Crie uma arquitetura e uma estratégia de alta disponibilidade para o SharePoint Server
APLICA-SE A: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint no Microsoft 365
SharePoint no Microsoft 365
Uma estratégia de alta disponibilidade é um requisito importante para um ambiente SharePoint Server de produção. Uma estratégia de ponta a ponta inclui processos operacionais, governança de plataforma, arquitetura e soluções técnicas. Este artigo trata dos aspectos técnicos e de arquitetura da alta disponibilidade. Contém orientações sobre elementos de design específicos do SharePoint e as opções técnicas que determinam a sua estratégia para alta disponibilidade.
Observação
[!OBSERVAçãO] Alta disponibilidade e recuperação de desastres não são a mesma coisa. Embora haja uma sobreposição no planejamento e nas soluções, eles são subconjuntos da continuidade dos negócios. O propósito da alta disponibilidade é oferecer resiliência dentro do data center primário e tempo de inatividade planejado. O propósito da recuperação de desastre é permitir que uma organização continue as operações de computador em um data center secundário quando um desastre no data center primário impede o uso dessa infraestrutura. Para informações sobre recuperação de desastre para SharePoint Server, veja Escolher uma estratégia de recuperação de desastre para o SharePoint Server.
A alta disponibilidade é usada em geral para descrever a capacidade de um sistema de continuar operando e de fornecer recursos a seus usuários quando uma falha ocorre em uma ou mais das seguintes categorias em um domínio de falha: hardware, software ou aplicativo. O nível de disponibilidade é expresso como uma medida da porcentagem do tempo em que um sistema está operacional de forma continua para permitir funções de negócios. O nível de disponibilidade necessário depende da organização. Embora esse requisito também possa variar entre unidades de negócios, um contrato de nível de serviço vale para toda a organização. Do ponto de vista dos utilizadores, um farm do SharePoint está disponível quando os utilizadores podem aceder ao farm e utilizar as funcionalidades e serviços que têm de fazer o seu trabalho.
Um farm do SharePoint com alta disponibilidade possui os seguintes objetivos e características:
O design do farm reduz pontos de falha em potencial. Como é improvável que você consiga eliminar todos os pontos de falha, a estratégia geral deve incluir a maneira de responder a uma falha.
Eventos de failover são imperceptíveis e não afetam as atividades do usuário.
O farm continua operando com menor capacidade em vez de parar de funcionar completamente.
O farm é resiliente. Os incidentes que afetam o serviço ocorrem com pouca frequência, e ações efetivas são tomadas em tempo hábil quando eles ocorrem.
Introdução
Antes de poder criar uma arquitetura e estratégia de elevada disponibilidade realista e económica para o seu ambiente do SharePoint, tem de definir e quantificar os seus objetivos de disponibilidade. Estes objetivos refletem até que ponto a sua organização depende do SharePoint Server e como uma perda de serviço pode afetar as operações da organização. O efeito da perda de serviço depende da natureza da perda (total ou parcial) e da duração da perda.
Uma estratégia de alta disponibilidade de sucesso deve refletir as necessidades específicas da organização. Também deve proporcionar um equilíbrio ideal entre requisitos de negócios, contratos de nível de serviço de TI e a disponibilidade de soluções técnicas, recursos de suporte de TI e custos de infraestrutura.
Depois de identificar os requisitos de disponibilidade da organização, você pode começar a criar um design e uma estratégia de alta disponibilidade para reduzir o risco de tempo de inatividade e redução de operações. Profissionais de TI que projetam e implementam sistemas de alta disponibilidade usam as seguintes diretrizes para atingir seus objetivos:
Eliminar pontos de falha únicos para cada domínio de falha no sistema inteiro, em cada camada possível (sistema operacional, software e o aplicativo SharePoint).
Implementar detecção, isolamento e resolução de falhas muito rápidos.
As soluções de alta disponibilidade têm escopo amplo e oferecem um conjunto de recursos compartilhados em todo o sistema, integrados para fornecer serviços exigidos predefinidos. A solução usa diferentes combinações de hardware e software para minimizar o tempo de inatividade e restaurar serviços quando o sistema ou parte dele falha.
