Cenários mais avançados para telemetria
Nota
Este artigo utilizará o Aspire Dashboard para ilustração. Se preferir utilizar outras ferramentas, consulte a documentação da ferramenta que está a utilizar nas instruções de configuração.
Chamada de função automática
Auto Function Calling é um recurso do kernel semântico que permite que o kernel execute funções automaticamente quando o modelo responde com chamadas de função e forneça os resultados de volta ao modelo. Esse recurso é útil para cenários em que uma consulta requer várias iterações de chamadas de função para obter uma resposta final em linguagem natural. Para obter mais detalhes, consulte estes exemplos do GitHub.
Nota
A chamada de função não é suportada por todos os modelos.
Gorjeta
Você ouvirá os termos "ferramentas" e "chamada de ferramentas" às vezes usados indistintamente com "funções" e "chamada de função".
Pré-requisitos
- Uma implantação de conclusão de chat do Azure OpenAI que dá suporte à chamada de função.
- Docker
- O SDK .Net mais recente para o seu sistema operacional.
- Uma implantação de conclusão de chat do Azure OpenAI que dá suporte à chamada de função.
- Docker
- Python 3.10, 3.11 ou 3.12 instalado na sua máquina.
Nota
A Observabilidade do Kernel Semântico ainda não está disponível para Java.
Configurar
Criar um novo aplicativo de console
Em um terminal, execute o seguinte comando para criar um novo aplicativo de console em C#:
dotnet new console -n TelemetryAutoFunctionCallingQuickstart
Navegue até o diretório do projeto recém-criado após a conclusão do comando.
Instalar pacotes necessários
Kernel Semântico
dotnet add package Microsoft.SemanticKernelExportador de console OpenTelemetry
dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol
Crie uma aplicação simples com o Kernel Semântico
No diretório do projeto, abra o Program.cs arquivo com seu editor favorito. Vamos criar um aplicativo simples que usa o Kernel Semântico para enviar um prompt para um modelo de conclusão de chat. Substitua o conteúdo existente pelo código a seguir e preencha os valores necessários para deploymentName, endpointe apiKey:
using System.ComponentModel;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using OpenTelemetry;
using OpenTelemetry.Logs;
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
namespace TelemetryAutoFunctionCallingQuickstart
{
class BookingPlugin
{
[KernelFunction("FindAvailableRooms")]
[Description("Finds available conference rooms for today.")]
public async Task<List<string>> FindAvailableRoomsAsync()
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return ["Room 101", "Room 201", "Room 301"];
}
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return $"Room {room} booked.";
}
}
class Program
{
static async Task Main(string[] args)
{
// Endpoint to the Aspire Dashboard
var endpoint = "http://localhost:4317";
var resourceBuilder = ResourceBuilder
.CreateDefault()
.AddService("TelemetryAspireDashboardQuickstart");
// Enable model diagnostics with sensitive data.
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnosticsSensitive", true);
using var traceProvider = Sdk.CreateTracerProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddSource("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var meterProvider = Sdk.CreateMeterProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddMeter("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var loggerFactory = LoggerFactory.Create(builder =>
{
// Add OpenTelemetry as a logging provider
builder.AddOpenTelemetry(options =>
{
options.SetResourceBuilder(resourceBuilder);
options.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint));
// Format log messages. This is default to false.
options.IncludeFormattedMessage = true;
options.IncludeScopes = true;
});
builder.SetMinimumLevel(LogLevel.Information);
});
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddSingleton(loggerFactory);
builder.AddAzureOpenAIChatCompletion(
deploymentName: "your-deployment-name",
endpoint: "your-azure-openai-endpoint",
apiKey: "your-azure-openai-api-key"
);
builder.Plugins.AddFromType<BookingPlugin>();
Kernel kernel = builder.Build();
var answer = await kernel.InvokePromptAsync(
"Reserve a conference room for me today.",
new KernelArguments(
new OpenAIPromptExecutionSettings {
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
}
)
);
Console.WriteLine(answer);
}
}
}
No código acima, primeiro definimos um plugin simulado de reserva de salas de conferência com duas funções: FindAvailableRoomsAsync e BookRoomAsync. Em seguida, criamos um aplicativo de console simples que registra o plug-in no kernel e pedimos ao kernel para chamar automaticamente as funções quando necessário.
