Melhores práticas de classificação no Mapa de Dados do Microsoft Purview
A classificação de dados no Mapa de Dados do Microsoft Purview é uma forma de categorizar recursos de dados ao atribuir etiquetas ou classes lógicas exclusivas aos recursos de dados. A classificação baseia-se no contexto empresarial dos dados. Por exemplo, pode classificar recursos por Número de Passaporte, Número de Carta de Condução, Número de Cartão de Crédito, Código SWIFT, Nome da Pessoa, entre outros. Saiba mais sobre a classificação de dados no Mapa de Dados.
Este artigo descreve as melhores práticas a adotar ao classificar recursos de dados, para que as suas análises sejam mais eficazes e tenha as informações mais completas possíveis sobre todo o seu património de dados.
Conjunto de regras de análise
Ao utilizar um conjunto de regras de análise, pode configurar as classificações relevantes que devem ser aplicadas à análise específica da origem de dados. Selecione as classificações de sistema relevantes ou selecione classificações personalizadas se tiver criado uma para os dados que está a analisar.
Por exemplo, na imagem seguinte, apenas o sistema selecionado específico e as classificações personalizadas serão aplicados à origem de dados que está a analisar (por exemplo, dados financeiros).

Gestão de anotações
Enquanto decide quais as classificações a aplicar, recomendamos que:
Aceda ao painelClassificações de gestão > deAnotaçõesdo Mapa> de Dados.
Reveja as classificações de sistema disponíveis a aplicar nos recursos de dados que está a analisar. Os nomes formais das classificações de sistema têm um prefixo MICROSOFT .

Crie uma classificação personalizada, se necessário. Selecione o separador Personalizado e, em seguida, selecione + Novo. Saiba como criar uma classificação personalizada.
Crie a regra de classificação para a classificação personalizada que criou no passo anterior. Aceda aRegras de classificação degestão> de anotação do Mapa> de Dados. Aqui, pode criar a regra de classificação para o nome de classificação personalizado que criou no passo anterior.



Classificações personalizadas
Crie classificações personalizadas apenas se as classificações de sistema disponíveis não corresponderem às suas necessidades.
Para o nome da classificação personalizada, é uma boa prática utilizar uma convenção de espaço de nomes (por exemplo, <nome> da empresa.<unidade> de negócio.<nome> da classificação personalizada).
Por exemplo, para a classificação de EMPLOYEE_ID personalizada para a empresa fictícia Contoso, o nome da sua classificação personalizada seria CONTOSO.HR. EMPLOYEE_ID e o nome amigável é armazenado no sistema como RH. ID DO FUNCIONÁRIO.