Uma solução tolerante a falhas é focada no hardware e usa hardware especializado para detectar falhas e imediatamente passar para um componente redundante. Esse componente pode ser um processador, placa de memória, fonte de alimentação, subsistema de E/S ou subsistema de armazenamento. A troca para um componente redundante proporciona um alto nível de serviço.
Uma análise de custo-benefício das soluções de tolerância a falhas e alta disponibilidade permite que as organizações criem uma estratégia eficaz para atingir as metas de disponibilidade de seu farm do SharePoint. Geralmente há compensações de custo entre as duas soluções.
Um processo que implementa a alta disponibilidade é um dos mais caros investimentos para um farm do SharePoint. Conforme o nível de disponibilidade e o número de sistemas que você deseja tornar altamente disponíveis aumenta, a complexidade e o custo de uma solução de disponibilidade também aumentam.
Os avanços na tecnologia de virtualização permitem que as organizações usem computadores virtuais como reservas quentes, mornas ou frias. Computadores virtuais podem ser adequados para oferecer a mesma funcionalidade. A virtualização pode trazer flexibilidade e eficiência de custo. Mas você precisa verificar se uma máquina virtual tem a capacidade para lidar com a carga do computador físico que ela irá substituir.
Criar uma arquitetura de farm que permite alta disponibilidade
As ilustrações abaixo mostram como você pode distribuir e configurar diferentes partes de um ambiente do SharePoint para aumentar a disponibilidade em um farm. Esse exemplo também mostra como a redundância pode lidar com domínios de falha.
Observação
[!OBSERVAçãO] Nosso exemplo não é abrangente. Por exemplo, ele não mostra todos os domínios de falha nem hardware tolerante a falhas.
Exemplos de redundância em uma topologia de farm para lidar com pontos de falha
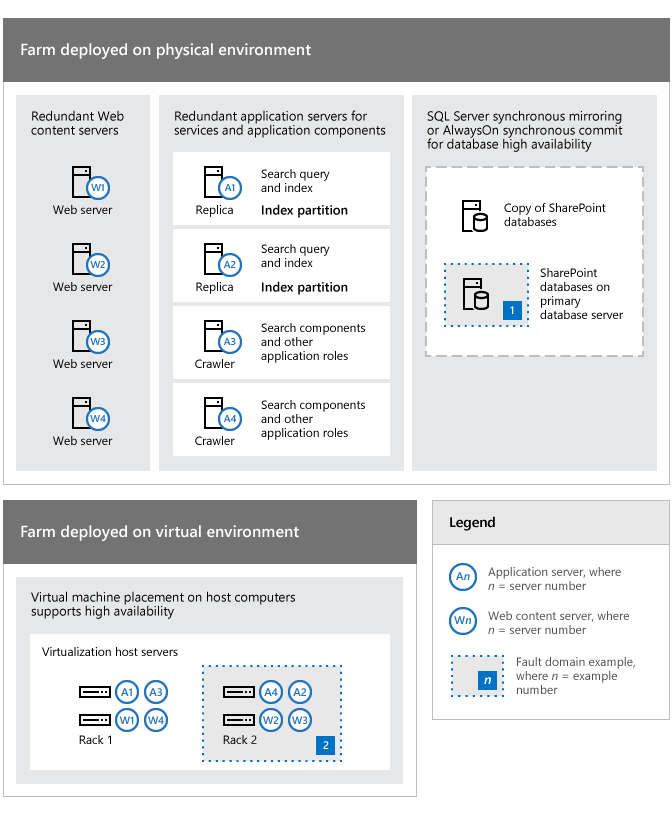
Observe os seguintes pontos na topologia na ilustração anterior:
Os servidores de farm desse exemplo podem ser computadores físicos ou máquinas virtuais implementadas em servidores Hyper-V host. O princípio de identificar e responder a pontos de falha se aplica a ambos os tipos de ambiente.
