Análises e ingestão no Microsoft Purview
Este artigo fornece uma descrição geral das funcionalidades de Análise e Ingestão no Microsoft Purview. Estas funcionalidades ligam a sua conta do Microsoft Purview às suas origens para preencher o mapa de dados e Catálogo unificado para que possa começar a explorar e gerir os seus dados através do Microsoft Purview.
- A análise captura metadados de origens de dados e leva-os para o Microsoft Purview.
-
A ingestão processa metadados e armazena-os em Catálogo unificado de ambos:
- Análises da origem de dados – os metadados analisados são adicionados à Mapa de Dados do Microsoft Purview.
- Ligações de linhagem – os recursos de transformação adicionam metadados sobre as respetivas origens, saídas e atividades ao Mapa de Dados do Microsoft Purview.
Verificação
Depois de as origens de dados serem registadas na sua conta do Microsoft Purview, o passo seguinte é analisar as origens de dados. O processo de análise estabelece uma ligação à origem de dados e captura metadados técnicos, como nomes, tamanho de ficheiro, colunas, entre outros. Também extrai o esquema para origens de dados estruturadas, aplica classificações em esquemas e aplica etiquetas de confidencialidade se o Mapa de Dados do Microsoft Purview estiver ligado a um portal de conformidade do Microsoft Purview. O processo de análise pode ser acionado para ser executado imediatamente ou pode ser agendado para ser executado periodicamente para manter a sua conta do Microsoft Purview atualizada.
Para cada análise, existem personalizações que pode aplicar para que esteja apenas a analisar as informações de que precisa, em vez de toda a origem.
Escolher um método de autenticação para as suas análises
O Microsoft Purview está seguro por predefinição. Não são armazenadas palavras-passe ou segredos diretamente no Microsoft Purview, pelo que tem de escolher um método de autenticação para as suas origens. Existem várias formas possíveis de autenticar a sua conta do Microsoft Purview, mas nem todos os métodos são suportados para cada origem de dados.
- Identidade Gerida
- Principal de Serviço
- Autenticação SQL
- Autenticação do Windows
- ARN da Função
- Autenticação Delegada
- Chave de Consumidor
- Chave da Conta ou Autenticação Básica
Sempre que possível, uma Identidade Gerida é o método de autenticação preferencial porque elimina a necessidade de armazenar e gerir credenciais para origens de dados individuais. Isto pode reduzir significativamente o tempo que você e a sua equipa gastam a configurar e a resolver problemas de autenticação para análises. Quando ativa uma identidade gerida para a sua conta do Microsoft Purview, é criada uma identidade no Microsoft Entra ID e está associada ao ciclo de vida da sua conta.
Definir o âmbito da análise
Ao analisar uma origem, tem a opção de analisar toda a origem de dados ou escolher apenas entidades específicas (pastas/tabelas) para analisar. As opções disponíveis dependem da origem que está a analisar e podem ser definidas para análises únicas e agendadas.
Por exemplo, ao criar e executar uma análise de uma Base de Dados SQL do Azure, pode escolher as tabelas a analisar ou selecionar toda a base de dados.
Para cada entidade (pasta/tabela), haverá três estados de seleção: totalmente selecionados, parcialmente selecionados e não selecionados. No exemplo abaixo, se selecionar "Departamento 1" na hierarquia de pastas, "Departamento 1" é considerado como totalmente selecionado. As entidades principais para "Departamento 1", como "Empresa" e "exemplo", são consideradas parcialmente selecionadas, uma vez que existem outras entidades no mesmo elemento principal que não foram selecionadas, por exemplo "Departamento 2". Serão utilizados ícones diferentes na IU para entidades com diferentes estados de seleção.