Quando criar e configurar as regras de classificação para uma classificação personalizada, faça o seguinte:
Selecione o nome de classificação adequado para o qual a regra de classificação vai ser criada.
O Mapa de Dados do Microsoft Purview suporta os dois métodos seguintes para criar regras de classificação personalizadas:
Utilize o método Expressão regular (regex) se conseguir expressar consistentemente o elemento de dados através de um padrão de expressão regular ou pode gerar o padrão com um ficheiro de dados. Certifique-se de que os dados de exemplo refletem a população.
Utilize o método Dicionário apenas se a lista de valores no ficheiro de dicionário representar todos os valores possíveis de dados a serem classificados e se espera que esteja em conformidade com um determinado conjunto de dados (considerando também valores futuros).
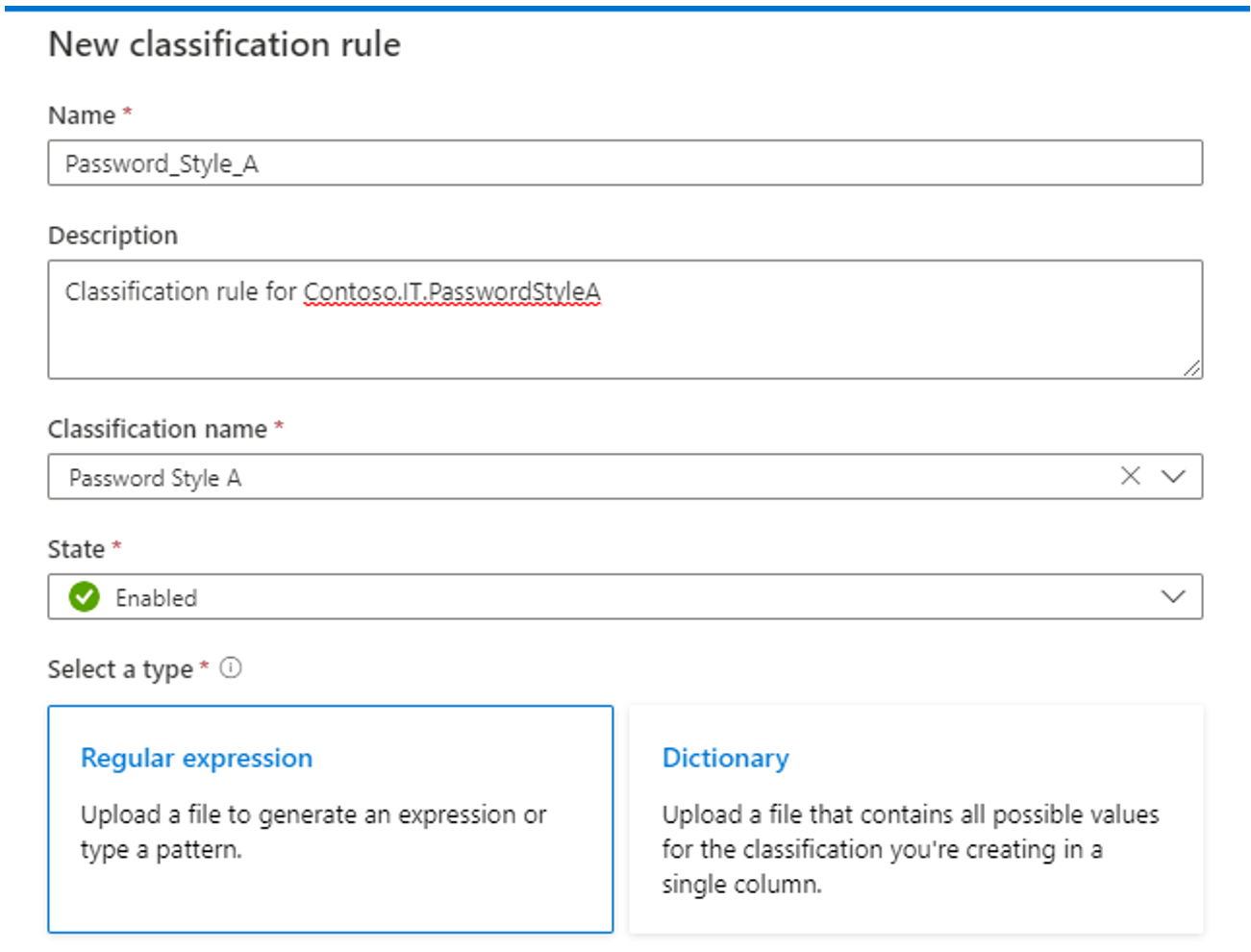
Utilizar o método de expressão Regular :
Configure o padrão regex para que os dados sejam classificados. Certifique-se de que o padrão regex é genérico o suficiente para atender aos dados que estão a ser classificados.
O Microsoft Purview também fornece uma funcionalidade para gerar um padrão regex sugerido. Depois de carregar um ficheiro de dados de exemplo, selecione um dos padrões sugeridos e, em seguida, selecione Adicionar aos padrões para utilizar os padrões de dados e coluna sugeridos. Pode modificar os padrões sugeridos ou escrever os seus próprios padrões sem ter de carregar um ficheiro.
Também pode configurar o padrão de nome da coluna para que a coluna seja classificada para minimizar os falsos positivos.
Configure o parâmetro Limiar de correspondência mínimo aceitável para os dados que correspondem ao padrão de dados para aplicar a classificação. Os valores de limiar podem ser de 1% a 100%. Sugerimos um valor de, pelo menos, 60% como limiar para evitar falsos positivos. No entanto, pode configurar conforme necessário para os seus cenários de classificação específicos. Por exemplo, o limiar pode ser tão baixo como 1% se quiser detetar e aplicar uma classificação para qualquer valor nos dados se corresponder ao padrão.