Quatro servidores (W1-W4) são dedicados a servir conteúdo, e essa redundância aumenta a disponibilidade se uma falha ocorre em um ou mais servidores. Esse nível de redundância também permite que o farm continue a operar quando você aplica atualizações de software.
Quatro servidores de aplicativos (A1-A4) aumentam a disponibilidade dos serviços de farm e componentes de aplicativos específicos, como pesquisa. Funções de pesquisa e componentes são redundantes.
Os servidores de banco de dados do farm são redundantes, a alta disponibilidade do banco de dados pode ser atingida com o uso de espelhamento ou clustering.
Em um ambiente virtual, as máquinas virtuais são colocadas em servidores Hyper-V host separados para eliminar um único ponto de falha. Essa abordagem para a organização de máquinas virtuais segue as orientações de melhores práticas para disponibilidade e desempenho.
O servidor principal de banco de dados (identificado como 1) e rack 2 (identificado como 2), que contém dois dos computadores host de virtualização, são identificados como domínios de falha para mostrar como você pode ver o farm e a infraestrutura como uma coleção de domínios de falha. Isso mostra como você pode fazer uma análise profunda do ambiente para desenvolver uma estratégia geral e análise de custo/benefício.
Outros serviços e serviços do farm
Nosso exemplo não inclui todas as funções, serviços e aplicativos de serviço que podem estar em execução em um dado farm do SharePoint. Você não pode usar uma abordagem genérica para alta disponibilidade de tudo em um farm do SharePoint. A seguir estão algumas exclusões importantes para a abordagem padrão para alta disponibilidade:
O Cache Distribuído requer considerações especiais durante o failover. Para saber mais, veja Planeje o serviço de Cache distribuído e Gerenciar o serviço de Cache Distribuído no SharePoint Server.
O Fluxo de Trabalho do SharePoint requer o Gerenciador de Fluxo de Trabalho 1.0, Atualização Cumulativa 3. O fluxo de trabalho de configuração para o SharePoint Server 2016 é idêntico ao do SharePoint Server 2013. Para saber mais, confira Descrição da Atualização Cumulativa 3 do Gerenciador de Fluxo de Trabalho 1.0 e Configurando um Fluxo de Trabalho Altamente Disponível no Gerenciador de Fluxo de Trabalho 1.0.
Observação
[!OBSERVAçãO] A configuração do Fluxo de Trabalho para o SharePoint Server 2016 não mudou em relação ao SharePoint Server 2013. Você deve instalar o Gerenciador de Fluxo de Trabalho 1.0, Atualização Cumulativa 3.
Você pode executar aplicativos de serviço em vários computadores (o que nós recomendamos), mas algumas deles têm instalação única e precisam de uma configuração específica para alta disponibilidade. O aplicativo User Profile é um exemplo famoso.
Usar tolerância a falhas na solução de alta disponibilidade
Depois de criar uma arquitetura que permite funções e cargas de trabalho com alta disponibilidade, você pode usar componentes tolerantes a falhas para aumentar a disponibilidade. Soluções com tolerância a falhas estão disponíveis em toda a infraestrutura, o que inclui os bancos de dados.
Uma infraestrutura tolerante a falhas
A tolerância a falhas está prontamente disponível para quase qualquer componente de hardware na infraestrutura de um farm do SharePoint. Como parte do design de alta disponibilidade, determine as partes da infraestrutura que precisam de tolerância a falhas da perspectiva operacional e de custos. Mesmo que você possa tornar cada parte da infraestrutura tolerante a falhas, isso não significa que você deva.