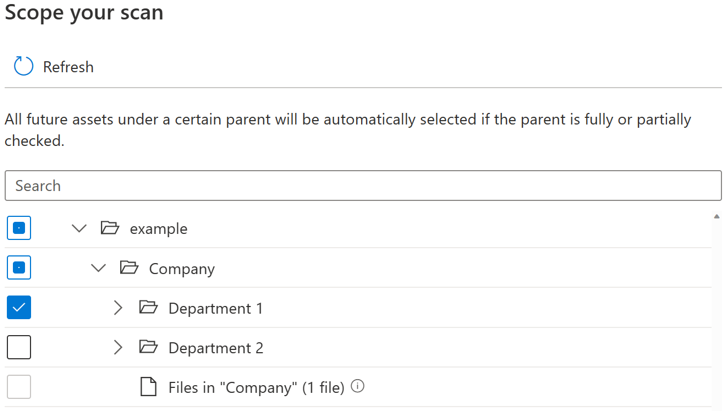
Depois de executar a análise, é provável que existam novos recursos adicionados no sistema de origem. Por predefinição, os recursos futuros num determinado elemento principal serão selecionados automaticamente se o elemento principal estiver selecionado na totalidade ou parcialmente quando executar a análise novamente. No exemplo acima, depois de selecionar "Departamento 1" e executar a análise, todos os novos recursos na pasta "Departamento 1" ou em "Empresa" e "exemplo" serão incluídos quando executar a análise novamente.
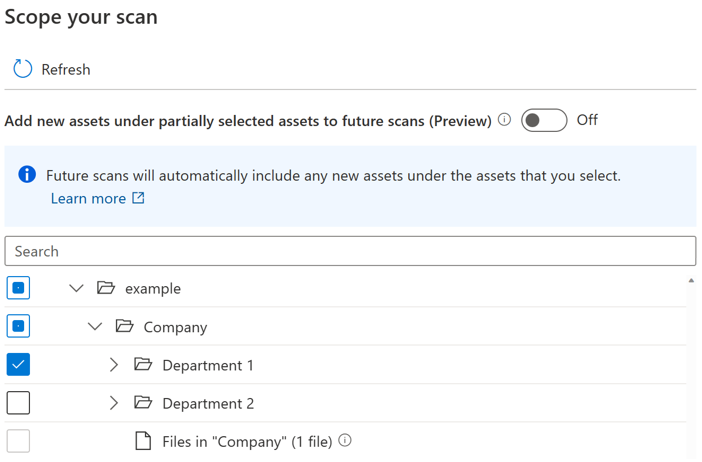
É introduzido um botão de alternar para os utilizadores controlarem a inclusão automática de novos recursos no principal parcialmente selecionado. Por predefinição, o botão de alternar será desativado e o comportamento de inclusão automática do elemento principal parcialmente selecionado está desativado. No mesmo exemplo, com o botão de alternar desativado, todos os novos ativos em pais parcialmente selecionados, como "Empresa" e "exemplo" não serão incluídos quando executar a análise novamente, apenas os novos recursos em "Departamento 1" serão incluídos na análise futura.
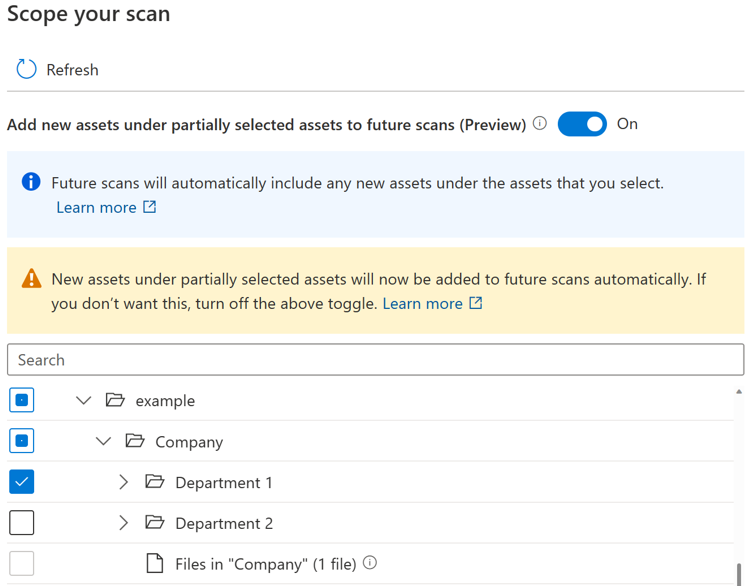
Se o botão de alternar estiver ativado, os novos recursos num determinado elemento principal serão selecionados automaticamente se o elemento principal estiver selecionado na totalidade ou parcialmente quando executar a análise novamente. O comportamento de inclusão é o mesmo que antes da introdução do botão de alternar.
Observação
- A disponibilidade do botão de alternar depende do tipo de origem de dados. Atualmente, está disponível em pré-visualização pública para origens, incluindo Armazenamento de Blobs do Azure, Azure Data Lake Storage Gen 1, Azure Data Lake Storage Gen2, Arquivos do Azure e conjunto de SQL dedicado do Azure (anteriormente SQL DW).