Criar um novo ambiente virtual Python
python -m venv telemetry-auto-function-calling-quickstart
Ative o ambiente virtual.
telemetry-auto-function-calling-quickstart\Scripts\activate
Instalar pacotes necessários
pip install semantic-kernel opentelemetry-exporter-otlp-proto-grpc
Crie um script Python simples com o Kernel Semântico
Crie um novo script Python e abra-o com o seu editor favorito.
New-Item -Path telemetry_auto_function_calling_quickstart.py -ItemType file
Vamos criar um script Python simples que usa o Kernel Semântico para enviar um prompt para um modelo de conclusão de chat. Substitua o conteúdo existente pelo código a seguir e preencha os valores necessários para deployment_name, endpointe api_key:
import asyncio
import logging
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.metrics import set_meter_provider
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.metrics.view import DropAggregation, View
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.semconv.resource import ResourceAttributes
from opentelemetry.trace import set_tracer_provider
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.prompt_execution_settings import PromptExecutionSettings
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.functions.kernel_function_decorator import kernel_function
class BookingPlugin:
@kernel_function(
name="find_available_rooms",
description="Find available conference rooms for today.",
)
def find_available_rooms(self,) -> list[str]:
return ["Room 101", "Room 201", "Room 301"]
@kernel_function(
name="book_room",
description="Book a conference room.",
)
def book_room(self, room: str) -> str:
return f"Room {room} booked."
# Endpoint to the Aspire Dashboard
endpoint = "http://localhost:4317"
# Create a resource to represent the service/sample
resource = Resource.create({ResourceAttributes.SERVICE_NAME: "telemetry-aspire-dashboard-quickstart"})
def set_up_logging():
exporter = OTLPLogExporter(endpoint=endpoint)
# Create and set a global logger provider for the application.
logger_provider = LoggerProvider(resource=resource)
# Log processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
logger_provider.add_log_record_processor(BatchLogRecordProcessor(exporter))
# Sets the global default logger provider
set_logger_provider(logger_provider)
# Create a logging handler to write logging records, in OTLP format, to the exporter.
handler = LoggingHandler()
# Add filters to the handler to only process records from semantic_kernel.
handler.addFilter(logging.Filter("semantic_kernel"))
# Attach the handler to the root logger. `getLogger()` with no arguments returns the root logger.
# Events from all child loggers will be processed by this handler.
logger = logging.getLogger()
logger.addHandler(handler)
logger.setLevel(logging.INFO)
def set_up_tracing():
exporter = OTLPSpanExporter(endpoint=endpoint)
# Initialize a trace provider for the application. This is a factory for creating tracers.
tracer_provider = TracerProvider(resource=resource)
# Span processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
tracer_provider.add_span_processor(BatchSpanProcessor(exporter))
# Sets the global default tracer provider
set_tracer_provider(tracer_provider)
def set_up_metrics():
exporter = OTLPMetricExporter(endpoint=endpoint)
# Initialize a metric provider for the application. This is a factory for creating meters.
meter_provider = MeterProvider(
metric_readers=[PeriodicExportingMetricReader(exporter, export_interval_millis=5000)],
resource=resource,
views=[
# Dropping all instrument names except for those starting with "semantic_kernel"
View(instrument_name="*", aggregation=DropAggregation()),
View(instrument_name="semantic_kernel*"),
],
)
# Sets the global default meter provider
set_meter_provider(meter_provider)
# This must be done before any other telemetry calls
set_up_logging()
set_up_tracing()
set_up_metrics()
async def main():
# Create a kernel and add a service
kernel = Kernel()
kernel.add_service(AzureChatCompletion(
api_key="your-azure-openai-api-key",
endpoint="your-azure-openai-endpoint",
deployment_name="your-deployment-name"
))
kernel.add_plugin(BookingPlugin(), "BookingPlugin")
answer = await kernel.invoke_prompt(
"Reserve a conference room for me today.",
arguments=KernelArguments(
settings=PromptExecutionSettings(
function_choice_behavior=FunctionChoiceBehavior.Auto(),
),
),
)
print(answer)
if __name__ == "__main__":
asyncio.run(main())
No código acima, primeiro definimos um plugin simulado de reserva de salas de conferência com duas funções: find_available_rooms e book_room. Em seguida, criamos um script Python simples que registra o plugin no kernel e pedimos ao kernel para chamar automaticamente as funções quando necessário.
Variáveis de ambiente
Consulte este artigo para obter mais informações sobre como configurar as variáveis de ambiente necessárias para permitir que o kernel emita extensões para conectores de IA.