Servidores de banco de dados e bancos de dados tolerantes a falhas
A plataforma SharePoint e suas cargas de trabalho de aplicativo dependem da disponibilidade e da confiabilidade de todos os bancos de dados do SharePoint e, por isso, bancos de dados com alta disponibilidade são um aspecto extremamente importante da estratégia. Você pode usar os recursos a seguir como soluções de tolerância a falhas para servidores de bancos de dados e bancos de dados do SharePoint:
Clustering de ativação pós-falha do SQL Server (Instâncias de Cluster de Ativação Pós-falha AlwaysOn (FCI) no SQL Server 2014 com Service Pack 1 (SP1)) e SQL Server 2012
Grupos de Disponibilidade AlwaysOn
Espelhamento de bancos de dados de alta disponibilidade no SQL Server
Acerca das Instâncias de Cluster de Ativação Pós-falha AlwaysOn e dos Grupos de Disponibilidade AlwaysOn
Para um cluster de failover, você precisa de armazenamento em disco compartilhado entre dois computadores. Em uma configuração de dois nós, os computadores são configurados como ativo/passivo, o que cria uma instância com redundância total no nó principal. O sistema apenas coloca o nó passivo online quando o nó principal para de funcionar. O disco compartilhado é apresentado apenas a um computador por vez. Essa configuração geralmente é a que exige mais hardwares adicionais. No SQL Server 2014 (SP1) e no SQL Server 2012, este tipo de configuração de cluster é uma Instância de Cluster de Ativação Pós-falha AlwaysOn e é uma forma específica de instalar o SQL Server. Devido aos requisitos da configuração, você não pode transformar facilmente uma instalação padrão do SQL Server em uma Instância de Cluster de Failover.
Um Grupo de Disponibilidade AlwaysOn é uma tecnologia diferente no SQL Server 2014 (SP1) e no SQL Server 2012 (considere-o um descendente do Espelhamento da Base de Dados) que utiliza algumas funcionalidades expostas pelo Clustering do Windows. Mas não exige espaço em disco compartilhado, e não é preciso instalar uma configuração especializada do SQL Server nos computadores em um grupo de disponibilidade. Depois de um servidor de base de dados ser adicionado a um Cluster do Windows, é bastante fácil ativar os Grupos de Disponibilidade AlwaysOn e, em seguida, configurar o grupo de disponibilidade pretendido.
Em resumo, qualquer servidor que execute o SQL Server 2014 (SP1) e o SQL Server 2012 Enterprise Edition pode utilizar Grupos de Disponibilidade AlwaysOn ao associar um cluster e configurar o grupo de disponibilidade. Os clusters de ativação pós-falha AlwaysOn requerem passos especiais de hardware e configuração para configurar Instâncias de Cluster de Ativação Pós-falha. Cada uma destas tecnologias tem a sua utilização para ambientes específicos e ambas são concorrentes complementares. Para saber mais sobre esses recursos, confira Soluções de alta disponibilidade (SQL Server). Para obter ajuda para decidir que tecnologia de disponibilidade do SQL Server utilizar, veja Continuidade de negócio e recuperação de bases de dados – SQL Server.
Importante
[!IMPORTANTE] Como cada opção de alta disponibilidade do SQL Server tem seus próprios recursos, pontos fortes e pontos fracos, uma opção não é necessariamente melhor que outra. Por exemplo, num determinado cenário que utiliza Grupos de Disponibilidade AlwaysOn, minimizar a perda de dados pode ser melhor do que qualquer ganho de desempenho alcançado pelas Instâncias de Cluster de Ativação Pós-falha AlwaysOn. Você precisa escolher uma solução de alta disponibilidade adequada para as necessidades do seu negócio e da infraestrutura de TI.
Um fator determinante na seleção de uma opção de SQL Server é usar os bancos de dados do SharePoint. Você precisa entender as características dos bancos de dados do SharePoint Server. Cada banco de dados tem requisitos ou restrições específicos, que determinam a solução de tolerância a falhas do SQL Server apropriada e compatível com o ambiente de produção. Nós recomendamos que você leia os artigos a seguir:
Clustering de failover do SQL Server
O clustering de failover oferece suporte a disponibilidade para uma instância de SQL Server no SQL Server 2014 (SP1) ou no SQL Server 2012.
Um cluster de failover é uma combinação de um ou mais nós ou servidores, e dois ou mais discos compartilhados. Embora uma instância de um cluster de failover apareça como um único computador, a instância permite failover de um nó para outro caso o nó atual fique indisponível. O SharePoint Server pode operar em qualquer combinação de nós ativos e passivos em um cluster para o qual o SQL Server ofereça suporte.