- Para quaisquer análises criadas ou agendadas antes de o botão de alternar ser introduzido, o estado do botão de alternar é definido como ativado e não pode ser alterado. Para quaisquer análises criadas ou agendadas após a introdução do botão de alternar, o estado de alternar não pode ser alterado após a análise ser guardada. Tem de criar uma nova análise para alterar o estado do botão de alternar.
- Quando o botão de alternar está desativado, para origens de tipo de armazenamento como Azure Data Lake Storage Gen2, pode demorar até 4 horas até que a experiência procurar por tipo de origem fique totalmente disponível após a conclusão da tarefa de análise.
Limitações conhecidas
Quando o botão de alternar estiver desativado:
- As entidades de ficheiro num elemento principal parcialmente selecionado não serão analisadas.
- Se todas as entidades existentes num elemento principal estiverem explicitamente selecionadas, o elemento principal será considerado totalmente selecionado e todos os novos recursos no elemento principal serão incluídos quando executar a análise novamente.
Personalizar o nível de análise
Na terminologia Mapa de Dados do Microsoft Purview, existem três níveis diferentes de análise com base no âmbito e nas funcionalidades dos metadados:
- Análise L1: extrai informações básicas e metadados como nome de ficheiro, tamanho e nome completamente qualificado
- Análise L2: extrai o esquema para tipos de ficheiro estruturados e tabelas de bases de dados
- Análise L3: extrai o esquema quando aplicável e sujeita o ficheiro de amostragem ao sistema e às regras de classificação personalizadas
Quando configura uma nova análise ou edita uma análise existente, pode personalizar o nível de análise para analisar origens de dados que já suportaram a configuração do nível de análise.

Por predefinição, a opção "Deteção automática" será selecionada, o que significa que o Microsoft Purview aplicará o nível de análise mais elevado disponível para esta origem de dados. Veja SQL do Azure Base de Dados como exemplo, a "Deteção automática" será resolvida como "Nível 3" quando a análise for executada, uma vez que a origem de dados já suporta a classificação no Microsoft Purview. O nível de análise no detalhe da execução da análise mostra o nível real aplicado.
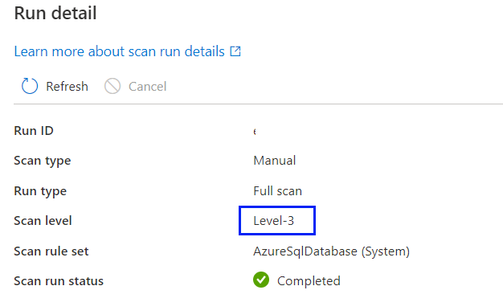
Para todas as execuções de análise no histórico de análise que foram concluídas antes de personalizar o nível de análise à medida que uma nova funcionalidade é introduzida, por predefinição, o nível de análise será definido e apresentado como "Deteção automática".
- Quando um nível de análise mais elevado fica disponível para uma origem de dados, as análises guardadas ou agendadas com o nível de análise definido como "Deteção automática" aplicarão automaticamente o novo nível de análise. Por exemplo, se a classificação como uma nova funcionalidade estiver ativada para uma determinada origem de dados, todas as análises existentes nesta origem de dados aplicarão automaticamente a classificação.
- A definição de nível de análise é apresentada na interface de monitorização de análise para cada execução de análise.
- Se "Nível 1" estiver selecionado, a análise só devolverá metadados técnicos básicos, como o nome do recurso, o tamanho do recurso, o carimbo de data/hora modificado, etc. com base na disponibilidade de metadados existente de uma origem de dados específica. Para SQL do Azure Base de Dados, as entidades de recursos, como tabelas, serão criadas no Mapa de Dados do Microsoft Purview, mas sem extração de esquemas de tabela. (Nota: os utilizadores ainda podem ver o esquema da tabela através da vista dinâmica se tiverem as permissões necessárias no sistema de origem).
- Se "Nível 2" estiver selecionado, a análise devolverá esquemas de tabela e metadados técnicos básicos, mas a amostragem e classificação de dados não serão executadas. Para SQL do Azure Base de Dados, as entidades de recursos de tabela têm um esquema de tabela capturado sem informações de classificação.)
- Se "Nível 3" estiver selecionado, a análise efetuará a amostragem e a classificação de dados. Esta é uma configuração padrão para SQL do Azure Análise da base de dados antes da introdução do nível de análise à medida que é introduzida uma nova funcionalidade.
