Múltiplas GPUs e Máquinas
1. Introdução
A CNTK suporta atualmente quatro algoritmos paralelos da SGD:
Pré-requisitos
Para realizar uma formação paralela, certifique-se de que está instalada uma implementação da Interface de Passagem de Mensagens (MPI):
No Windows, instale a versão 7 (7.0.12437.6) do Microsoft MPI (MS-MPI), uma implementação microsoft da norma Interface de Passagem de Mensagens, a partir desta página de descarregamento, marcada simplesmente como "Versão 7" no título da página. Clique no botão Descarregar e, em seguida, selecione o tempo de execução (
MSMpiSetup.exe).No Linux, instale a versão 1.10.x do OpenMPI. Por favor, siga as instruções aqui para construí-lo por si mesmo.
2. Configuração da Formação Paralela na CNTK em Python
Para utilizar a SGD paralela de dados em Python, o utilizador precisa de criar e passar um aprendiz distribuído ao treinador:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Para o ciclo de formação definido pelo utilizador (em num_data_partitions vez de training_session), os utilizadores precisam de passar e partition_index método para MinibatchSource.next_minibatch() que diferentes nóns de MPI leiam dados de diferentes divisórias de dados (após distributed_after a leitura das amostras).
Por favor, note que isso Communicator.finalize() deve ser chamado apenas no caso de o treino distribuído terminar com sucesso. No caso de um trabalhador distribuído falhar, este método não deve ser chamado.
Para um exemplo totalmente funcional, consulte o exemplo convNet.
3. Configurar o Treino Paralelo em CNTK no BrainScript
Para permitir uma formação paralela no CNTK BrainScript, é necessário ligar o seguinte interruptor no ficheiro de configuração ou na linha de comando:
parallelTrain = true
Em segundo lugar, o SGD bloco no ficheiro config deve conter um sub-bloco nomeado ParallelTrain com os seguintes argumentos:
parallelizationMethod: (obrigatório) valores legítimos sãoDataParallelSGD,BlockMomentumSGDeModelAveragingSGD.Isto especifica qual o algoritmo paralelo a ser usado.
distributedMBReading: (opcional) aceita o valor booleano:trueoufalse; o padrão éfalseRecomenda-se que ligue a leitura de minibatch distribuída para minimizar o custo de E/S em cada trabalhador. Se estiver a utilizar o leitor de formato de texto CNTK, leitor de imagens ou leitor de dados compostos, oMBReading distribuído deve ser definido como verdadeiro.
parallelizationStartEpoch: (opcional) aceita valor inteiro; padrão é 1.Isto especifica a partir da época, são utilizados algoritmos de treino paralelos; antes disso, todos os trabalhadores que fazem a mesma formação, mas apenas um trabalhador pode salvar o modelo. Esta opção pode ser útil se o treino paralelo necessitar de alguma fase de "warm-start".
syncPerfStats: (opcional) aceita valor inteiro; padrão é 0.Isto especifica a frequência com que as estatísticas de desempenho serão impressas. Estas estatísticas incluem o tempo gasto em comunicação e/ou computação num período de sincronização, o que pode ser útil para entender o estrangulamento de algoritmos de treino paralelos.
0 significa que não serão publicadas estatísticas. Outros valores especificam a frequência com que as estatísticas serão impressas. Por exemplo,
syncPerfStats=5significa que as estatísticas serão impressas após cada 5 sincronizações.Um sub-bloco que especifica detalhes de cada algoritmo de treino paralelo. O nome do sub-bloco deve ser igual a
parallelizationMethod. (obrigatório)
Python proporciona mais flexibilidade e os usos são mostrados abaixo para diferentes métodos de paralelização.
4. Formação paralela em execução com a CNTK
A paralelização na CNTK é implementada com MPI.
4.1 Curso paralelo com BrainScript
Tendo em conta qualquer uma das configurações BrainScript de treino paralelo acima, os seguintes comandos podem ser usados para iniciar um trabalho de MPI paralelo:
Treino paralelo na mesma máquina com Linux:
mpiexec --npernode $num_workers $cntk configFile=$configTreino paralelo na mesma máquina com Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Treino paralelo em vários nosdes de computação com Linux:
Passo 1: Crie um ficheiro de anfitrião $hostfile usando o seu editor favorito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Quando name_of_node(n) é simplesmente um nome DNS ou endereço IP do nó do trabalhador.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Treinamento paralelo em vários nosdes de computação com Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
onde $cntk deve referir-se ao caminho do executável CNTK ($x é a forma da concha Linux de substituir variáveis ambientais, o equivalente à concha do %x% Windows).