SharePoint Server se refere ao cluster como um todo. Portanto, o failover é automático e sem interrupções da perspectiva do SharePoint Server.
Observação
Quando ocorre um failover, planejado ou não, as conexões são perdidas e devem ser estabelecidas novamente ao passar de um nó de cluster para outro.
Para obter informações detalhadas sobre o clustering de ativação pós-falha do SQL Server, veja Instâncias de Cluster de Ativação Pós-falha AlwaysOn (SQL Server).
Grupos de Disponibilidade AlwaysOn do SQL Server e Espelhamento da Base de Dados do SQL Server
O principal benefício dos Grupos de Disponibilidade AlwaysOn do SQL Server e do Espelhamento da Base de Dados do SQL Server é que ambos fornecem redundância de dados completa ou quase completa, consoante a forma como os configura para o processamento de transações. Além de minimizar a perda de dados, o failover automático minimiza o tempo de inatividade para bancos de dados de produção.
Importante
[!OBSERVAçãO] Embora o SQL Server 2016, o SQL Server 2014 (SP1) e o SQL Server 2012 tenham suporte ao espelhamento de bancos de dados, esse recurso está planejado para ser preterido. Recomendamos que você evite usar esse recurso em um plano de desenvolvimento novo. Faça planos para mudar aplicativos que usem esse recurso no momento. Em alternativa, utilize Grupos de Disponibilidade AlwaysOn.
Grupos de Disponibilidade AlwaysOn
A funcionalidade Grupos de Disponibilidade AlwaysOn do SQL Server é uma solução de elevada disponibilidade e recuperação após desastre que fornece uma alternativa de nível empresarial ao espelhamento da base de dados. Os Grupos de Disponibilidade AlwaysOn suportam um ambiente de ativação pós-falha para uma ou mais bases de dados de utilizador contidas numa coleção definida pelo utilizador. Essa coleção, um grupo de disponibilidade, consiste nos seguintes componentes:
Réplicas, que são um conjunto discreto de bancos de dados, chamados bancos de dados de disponibilidade, que são tratados como uma unidade única. Um grupo de disponibilidade oferece suporte para uma réplica primária e até quatro réplicas secundárias.
Uma instância específica do SQL Server para hospedar cada réplica e manter uma cópia local de cada banco de dados que pertence ao grupo de disponibilidade.
Quando um grupo de disponibilidade faz failover para uma instância ou servidor de destino, todos os bancos de dados no grupo também fazem failover. Uma vez que o SQL Server 2014 (SP1) e o SQL Server 2012 podem alojar vários grupos de disponibilidade num único servidor, pode configurar o AlwaysOn para efetuar a ativação pós-falha para instâncias do SQL Server em servidores diferentes. Dessa forma, você precisa de menos servidores de reserva de alto desempenho ociosos para lidar com a carga completa do servidor principal, o que é um dos muitos benefícios dos grupos de disponibilidade.
Observação
Problemas de banco de dados, como quando um banco de dados se torna suspeito devido à perda de um arquivo de dados, exclusão de um banco de dados ou corrupção do log de transações, não causam failover.
Para obter mais informações sobre os benefícios dos Grupos de Disponibilidade AlwaysOn e uma descrição geral da terminologia dos Grupos de Disponibilidade AlwaysOn, veja Grupos de Disponibilidade AlwaysOn (SQL Server).
Espelhamento de bancos de dados
Observação
[!OBSERVAçãO] Embora o SQL Server 2016, o SQL Server 2014 (SP1) e o SQL Server 2012 tenham suporte ao espelhamento de bancos de dados, esse recurso está planejado para ser preterido. Recomendamos que você evite usar esse recurso em um plano de desenvolvimento novo. Faça planos para mudar aplicativos que usem esse recurso no momento. Em alternativa, utilize Grupos de Disponibilidade AlwaysOn.
O espelhamento de bancos de dados proporciona redundância ao manter uma cópia espelhada dos bancos de dados no servidor de bancos de dados principal. O espelhamento é implementado individualmente para cada banco de dados e funciona apenas naqueles que usam o modelo de recuperação completa.