A opção para definir uma regra de correspondência mínima é automaticamente desativada se for adicionado mais do que um padrão de dados à regra de classificação.
Utilize a regra de classificação de teste e teste com dados de exemplo para verificar se a regra de classificação está a funcionar conforme esperado. Certifique-se de que, nos dados de exemplo (por exemplo, num ficheiro de .csv), existem pelo menos três colunas, incluindo a coluna na qual a classificação deve ser aplicada. Se o teste for bem-sucedido, deverá ver a etiqueta de classificação na coluna, conforme mostrado na imagem seguinte:

Utilizar o método dicionário :
Pode utilizar o método Dicionário para se ajustar aos dados de enumeração ou se a lista de dicionários de valores possíveis estiver disponível.
Este método suporta ficheiros .csv e .tsv, com um limite de tamanho de ficheiro de 30 megabytes (MB).



Arquétipos de classificação personalizados
Como funciona o parâmetro "limiar" na expressão regular
Considere os dados de origem de exemplo na imagem seguinte. Existem cinco colunas e a regra de classificação personalizada deve ser aplicada às colunas Sample_col1, Sample_col2 e Sample_col3 para o padrão de dados N{Digit}{Digit}{Digit}AN.

A classificação personalizada chama-se NDDDAN.
A regra de classificação (regex para o padrão de dados) é ^N[0-9]{3}AN$.
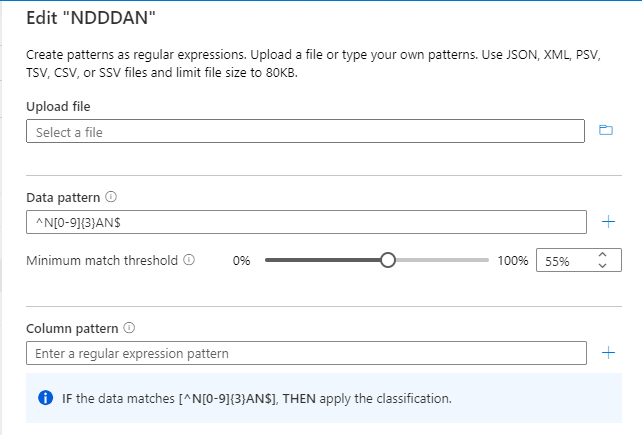
O limiar seria calculado para o padrão "^N[0-9]{3}AN$", conforme mostrado na imagem seguinte:

Se tiver um limiar de 55%, apenas as colunas Sample_col1 e Sample_col2 serão classificadas. Sample_col3 não será classificada, porque não cumpre o critério de limiar de 55%.





Como utilizar padrões de dados e colunas
Para os dados de exemplo indicados, em que a coluna B e a coluna C têm padrões de dados semelhantes, pode classificar na coluna B com base no padrão de dados "^P[0-9]{3}[A-Z]{2}$".

Utilize o padrão de coluna juntamente com o padrão de dados para garantir que apenas a coluna ID do Produto é classificada.

Observação
O padrão de coluna é verificado como uma condição E com o padrão de dados.
Utilize a regra de classificação de teste e teste com dados de exemplo para verificar se a regra de classificação está a funcionar conforme esperado.
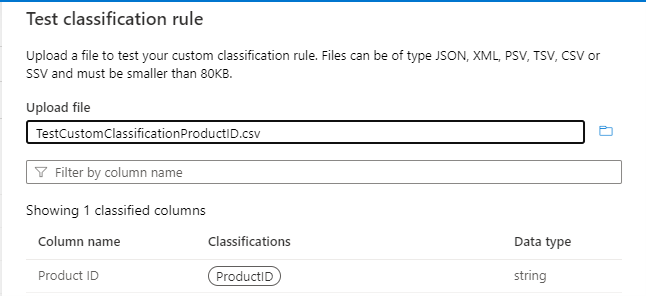



Como utilizar múltiplos padrões de coluna
Se existirem vários padrões de coluna a serem classificados para a mesma regra de classificação, utilize nomes de colunas separadas por carateres (|). Por exemplo, para as colunas ID do Produto, Product_ID, IDDoProduto, etc., escreva o padrão de coluna conforme mostrado na imagem seguinte:

Para obter mais informações, veja regex alternation construct (Construção alternada regex).
Considerações de classificação
Seguem-se algumas considerações a ter em conta, uma vez que está a definir classificações:
Para decidir que classificações são necessárias para serem aplicadas aos recursos antes da análise, considere a forma como as classificações devem ser utilizadas. As etiquetas de classificação desnecessárias podem parecer ruidosas e até enganosas para os consumidores de dados. Pode utilizar classificações para:
- Descreva a natureza dos dados que existem no recurso de dados ou no esquema que está a ser analisado. Por outras palavras, as classificações devem permitir que os clientes identifiquem o conteúdo do recurso de dados ou do esquema a partir das etiquetas de classificação à medida que pesquisam no catálogo.
- Defina prioridades e desenvolva um plano para alcançar as necessidades de segurança e conformidade de uma organização.
- Descreva as fases nos processos de preparação de dados (zona não processada, zona de destino, etc.) e atribua as classificações a recursos específicos para marcar a fase no processo.
Pode atribuir classificações ao nível do recurso ou coluna automaticamente ao incluir classificações relevantes na regra de análise ou pode atribuí-las manualmente depois de ingerir os metadados no Mapa de Dados do Microsoft Purview.
Para atribuição automática, veja arquivos de dados suportados para o Mapa de Dados do Microsoft Purview.
Antes de analisar as origens de dados no Mapa de Dados do Microsoft Purview, é importante compreender os seus dados e configurar o conjunto de regras de análise adequado para os mesmos (por exemplo, ao selecionar classificações do sistema relevantes, classificações personalizadas ou uma combinação de ambos), uma vez que pode afetar o desempenho da análise. Para obter mais informações, veja classificações suportadas no Mapa de Dados do Microsoft Purview.
O analisador do Microsoft Purview aplica regras de amostragem de dados para análises profundas (sujeitas a classificação) para classificações personalizadas e de sistema. A regra de amostragem baseia-se no tipo de origens de dados. Para obter mais informações, consulte a secção "Amostragem num ficheiro" em Origens de dados e tipos de ficheiro suportados no Microsoft Purview.
Observação
Limiar de dados distintos: este é o número total de valores de dados distintos que têm de ser encontrados numa coluna antes de o scanner executar o padrão de dados na mesma. O limiar de dados distintos não tem nada a ver com a correspondência de padrões, mas é um pré-requisito para a correspondência de padrões. As regras de classificação do sistema exigem que existam, pelo menos, 8 valores distintos em cada coluna para os sujeitar à classificação. O sistema requer este valor para garantir que a coluna contém dados suficientes para o scanner o classificar com precisão. Por exemplo, uma coluna que contenha várias linhas que contenham o valor 1 não será classificada. As colunas que contêm uma linha com um valor e o resto das linhas têm valores nulos também não serão classificadas. Se especificar múltiplos padrões, este valor aplica-se a cada um deles.
As regras de amostragem também se aplicam aos conjuntos de recursos. Para obter mais informações, veja a secção "Amostragem de ficheiros do conjunto de recursos" em origens de dados e tipos de ficheiro suportados no Mapa de Dados do Microsoft Purview.
As classificações personalizadas não podem ser aplicadas em recursos de tipo de documento com regras de classificação personalizadas. As classificações para estes tipos só podem ser aplicadas manualmente.
As classificações personalizadas não estão incluídas em nenhuma regra de análise predefinida. Por conseguinte, se for esperada a atribuição automática de classificações personalizadas, tem de implementar e utilizar uma regra de análise personalizada que inclua a classificação personalizada para executar a análise.
Se aplicar classificações manualmente a partir do portal de governação do Microsoft Purview, essas classificações serão mantidas em análises subsequentes.
As análises subsequentes não removerão quaisquer classificações de recursos, se tiverem sido detetadas anteriormente, mesmo que as regras de classificação sejam inaplicáveis.
Para recursos de dados de origem encriptados , o Microsoft Purview escolhe apenas nomes de ficheiros, nomes completamente qualificados, detalhes de esquema para tipos de ficheiro estruturados e tabelas de bases de dados. Para que a classificação funcione, desencripte os dados encriptados antes de executar as análises.