para o gerenciamento de aplicativo:
| Funções autorizadas | Comando da CLI de Dados do Azure (azdata) |
|---|---|
| appOwner | azdata app create |
| appOwner | azdata app update |
| appOwner, appReader | azdata app list |
| appOwner, appReader | azdata app describe |
| appOwner | azdata app delete |
| appOwner, appReader | azdata app run |
security.activeDirectory.subdomain: Parâmetro opcional Esse parâmetro foi introduzido na versão SQL Server 2019 CU5 para dar suporte à implantação de vários Clusters de Big Data no mesmo domínio. Usando essa configuração, você pode especificar nomes DNS diferentes para cada cluster de Big Data implantado. Se o valor desse parâmetro não for especificado na seção do Active Directory do arquivocontrol.json, por padrão, o nome do cluster de Big Data (o mesmo que o nome do namespace do Kubernetes) será usado para calcular o valor da configuração de subdomínio.Observação
O valor transmitido pela configuração de subdomínio não é um novo domínio do AD, mas apenas um domínio DNS usado pelo cluster de Big Data internamente.
Importante
Você precisará instalar ou atualizar a última versão da CLI de Dados do Azure (
azdata) da versão SQL Server 2019 CU5 em diante para aproveitar essas novas funcionalidades e implantar vários Clusters de Big Data no mesmo domínio.Confira Conceito: implantar Clusters de Big Data do SQL Server no modo do Active Directory para obter mais detalhes sobre a implantação de vários Clusters de Big Data no mesmo domínio do Active Directory.
security.activeDirectory.accountPrefix: Parâmetro opcional Esse parâmetro foi introduzido na versão SQL Server 2019 CU5 para dar suporte à implantação de vários Clusters de Big Data no mesmo domínio. Essa configuração garante a exclusividade dos nomes de contas para vários serviços de Clusters de Big Data, que precisam ser diferentes entre dois clusters. A personalização do nome do prefixo da conta é opcional; por padrão, o nome do subdomínio é usado como o prefixo da conta. Se o nome do subdomínio tiver mais de 12 caracteres, os primeiros 12 caracteres do nome do subdomínio serão usados como o prefixo da conta.Observação
O Active Directory exige que os nomes das contas sejam limitados a 20 caracteres. O cluster de Big Data precisa usar oito dos caracteres para distinguir pods e StatefulSets. Isso deixa 12 caracteres como limite para o prefixo da conta
Verifique o escopo do grupo do AD para determinar se ele é DomainLocal.
Se ainda não tiver inicializado o arquivo de configuração de implantação, você poderá executar esse comando para obter uma cópia da configuração. Os exemplos abaixo usam o perfil kubeadm-prod; o mesmo se aplica a openshift-prod.
azdata bdc config init --source kubeadm-prod --target custom-prod-kubeadm
Para definir os parâmetros acima no arquivo control.json, use os comandos da CLI de dados do Azure (azdata) a seguir. Os comandos substituem a configuração e fornecem seus próprios valores antes da implantação.
Importante
Na versão SQL Server 2019 CU2, a estrutura da seção de configuração de segurança no perfil de implantação mudou de maneira clara e todas as configurações relacionadas ao Active Directory estão no novo activeDirectory na árvore json em security no arquivo control.json.
Observação
Além de fornecer valores diferentes para o subdomínio, conforme descrito nesta seção, você também precisará usar números de porta diferentes para pontos de extremidade dos Clusters de Big Data ao implantar vários clusters de Big Data no mesmo cluster do Kubernetes. Esses números de porta são configuráveis no momento da implantação por meio dos perfis de configuração de implantação.
O exemplo abaixo se baseia no uso do SQL Server 2019 CU2. Ele mostra como substituir os valores de parâmetro relacionados ao AD na configuração de implantação. Os detalhes do domínio a seguir são valores de exemplo.
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.ouDistinguishedName=OU\=bdc\,DC\=contoso\,DC\=local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.dnsIpAddresses=[\"10.100.10.100\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.domainControllerFullyQualifiedDns=[\"HOSTNAME.CONTOSO.LOCAL\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.domainDnsName=contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.clusterAdmins=[\"bdcadminsgroup\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.clusterUsers=[\"bdcusersgroup\"]"
#Example for providing multiple clusterUser groups: [\"bdcusergroup1\",\"bdcusergroup2\"]
Opcionalmente, da versão SQL Server 2019 CU5 em diante, você pode substituir os valores padrão das configurações de subdomain e accountPrefix.