4.2 Curso Paralelo com Python
Exemplos para formação distribuída para CNTK v2 com Python podem ser consultados aqui:
Dado um script training.py CNTK v2 Python, os seguintes comandos podem ser usados para iniciar um trabalho de MPI paralelo:
Treino paralelo na mesma máquina com Linux:
mpiexec --npernode $num_workers python training.pyTreino paralelo na mesma máquina com Windows:
mpiexec -n %num_workers% python training.pyTreino paralelo em vários nosdes de computação com Linux:
Passo 1: Crie um ficheiro de anfitrião $hostfile usando o seu editor favorito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Quando name_of_node(n) é simplesmente um nome DNS ou endereço IP do nó do trabalhador.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Treinamento paralelo em vários nosdes de computação com Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel Treino com SGD de 1 bit
A CNTK implementa a técnica SGD de 1 bit [1]. Esta técnica permite distribuir cada minibatch sobre K os trabalhadores. Os gradientes parciais resultantes são então trocados e agregados após cada minibatch. "1 bit" refere-se a uma técnica desenvolvida na Microsoft para reduzir a quantidade de dados que é trocada por cada valor de gradiente para um único bit.
5.1 O algoritmo "SGD de 1 bit"
A troca direta de gradientes parciais após cada minibatch requer largura de banda de comunicação proibitiva. Para resolver isto, a SGD de 1 bit quantifica agressivamente cada valor de gradiente... a um único bit (!) por valor. Na prática, isto significa que os grandes valores de gradiente são cortados, enquanto os pequenos valores são artificialmente insuflados. Surpreendentemente, isto não prejudica a convergência se, e somente se, um truque for usado.
O truque é que para cada minibatch, o algoritmo compara os gradientes quantizados (que são trocados entre trabalhadores) com os valores de gradiente original (que deveriam ser trocados). A diferença entre os dois (o erro de quantificação) é calculada e lembrada como o residual. Este residual é então adicionado à próxima minibatch.
Como consequência, apesar da quantificação agressiva, cada valor de gradiente é eventualmente trocado com toda a precisão; apenas com um atraso. As experiências mostram que, desde que este modelo seja combinado com um início quente (um modelo de sementes treinado num pequeno subconjunto dos dados de treino sem paralelização), esta técnica demonstrou conduzir a uma perda de precisão ou muito pequena, ao mesmo tempo que permite uma aceleração não muito longe do linear (o fator limitativo é que as GPUs se tornam ineficientes ao calcular em sub-lotes demasiado pequenos).
Para uma eficiência máxima, a técnica deve ser combinada com a escala automática de minibatch, onde de vez em quando, o treinador tenta aumentar o tamanho da minibatch. Avaliando num pequeno subconjunto da próxima época de dados, o formador irá selecionar o maior tamanho de minibatch que não prejudica a convergência. Aqui, é útil que a CNTK especifique a taxa de aprendizagem e os hiperparmetros de impulso de uma forma agnóstica em tamanho minibatch.
5.2 Usando SGD de 1 bit no BrainScript
O SGD de 1 bit não tem outro parâmetro que não seja a sua ativação e, após a qual, deve começar a época. Além disso, deve ser ativado o escalonamento automático de minibatch. Estes são configurados adicionando os seguintes parâmetros ao bloco SGD:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Note que Data-Parallel SGD também pode ser usado sem quantificar 1 bit. No entanto, em cenários típicos, especialmente cenários em que cada parâmetro de modelo é aplicado apenas uma vez como para um DNN feed-forward, este não será eficiente devido às elevadas necessidades de largura de banda de comunicação.
A secção 2.2.3 abaixo apresenta resultados de 1 bit SGD numa tarefa de fala, comparando com o método SGD Block-Momentum descrito em seguida. Ambos os métodos não têm ou quase nenhuma perda de precisão à velocidade quase linear.
5.3 Utilização de SGD de 1 bit em Python
Para utilizar o SGD paralelo de dados em Python, opcionalmente com SGD de 1 bit, o utilizador precisa de criar e passar um aprendiz distribuído ao treinador:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Mudar num_quantization_bits para 32 durante a criação de distributed_learner faz com que utilize Data-Parallel SGD não quantificar. Não há necessidade de um começo quente neste caso.