Nota
A Observabilidade do Kernel Semântico ainda não está disponível para Java.
Iniciar o Painel de Instrumentos do Aspire
Siga as instruções aqui para iniciar o painel. Quando o painel estiver em execução, abra um navegador e navegue até para http://localhost:18888 acessar o painel.
Executar
Execute o aplicativo de console com o seguinte comando:
dotnet run
Execute o script Python com o seguinte comando:
python telemetry_auto_function_calling_quickstart.py
Nota
A Observabilidade do Kernel Semântico ainda não está disponível para Java.
Deverá ver um resultado semelhante ao seguinte:
Room 101 has been successfully booked for you today.
Inspecionar dados de telemetria
Depois de executar o aplicativo, vá até o painel para inspecionar os dados de telemetria.
Encontre o rastreamento para o aplicativo na guia Rastreamentos . Você deve ter cinco extensões no rastreamento:
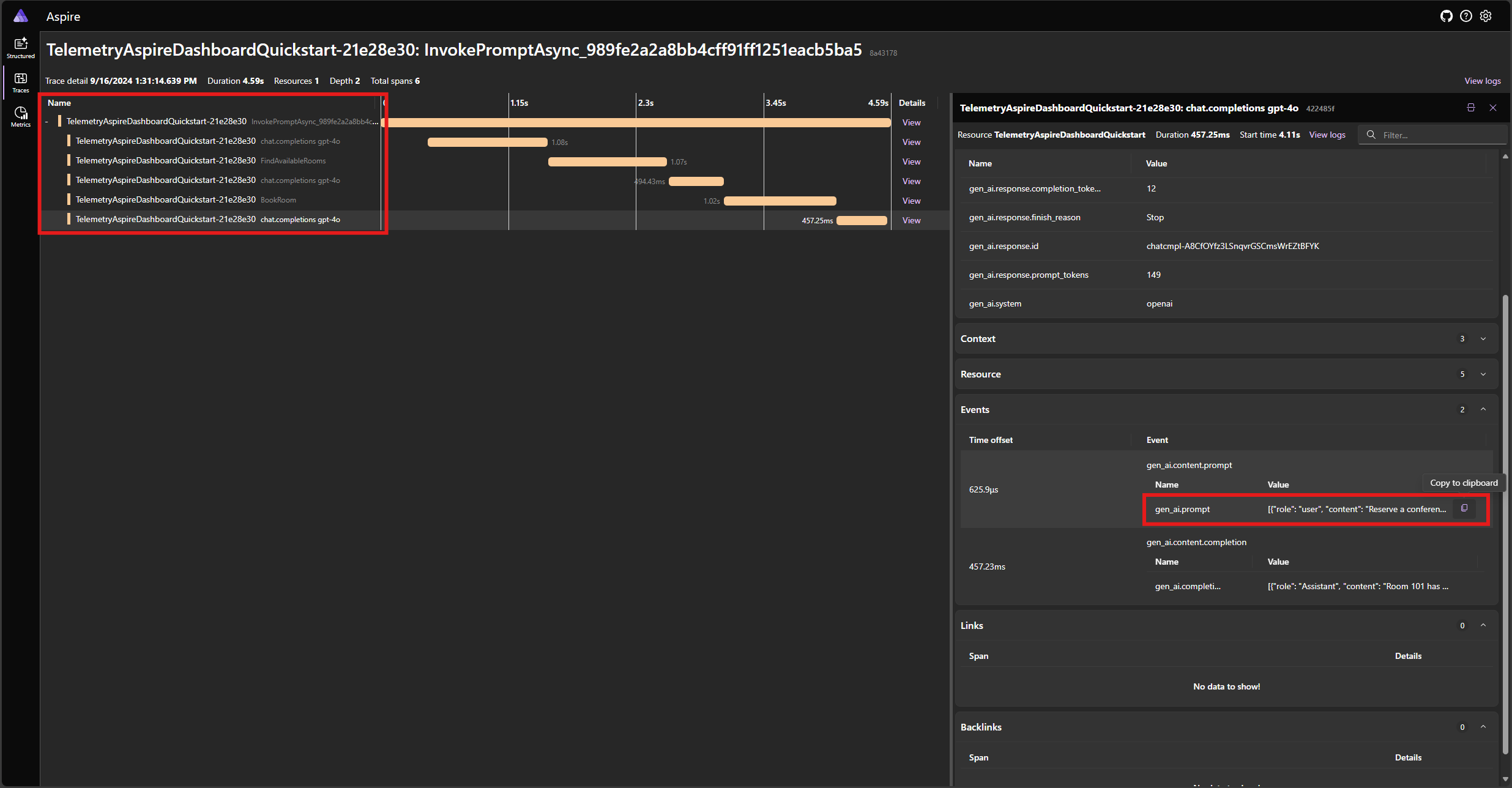
Estes 5 vãos representam as operações internas do kernel com a chamada de função automática ativada. Primeiro, ele invoca o modelo, que solicita uma chamada de função. Em seguida, o kernel executa automaticamente a função FindAvailableRoomsAsync e retorna o resultado para o modelo. O modelo então solicita outra chamada de função para fazer uma reserva, e o kernel executa automaticamente a função BookRoomAsync e retorna o resultado para o modelo. Finalmente, o modelo retorna uma resposta de linguagem natural para o usuário.