Observação
[!OBSERVAçãO] Há dois modos operacionais de espelhamento. Um deles, o modo de alta segurança, oferece suporte para operação síncrona. Nesse modo, quando uma sessão começa o servidor espelho sincroniza o banco de dados espelho e o banco de dados principal o mais rápido possível. Assim que os bancos de dados estiverem sincronizados, uma transação é gravada no log do servidor secundário e, em seguida, reproduzida. (O controle retorna ao servidor principal assim que a transação for fortalecida.) O outro modo de espelhamento é o de alto desempenho, que usa operação assíncrona para reduzir a latência de transação, ao custo de maior perda de dados.
Para espelhamento de alta disponibilidade em um farm do SharePoint, você precisa usar o modo de alta segurança com failover automático. O espelhamento de bancos de dados de alta segurança requer três instâncias de servidor: um principal, um espelho e uma testemunha. O servidor testemunha permite que o SQL Server faça failover automaticamente do servidor principal para o espelho. O failover do banco de dados principal para o espelho demora geralmente vários segundos.
Para saber mais sobre o espelhamento de banco de dados, consulte o artigo Espelhamento de Banco de Dados.
Importante
Bancos de dados que estão configurados para usar o provedor de armazenamento BLOB remoto FILESTREAM do SQL Server não podem ser espelhados.
Comparações de disponibilidade de banco de dados e estratégias de recuperação para um único farm
A escolha de uma tecnologia de SQL Server para alta disponibilidade e recuperação de desastre deve ser baseada nos objetivos de negócios da organização para objetivo de ponto de recuperação (RPO) e objetivo de tempo de recuperação (RTO). RPO e RTO são geralmente associados a recuperação de desastre, mas algumas falhas estão fora do escopo de um desastre e ainda assim exigem recuperação da mídia de backup local no data center principal.
Importante
[!IMPORTANTE] Dependendo do banco de dados, os vários bancos de dados do SharePoint Server oferecem suporte apenas a opções específicas de alta disponibilidade do SQL Server. Para saber mais, confira Suporte para as opções de alta disponibilidade e recuperação de desastres para bancos de dados do SharePoint.
A tabela a seguir fornece uma comparação geral dos resultados de RPO e RTO que permitem conseguir soluções para o SQL Server.
Observação
[!OBSERVAçãO] As medidas de tempo na tabela a seguir são para comparação de opções de bancos de dados. Na prática, o tempo depende da carga de trabalho, volume de dados e procedimentos de failover.
Comparação de RPO e RTO com base na tecnologia de banco de dados
| Resolução SQL Server | Perda potencial de dados (RPO) | Tempo potencial de recuperação (RTO) | Failover automático |
Secundários legíveis Nota: O SharePoint Server suporta réplicas secundárias legíveis para utilização do runtime. Para obter mais informações, consulte Atualização cumulativa do Office 2013 para abril de 2014 e Executar um farm que utiliza bases de dados só de leitura no SharePoint Server. |
|---|---|---|---|---|
| Grupo de Disponibilidade AlwaysOn (consolidação síncrona) |
Zero |
Segundos |
Sim |
0 – 2 |
| Grupo de Disponibilidade AlwaysOn (consolidação assíncrona) |
Segundos |
Minutos |
Não |
0 – 4 |
| Instância de Cluster de Ativação Pós-falha AlwaysOn |
Não se aplica Um FCI por si não oferece proteção de dados. O volume de perda de dados depende da implementação do sistema de armazenamento. |
Segundos a minutos |
Sim |
Não se aplica |
| Espelhamento de banco de dados – alta segurança (modo síncrono + servidor testemunha) |