- Se uma análise agendada estiver definida para um nível de análise mais baixo e posteriormente modificada para um nível de análise mais elevado, a próxima execução de análise efetuará automaticamente uma análise completa e todos os recursos de dados existentes da origem de dados serão atualizados com metadados introduzidos por uma definição de nível de análise superior. Por exemplo, quando uma análise agendada definida com "Nível 2" numa Base de Dados SQL do Azure for alterada para "Nível 3", a próxima execução da análise será uma análise completa e todos os recursos de tabela/vista da Base de Dados existentes SQL do Azure serão atualizados com informações de classificação e todas as análises posteriormente serão retomadas à medida que as análises incrementais forem definidas com "Nível 3".
- Se uma análise agendada estiver definida para um nível de análise mais elevado e posteriormente modificada para um nível de análise inferior, a próxima execução de análise continuará a efetuar uma análise incremental e todos os novos recursos de dados da origem de dados só terão metadados introduzidos por uma definição de nível de análise inferior. Por exemplo, quando uma análise agendada definida com "Nível 3" numa Base de Dados SQL do Azure é alterada para "Nível 2", a próxima execução da análise será uma análise incremental e todos os novos recursos de tabela/vista da Base de Dados SQL do Azure adicionados no Mapa de Dados do Microsoft Purview não terão informações de classificação. Todos os recursos de dados existentes continuarão a manter as informações de classificação geradas do conjunto de análise anterior com "Nível 3".
Observação
- A personalização do nível de análise está atualmente disponível para as seguintes origens de dados: base de dados SQL do Azure, Instância Gerenciada de SQL do Azure, Azure Cosmos DB para NoSQL, Banco de Dados do Azure para PostgreSQL, Banco de Dados do Azure para MySQL, Azure Data Lake Storage Gen2, Armazenamento de Blobs do Azure, Arquivos do Azure, Azure Synapse Analytics, Azure Conjunto de SQL dedicado (anteriormente SQL DW), Azure Data Explorer, Dataverse, Azure Multiple (Subscrição do Azure), Azure Multiple (Grupo de Recursos do Azure), Snowflake, Catálogo do Unity do Azure Databricks
- Atualmente, a funcionalidade só está disponível no IR do Azure e no IR VNet Gerido v2.
Conjunto de regras de análise
Um conjunto de regras de análise determina os tipos de informações que uma análise procura quando está em execução numa das suas origens. As regras disponíveis dependem do tipo de origem que está a analisar, mas incluem aspetos como os tipos de ficheiro que deve analisar e os tipos de classificações de que precisa.
Já existem conjuntos de regras de análise de sistema disponíveis para muitos tipos de origens de dados, mas também pode criar os seus próprios conjuntos de regras de análise para adaptar as suas análises à sua organização.
Agendar a análise
O Microsoft Purview permite-lhe escolher a análise diária, semanal ou mensal numa hora específica que escolher. Saiba mais sobre as opções de agendamento suportadas. As análises diárias ou semanais podem ser adequadas para origens de dados com estruturas que estão ativamente em desenvolvimento ou que mudam frequentemente. A análise mensal é mais adequada para origens de dados que mudam com pouca frequência. A melhor prática é trabalhar com o administrador da origem que pretende analisar para identificar uma altura em que as exigências de computação na origem são baixas.
Como as análises detetam recursos eliminados
Um catálogo do Microsoft Purview só tem conhecimento do estado de um arquivo de dados quando executa uma análise. Para que o catálogo saiba se um ficheiro, tabela ou contentor foi eliminado, compara a saída da última análise com a saída da análise atual. Por exemplo, suponha que, da última vez que analisou uma conta Azure Data Lake Storage Gen2, esta incluía uma pasta com o nome folder1. Quando a mesma conta for novamente analisada, a pasta1 está em falta. Por conseguinte, o catálogo pressupõe que a pasta foi eliminada.
Dica
Devido à forma como os ficheiros eliminados são detetados, podem ser necessárias várias análises com êxito para detetar e resolve recursos eliminados. Se Catálogo unificado não estiver a registar eliminações para uma análise no âmbito, experimente várias análises completas para resolve o problema.