E se você clicar na última extensão e procurar o prompt no gen_ai.content.prompt evento, você verá algo semelhante ao seguinte:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_NtKi0OgOllJj1StLkOmJU8cP",
"function": { "arguments": {}, "name": "FindAvailableRooms" },
"type": "function"
}
]
},
{
"role": "tool",
"content": "[\u0022Room 101\u0022,\u0022Room 201\u0022,\u0022Room 301\u0022]"
},
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_mjQfnZXLbqp4Wb3F2xySds7q",
"function": { "arguments": { "room": "Room 101" }, "name": "BookRoom" },
"type": "function"
}
]
},
{ "role": "tool", "content": "Room Room 101 booked." }
]
Este é o histórico de bate-papo que é construído à medida que o modelo e o kernel interagem um com o outro. Isso é enviado para o modelo na última iteração para obter uma resposta em linguagem natural.
Encontre o rastreamento para o aplicativo na guia Rastreamentos . Você deve ter cinco extensões no rastreamento agrupadas sob a AutoFunctionInvocationLoop extensão:
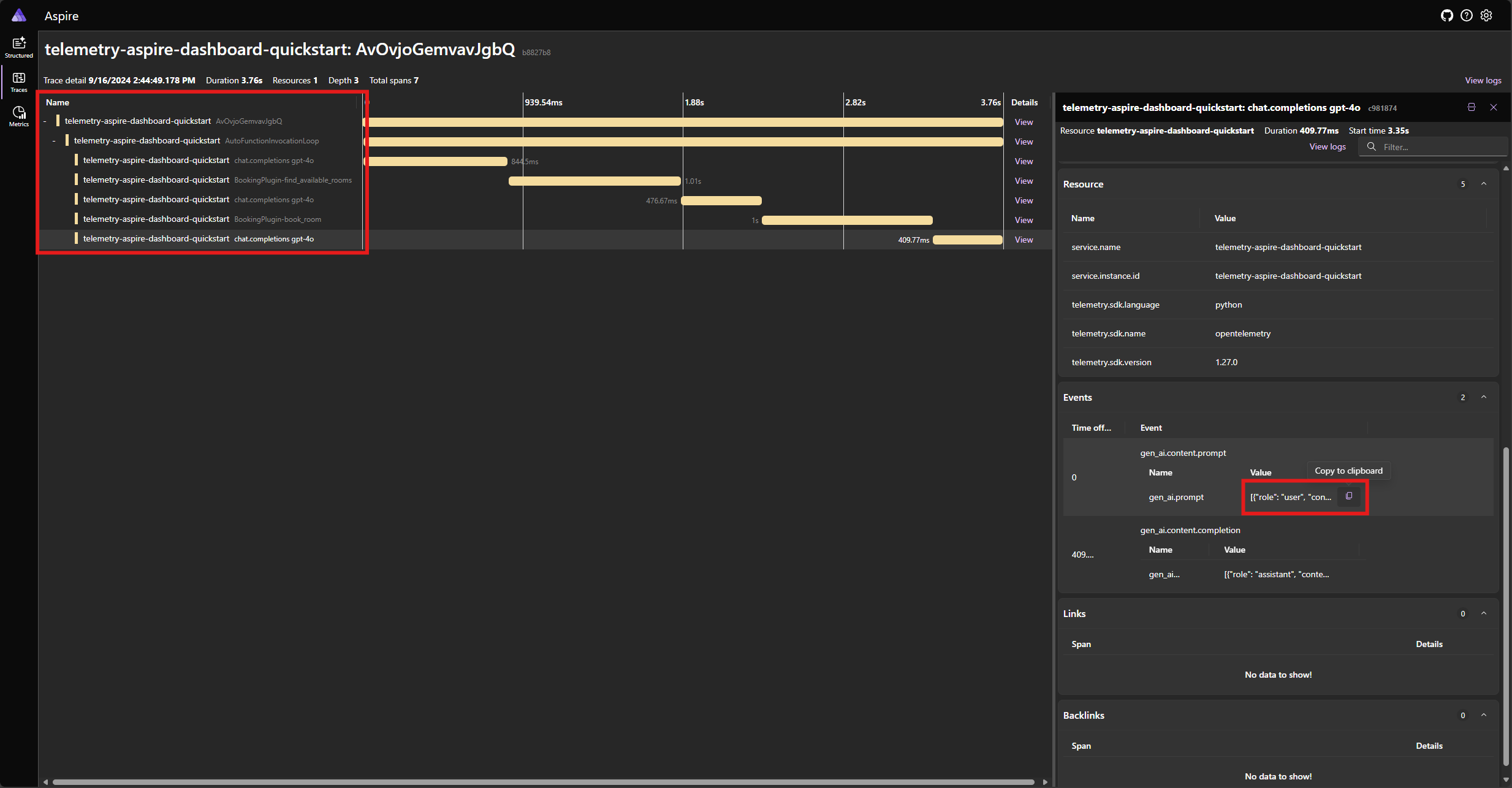
Estes 5 vãos representam as operações internas do kernel com a chamada de função automática ativada. Primeiro, ele invoca o modelo, que solicita uma chamada de função. Em seguida, o kernel executa automaticamente a função find_available_rooms e retorna o resultado para o modelo. O modelo então solicita outra chamada de função para fazer uma reserva, e o kernel executa automaticamente a função book_room e retorna o resultado para o modelo. Finalmente, o modelo retorna uma resposta de linguagem natural para o usuário.