Zero |
Segundos |
Sim |
Não se aplica |
| Espelhamento de banco de dados – alto desempenho (modo assíncrono) |
Segundos |
Minutos |
Não |
Não se aplica |
| Backup, copiar, restaurar |
Horas ou zero se for possível acessar o final do log após a falha. |
Horas a dias |
Não |
Não durante uma recuperação |
Comparação do Cluster do SQL Server, do Grupo de Disponibilidade AlwaysOn e do espelho da Base de Dados
| Processo | Cluster de failover do SQL Server | GRUPO de Disponibilidade AlwaysOn do SQL Server 2014 (SP1) e SQL Server 2012 | Espelho de alta disponibilidade do SQL Server |
|---|---|---|---|
| Tempo para failover |
O membro do cluster assume quase imediatamente após a falha. Ocorre um atraso enquanto o nó do cluster aumenta a rotação. |
A réplica assume quase imediatamente após a falha. Ocorre um atraso enquanto a réplica secundária aumenta a rotação. |
O espelho assume assim que a fila de retrabalho é processada. |
| Consistência de transações |
Sim |
Sim |
Sim |
| Simultaneidade de transações |
Sim |
Sim |
Sim |
| Tempo para recuperação |
Tempo de recuperação menor que um grupo de disponibilidade. |
Tempo de recuperação maior que um cluster de failover, mas mais rápido que uma solução espelhada. |
Tempo de recuperação um pouco maior que cluster ou grupo de disponibilidade. |
| Etapas necessárias para failover |
Os nós de banco de dados detectam uma falha automaticamente. SharePoint Server faz referência ao cluster, de modo que o failover é automático e sem interrupções. |
O ouvinte do grupo de disponibilidade detecta automaticamente uma falha, e o failover é automático e sem interrupções. |
Os bancos de dados detectam a falha automaticamente. O SharePoint Server reconhece o local do espelho, se tiver sido configurado corretamente, de modo que o failover é automático. |
| Proteção contra falha de armazenamento |
O cluster de failover em si não oferece proteção aos dados. A quantidade de dados perdidos depende da implementação do sistema de armazenamento. Por exemplo, um ambiente SAN tem componentes redundantes, como vários caminhos de arquivo, RAID e peças de reposição quentes. |
Protege contra falha de armazenamento, pois a réplica principal grava nos discos locais nas réplicas secundárias. |
Protege contra falha de armazenamento porque os servidores de banco de dados principal e espelho gravam nos discos locais. |
| Tipos de armazenamento compatíveis |
Requer armazenamento compartilhado, que é mais caro que armazenamento dedicado. |
Pode usar soluções de armazenamento de conexão direta, menos caras. |
Pode usar armazenamento de conexão direta, menos caro. |
| Requisitos de local |
Os membros do cluster devem estar na mesma sub-rede. Note: Este não é o caso com o SQL Server 2014 (SP1) e o SQL Server 2012. |
Réplicas podem estar em diferentes sub-redes, desde que a latência não cause problemas de desempenho. |
Os servidores principal, espelho e testemunha devem estar na mesma LAN (latência de ida e volta de até 1 milissegundo). |
| Modelo de recuperação |
Modelo de recuperação completa do SQL Server recomendado. Pode utilizar o modelo de recuperação simples do SQL Server. No entanto, o único ponto de recuperação disponível se o cluster for perdido será a última cópia de segurança completa. |
Requer o modo de recuperação completo do SQL Server 2012 e Server 2014 (SP1). |
Requer o modelo de recuperação completa do SQL Server. |
| Gasto adicional de desempenho |
É possível que haja uma diminuição no desempenho enquanto um failover estiver sendo feito. O servidor fica indisponível durante o failover, e as conexões são encerradas e depois estabelecidas de novo no novo nó ativo. |