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.subdomain=[\"bdctest\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.accountPrefix=[\"bdctest\"]"
Da mesma forma, em versões anteriores à SQL Server 2019 CU2, você pode executar:
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.ouDistinguishedName=OU\=bdc\,DC\=contoso\,DC\=local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.dnsIpAddresses=[\"10.100.10.100\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.domainControllerFullyQualifiedDns=[\"HOSTNAME.CONTOSO.LOCAL\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.domainDnsName=contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.clusterAdmins=[\"bdcadminsgroup\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.clusterUsers=[\"bdcusersgroup\"]"
#Example for providing multiple clusterUser groups: [\"bdcusergroup1\",\"bdcusergroup2\"]
Além das informações acima, você também precisa fornecer nomes DNS para os diferentes pontos de extremidade do cluster. As entradas DNS que usam os nomes DNS fornecidos por você serão criadas automaticamente no servidor DNS após a implantação. Você usará esses nomes ao se conectar aos diferentes pontos de extremidade do cluster. Por exemplo, se o nome DNS da instância mestra do SQL for mastersql e considerando que o subdomínio usará o valor padrão do nome do cluster em control.json, você usará mastersql.contoso.local,31433 ou mastersql.mssql-cluster.contoso.local,31433 (dependendo dos valores fornecidos nos arquivos de configuração da implantação para os nomes DNS do ponto de extremidade) a fim de se conectar à instância mestra por meio das ferramentas.
# DNS names for Big Data Clusters services
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[0].dnsName=<controller DNS name>.contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[1].dnsName=<monitoring services DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.master.spec.endpoints[0].dnsName=<SQL Master Primary DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.master.spec.endpoints[1].dnsName=<SQL Master Secondary DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.gateway.spec.endpoints[0].dnsName=<Gateway (Knox) DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.appproxy.spec.endpoints[0].dnsName=<app proxy DNS name>.<Domain name. e.g. contoso.local>"
Importante
Você pode usar os nomes DNS do ponto de extremidade de sua escolha, desde que eles sejam totalmente qualificados e não entrem em conflito com os dois Clusters de Big Data implantados no mesmo domínio. Opcionalmente, você pode usar o valor de parâmetro do subdomain para garantir que os nomes DNS sejam diferentes nos clusters. Por exemplo:
# DNS names for Big Data Clusters services
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[0].dnsName=<controller DNS name>.<subdomain e.g. mssql-cluster>.contoso.local"
Você pode encontrar aqui um script de exemplo para implantar um cluster de Big Data do SQL Server no cluster do Kubernetes de nó único (kubeadm) com a integração com o AD.
Observação
Pode haver cenários em que você não poderá acomodar o parâmetro subdomain recém-introduzido. Por exemplo, você precisa implantar uma versão anterior à CU5 e já atualizou a CLI de Dados do Azure (azdata). Isso é muito improvável, mas se você precisar revertê-lo para o comportamento de antes do CU5, defina o parâmetro useSubdomain como false na seção control.json do Active Directory. Este é o comando usado para fazer isso:
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.useSubdomain=false"
Agora, você precisa definir todos os parâmetros necessários para uma implantação dos Clusters de Big Data com a integração do Active Directory.
Agora você pode implantar o cluster de Big Data integrado com Active Directory usando o comando da CLI de Dados do Azure (azdata) e o perfil de implantação kubeadm-prod. Para obter a documentação completa de como implantar Clusters de Big Data, confira Como implantar Clusters de Big Data do SQL Server no Kubernetes.
Verificar a entrada DNS inversa para o controlador de domínio
Verifique se há uma entrada DNS inversa (registro PTR) para o próprio controlador de domínio, registrada no servidor DNS. Para verificar isso, execute nslookup do endereço IP do controlador de domínio para ver se ele pode ser resolvido para o FQDN do controlador de domínio.
Limitações e problemas conhecidos
Limitações a serem consideradas no SQL Server 2019 CU5
atualmente, o Painel de Pesquisa de Logs e o Painel de Métricas não dão suporte à autenticação do AD. O nome de usuário e a senha básicos definidos na implantação podem ser usados para autenticação nesses painéis. Todos os outros pontos de extremidade do cluster dão suporte à autenticação do AD.
No momento, o modo de segurança do AD só funciona em ambientes de implantação do
kubeadme doopenshift, não no AKS nem no ARO. Por padrão, os perfis de implantaçãokubeadm-prodeopenshift-prodincluem as seções de segurança.Antes da versão SQL Server CU5 2019, somente um cluster de Big Data por domínio (Active Directory) era permitido. A habilitação de vários clusters de Big Data por domínio está disponível da versão CU5 em diante.
Nenhum dos grupos do AD especificados nas configurações de segurança pode estar com escopo DomainLocal. Para verificar o escopo de um grupo do AD, siga estas instruções.
As contas do AD que podem ser usadas para fazer logon no cluster de Big Data são permitidas do mesmo domínio que foi configurado para os Clusters de Big Data do SQL Server. Não há suporte para a habilitação de logons em outro domínio confiável.
Próximas etapas
Conectar Clusters de Big Data do SQL Server: Modo do Active Directory
Solucionar problemas de integração do Active Directory ao cluster de Big Data do SQL Server
Conceito: implantar Clusters de Big Data do SQL Server no modo do Active Directory