E se você clicar na última extensão e procurar o prompt no gen_ai.content.prompt evento, você verá algo semelhante ao seguinte:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_ypqO5v6uTRlYH9sPTjvkGec8",
"type": "function",
"function": {
"name": "BookingPlugin-find_available_rooms",
"arguments": "{}"
}
}
]
},
{
"role": "tool",
"content": "['Room 101', 'Room 201', 'Room 301']",
"tool_call_id": "call_ypqO5v6uTRlYH9sPTjvkGec8"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_XDZGeTfNiWRpYKoHoH9TZRoX",
"type": "function",
"function": {
"name": "BookingPlugin-book_room",
"arguments": "{\"room\":\"Room 101\"}"
}
}
]
},
{
"role": "tool",
"content": "Room Room 101 booked.",
"tool_call_id": "call_XDZGeTfNiWRpYKoHoH9TZRoX"
}
]
Este é o histórico de bate-papo que é construído à medida que o modelo e o kernel interagem um com o outro. Isso é enviado para o modelo na última iteração para obter uma resposta em linguagem natural.
Nota
A Observabilidade do Kernel Semântico ainda não está disponível para Java.
Processamento de erros
Se ocorrer um erro durante a execução de uma função, o kernel detetará automaticamente o erro e retornará uma mensagem de erro para o modelo. O modelo pode usar essa mensagem de erro para fornecer uma resposta em linguagem natural ao usuário.