Os Grupos de Disponibilidade AlwaysOn introduzem latência transacional devido à consolidação síncrona nas réplicas secundárias. O valor da latência depende do número de réplicas secundárias que precisam ser sincronizadas. O gasto adicional com memória e processador é maior que no clustering, mas menor que no espelhamento. |
O espelhamento de alta disponibilidade introduz latência de transação por ser síncrono. Também exige gasto adicional maior de memória e processador. |
| Gasto adicional de operações |
Configurado e mantido no nível do servidor. |
O gasto adicional operacional é maior que clustering e espelhamento. O AlwaysOn requer sobrecarga ao nível do servidor de bases de dados do SQL Server, além do nível do Windows Server. Observação: os objetos de nível de servidor, como trabalhos de agente e logons devem ser mantidos manualmente. Se você adiciona bancos de dados de conteúdo, precisa adicioná-los a um grupo de disponibilidade e depois sincronizar a réplica principal com as secundárias. Em um ambiente de farm do SharePoint, é necessário configurar para que a cadeia de conexão do SharePoint Server esteja associada corretamente ao nome do ouvinte do grupo de disponibilidade. |
O gasto adicional da operação é maior que no clustering. Deve ser configurado e mantido para todos os bancos de dados. A reconfiguração após o failover é manual. Observação: os objetos de nível de servidor, como trabalhos de agente e logons devem ser mantidos manualmente. Se você adiciona bancos de dados de conteúdo, precisa adicioná-los ao principal e depois sincronizar do principal para o espelho. |
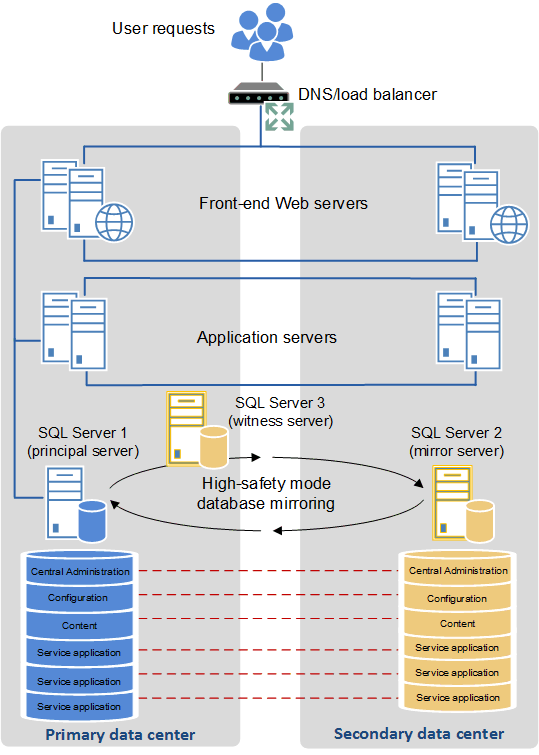
Configurar dois data centers como um único farm (farm "estendido") para ter alta disponibilidade
Algumas empresas têm data centers localizados próximos uns dos outros, conectados por ligações de fibra óptica de alta largura de banda. Quando esse ambiente está disponível, é possível configurar os dois data centers como um único farm. Essa topologia de farm distribuída é chamada de farm "estendido".
Para que a arquitetura de farm estendido funcione como solução suportada de alta disponibilidade, é necessário o seguinte:
Há uma latência altamente consistente dentro do farm de <1 ms (uma via), 99,9% do tempo em um período de dez minutos. (A latência dentro do farm é geralmente definida como sendo a latência entre os servidores da web de front-end e os servidores de banco de dados.)
A velocidade da largura de banda deve ser pelo menos 1 gigabit por segundo.
Para fornecer tolerância a falhas em um farm alongado, use as diretrizes de práticas recomendadas padrão para configurar os bancos de dados e aplicativos de serviço redundantes.
A ilustração a seguir mostra um farm estendido.
Farm estendido
Incorporar operações de backup e restauração em uma estratégia de alta disponibilidade
Uma estratégia de alta disponibilidade precisa incluir as operações apropriadas de backup e restauração para garantir que o farm do SharePoint seja resiliente. Quando ocorre um incidente, como falha de mídia ou erro de usuário, você precisa restaurar a parte afetada do ambiente do farm ou os dados do farm rapidamente. Uma solução eficaz de backup e restauração ajuda a atingir os objetivos de tempo de recuperação (RTO) e objetivos de ponto de recuperação (RPO) que você definiu.
Confira também
Conceitos
Conceitos de alta disponibilidade e recuperação de desastre no SharePoint Server
Escolher uma estratégia de recuperação de desastre para o SharePoint Server