6 Block-Momentum SGD
Block-Momentum SGD é a implementação da "atualização e filtragem do modelo de bloqueio", ou BMUF, algoritmo, Short Block Momentum [2].
6.1 O Block-Momentum algoritmo SGD
A figura a seguir resume o procedimento no algoritmo Block-Momentum.

6.2 Configuração Block-Momentum SGD no BrainScript
Para utilizar Block-Momentum SGD, é necessário ter um sub-bloco nomeado BlockMomentumSGD no SGD bloco com as seguintes opções:
syncPeriod. Isto é semelhante ao inModelAveragingSGD, que especifica asyncPeriodfrequência com que uma sincronização de modelo é realizada. O valorBlockMomentumSGDpredefinido é de 120.000.resetSGDMomentum. Isto significa que após cada ponto de sincronização, o gradiente liso utilizado na SGD local será definido como 0. O valor padrão desta variável é verdadeiro.useNesterovMomentum. Isto significa que a atualização de impulso ao estilo Nesterov é aplicada no nível do bloco. Consulte [2] para mais detalhes. O valor padrão desta variável é verdadeiro.
A dinâmica do bloco e a taxa de aprendizagem em bloco são geralmente definidas automaticamente de acordo com o número de trabalhadores utilizados, ou seja,
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
A nossa experiência indica que estas configurações muitas vezes produzem uma convergência semelhante à do algoritmo SGD padrão até 64 GPUs, que é a maior experiência que fizemos. Também é possível especificar manualmente estes parâmetros utilizando as seguintes opções:
blockMomentumAsTimeConstantespecifica a constante de tempo do filtro de baixa passagem na atualização do modelo de nível de bloco. É calculado como:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateespecifica a taxa de aprendizagem por bloco.
Segue-se um exemplo da secção de configuração SGD Block-Momentum:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Utilização de Block-Momentum SGD no BrainScript
1. Reafinar os parâmetros de aprendizagem
Para obter uma produção semelhante por trabalhador, é necessário aumentar o número de amostras numa minibatch proporcional ao número de trabalhadores. Isto pode ser conseguido ajustando
minibatchSizeounbruttsineachrecurrentiter, dependendo se a aleatoriedade do modo de quadro é usada.Não há necessidade de ajustar a taxa de aprendizagem (ao contrário Model-Averaging SGD, ver abaixo).
Recomenda-se a utilização de Block-Momentum SGD com um modelo de início quente. Nas nossas tarefas de reconhecimento de voz, é alcançada uma convergência razoável quando partimos de modelos de sementes treinados em 24 horas (8,6 milhões de amostras) para 120 horas (43,2 milhões de amostras) dados utilizando dados padrão da SGD.
2. Experiências ASR
Utilizamos os Block-Momentum SGD e os algoritmos SGD de Data-Parallel (1 bit) para treinar DNNs e LSTMs numa tarefa de reconhecimento de voz de 2600 horas, e comparámos precisões de reconhecimento de palavras vs. fatores de aceleração. As tabelas e números seguintes mostram os resultados (*).
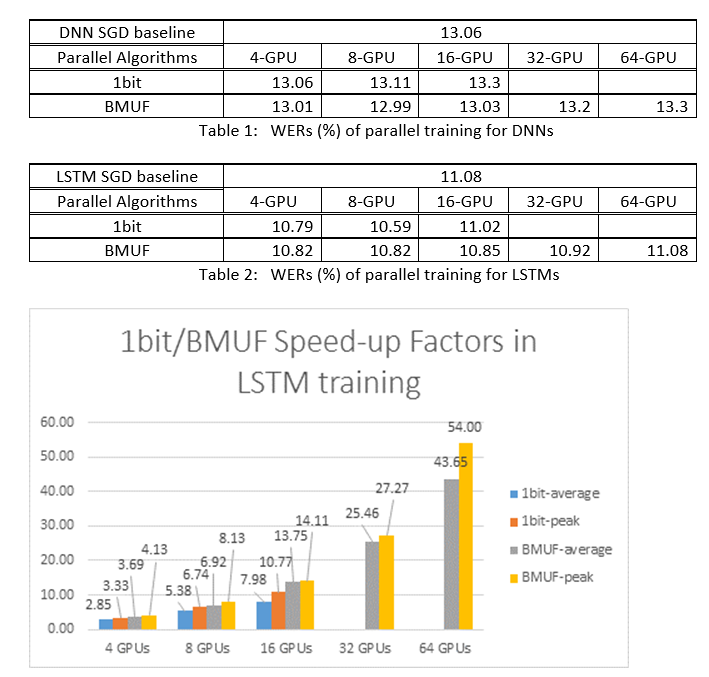
(*): Fator de aceleração máxima: para ODS de 1 bit, medido pelo fator de aceleração máxima (em comparação com a linha de base SGD) alcançado numa minibatch; para o Block Momentum, medido pela velocidade máxima alcançada num bloco; Fator de aceleração médio: o tempo decorrido na linha de base da SGD dividido pelo tempo decorrido. Estas duas métricas são introduzidas devido à latência em E/O pode afetar muito a medição média do fator de aceleração, especialmente quando a sincronização é realizada ao nível do mini-lote. Ao mesmo tempo, o fator de aceleração máxima é relativamente robusto.