Modifique a BookRoomAsync função no código C# para simular um erro:
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
throw new Exception("Room is not available.");
}
Execute o aplicativo novamente e observe o rastreamento no painel. Você deve ver a extensão que representa a chamada de função do kernel com um erro:
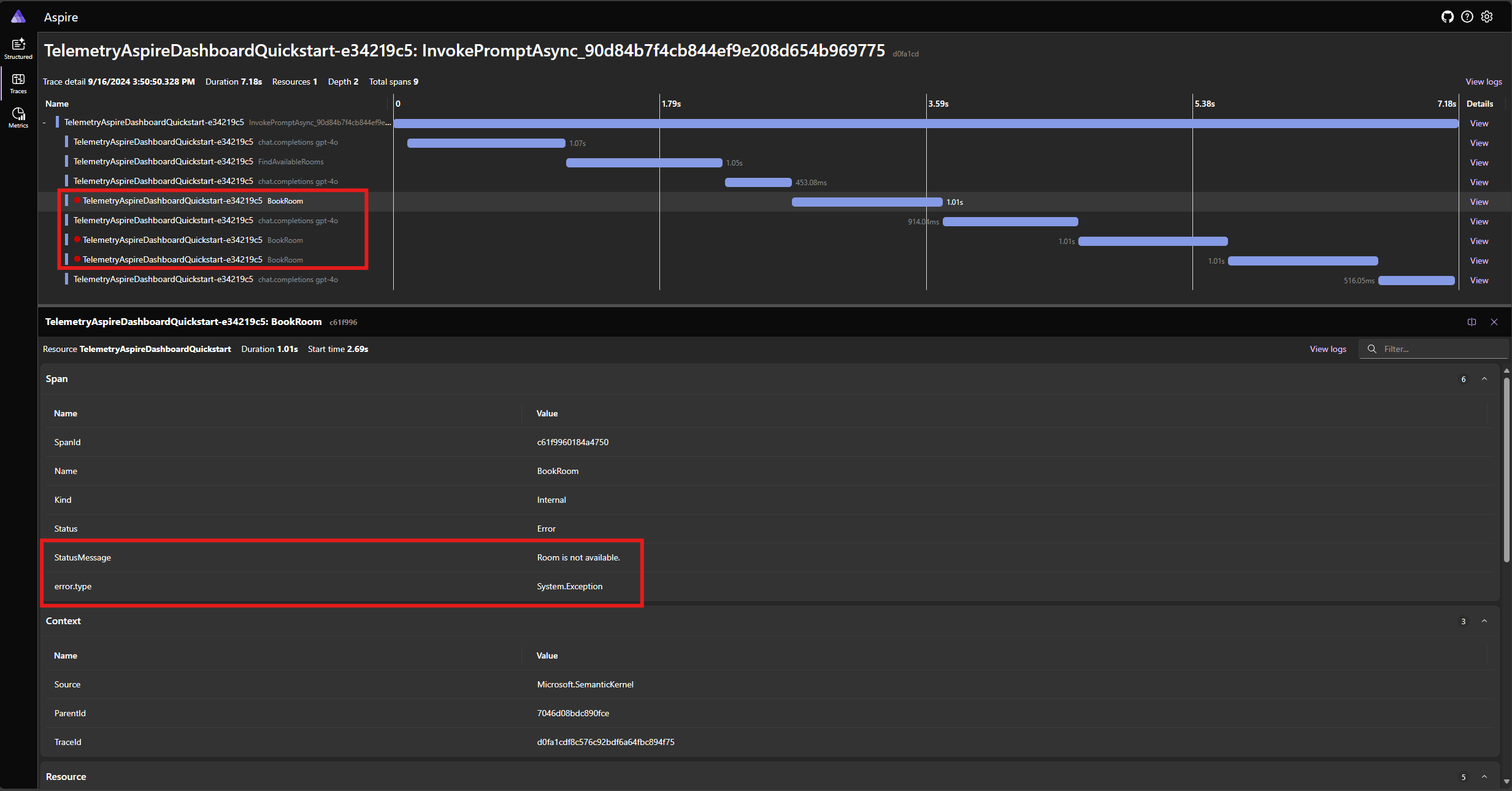
Nota
É muito provável que as respostas do modelo ao erro possam variar cada vez que você executa o aplicativo, porque o modelo é estocástico. Você pode ver o modelo reservando os três quartos ao mesmo tempo, ou reservando um na primeira vez e reservando os outros dois na segunda vez, etc.
Modifique a book_room função no código Python para simular um erro:
@kernel_function(
name="book_room",
description="Book a conference room.",
)
async def book_room(self, room: str) -> str:
# Simulate a remote call to a booking system
await asyncio.sleep(1)
raise Exception("Room is not available.")