Detetar ficheiros eliminados
A lógica para detetar ficheiros em falta funciona para múltiplas análises pelo mesmo utilizador e por diferentes utilizadores. Por exemplo, suponha que um utilizador executa uma análise única num arquivo de dados Data Lake Storage Gen2 nas pastas A, B e C. Posteriormente, um utilizador diferente na mesma conta executa uma análise única diferente nas pastas C, D e E do mesmo arquivo de dados. Uma vez que a pasta C foi analisada duas vezes, o catálogo verifica se existem possíveis eliminações. No entanto, as pastas A, B, D e E foram analisadas apenas uma vez e o catálogo não as marcar para recursos eliminados.
Para manter os ficheiros eliminados fora do seu catálogo, é importante executar análises regulares. O intervalo de análise é importante porque o catálogo não consegue detetar recursos eliminados até ser executada outra análise. Por isso, se executar análises uma vez por mês num arquivo específico, o catálogo não conseguirá detetar quaisquer recursos de dados eliminados nesse arquivo até executar a próxima análise um mês depois.
Quando enumera grandes arquivos de dados, como Data Lake Storage Gen2, existem várias formas (incluindo erros de enumeração e eventos removidos) de perder informações. Uma análise específica pode falhar se um ficheiro tiver sido criado ou eliminado. Portanto, a menos que o catálogo tenha a certeza de que um ficheiro foi eliminado, não o eliminará do catálogo. Esta estratégia significa que podem existir erros quando um ficheiro que não existe no arquivo de dados analisado ainda existe no catálogo. Em alguns casos, um arquivo de dados poderá ter de ser analisado duas ou três vezes antes de detetar determinados recursos eliminados.
Observação
- Os recursos marcados para eliminação são eliminados após uma análise bem-sucedida. Os recursos eliminados podem continuar a ser visíveis no seu catálogo durante algum tempo antes de serem processados e removidos.
- A deteção de eliminação é suportada apenas para estas origens no Microsoft Purview: áreas de trabalho do Azure Synapse Analytics, SQL Server compatíveis com o Azure Arc, Armazenamento de Blobs do Azure, Arquivos do Azure, Azure Cosmos DB, Azure Data Explorer, Banco de Dados do Azure para MySQL, Banco de Dados do Azure para PostgreSQL, Conjunto de SQL dedicado do Azure, Azure Machine Learning, Base de Dados SQL do Azure e instância gerida do SQL do Azure. Para estas origens, quando um recurso é eliminado da origem de dados, as análises subsequentes removerão automaticamente os metadados e a linhagem correspondentes no Microsoft Purview.
Ingestão
A ingestão é o processo responsável por preencher o mapa de dados com metadados recolhidos através dos seus vários processos.
Ingestão de análises
Os metadados técnicos ou classificações identificados pelo processo de análise são depois enviados para a ingestão. A ingestão analisa a entrada da análise, aplica padrões de conjuntos de recursos, preenche as informações de linhagem disponíveis e, em seguida, carrega o mapa de dados automaticamente. Os recursos/esquemas só podem ser detetados ou organizados após a ingestão estar concluída. Por isso, se a análise estiver concluída, mas não tiver visto os seus recursos no Mapa de Dados ou catálogo, terá de aguardar que o processo de ingestão seja concluído.
Ingestão de ligações de linhagem
Recursos como Azure Data Factory e Azure Synapse podem ser ligados ao Microsoft Purview para trazer informações de origem de dados e linhagem para o seu Mapa de Dados do Microsoft Purview. Por exemplo, quando um pipeline de cópia é executado num Azure Data Factory que foi ligado ao Microsoft Purview, os metadados sobre as origens de entrada, a atividade e as origens de saída são ingeridos no Microsoft Purview e as informações são adicionadas ao mapa de dados.
Se uma origem de dados já tiver sido adicionada ao mapa de dados através de uma análise, as informações de linhagem sobre a atividade serão adicionadas à origem existente. Se a origem de dados ainda não tiver sido adicionada ao mapa de dados, o processo de ingestão de linhagem adiciona-a à coleção de raiz com as respetivas informações de linhagem.
Para obter mais informações sobre as ligações de linhagem disponíveis, veja o guia do utilizador da linhagem.
Próximas etapas
Para obter mais informações ou para obter instruções específicas sobre a análise de origens, siga as ligações abaixo.
- Para compreender os conjuntos de recursos, veja o nosso artigo conjuntos de recursos.
- Como governar uma Base de Dados SQL do Azure
- Linhagem no Microsoft Purview