Execute o aplicativo novamente e observe o rastreamento no painel. Você deve ver a extensão que representa a chamada de função do kernel com um erro e o rastreamento de pilha:
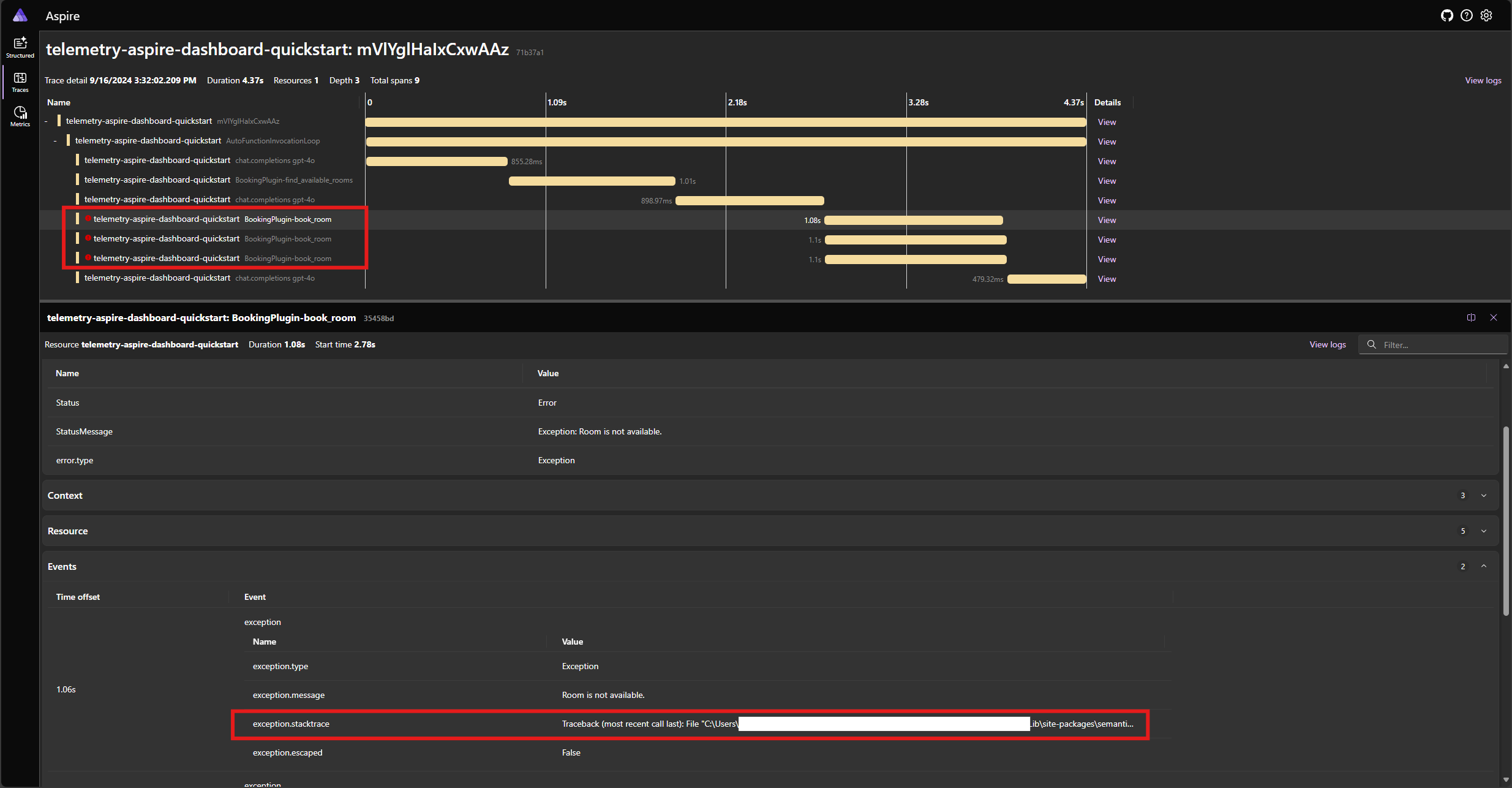
Nota
É muito provável que as respostas do modelo ao erro possam variar cada vez que você executa o aplicativo, porque o modelo é estocástico. Você pode ver o modelo reservando os três quartos ao mesmo tempo, ou reservando um na primeira vez e reservando os outros dois na segunda vez, etc.
Nota
A Observabilidade do Kernel Semântico ainda não está disponível para Java.
Próximos passos e leitura adicional
Na produção, seus serviços podem receber um grande número de solicitações. O Kernel Semântico gerará uma grande quantidade de dados de telemetria. alguns dos quais podem não ser úteis para o seu caso de uso e introduzirão custos desnecessários para armazenar os dados. Você pode usar o recurso de amostragem para reduzir a quantidade de dados de telemetria coletados.
A observabilidade no Kernel Semântico está constantemente melhorando. Você pode encontrar as últimas atualizações e novos recursos no repositório GitHub.