3. Ressalvas
Recomenda-se definir
resetSGDMomentuma verdade; caso contrário, conduz frequentemente à divergência do critério de treino. Repor o ímpeto SGD para 0 após a sincronização de cada modelo essencialmente corta a contribuição dos últimos minibatches. Portanto, recomenda-se não utilizar um grande impulso SGD. Por exemplo, para umsyncPeriodde 120.000, observamos uma perda significativa de precisão se o ímpeto usado para ADS for de 0,99. Reduzir o ímpeto SGD para 0,9, 0,5 ou mesmo desativá-lo completamente dá precisões semelhantes às que se pode alcançar pelo algoritmo SGD padrão.Block-Momentum atrasos SGD e distribui atualizações de modelos de um bloco através de blocos subsequentes. Por isso, é necessário garantir que as sincronizações do modelo são realizadas com frequência suficiente no treino. Uma verificação rápida é para usar
blockMomentumAsTimeConstant. Recomenda-se que o número de amostras de formação únicasNsatisfaça a seguinte equação:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
A aproximação decorre dos seguintes factos: (1) O Momentum do Bloco é frequentemente definido como (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Utilização de Block-Momentum em Python
Para permitir Block-Momentum em Python, à semelhança do SGD de 1 bit, o utilizador precisa de criar e passar um aluno distribuído por um bloco para o treinador:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Para um exemplo totalmente funcional, consulte o exemplo convNet.
7 Model-Averaging SGD
Model-Média SGD é uma implementação do algoritmo de média do modelo detalhado em [3,4] sem o uso de gradiente natural. A ideia aqui é permitir que cada trabalhador processe um subconjunto de dados, mas em média os parâmetros do modelo de cada trabalhador após um período especificado.
Model-Averaging SGD geralmente converge mais lentamente e para um melhor ideal, em comparação com SGD de 1 bit e Block-Momentum SGD, pelo que já não é recomendado.
Para utilizar Model-Averaging SGD, é necessário ter um sub-bloco nomeado ModelAveragingSGD no SGD bloco com as seguintes opções:
syncPeriodespecifica o número de amostras que cada trabalhador precisa de processar antes de ser conduzido um modelo de média. O valor predefinido é de 40.000.
7.1 Utilização de Model-Averaging SGD no BrainScript
Para tornar Model-Averaging SGD maximicamente eficaz e eficiente, os utilizadores precisam de sintonizar alguns hiper-parâmetros:
minibatchSizeounbruttsineachrecurrentiter. Suponha quenos trabalhadores estão a participar na configuração Model-Averaging SGD, a atual implementação de leitura distribuída irá carregar1/n-th da minibatch em cada trabalhador. Por isso, para garantir que cada trabalhador produz a mesma produção que o SGD padrão, é necessário aumentar o tamanhonda minibatch -fold. Para modelos treinados com aleatoriedade em modo de fotograma, isso pode ser conseguido através do alargamentominibatchSizeporntempos; para os modelos são treinados usando aleatoriedade em modo sequência, como RNNs, alguns leitores exigem em vez disso aumentarnbruttsineachrecurrentiterporn.learningRatesPerSample. A nossa experiência indica que para obter uma convergência semelhante à do SGD padrão, é necessário aumentar oslearningRatesPerSampletempos pornvezes. Uma explicação pode ser encontrada em [2]. Uma vez que a taxa de aprendizagem é aumentada, é necessário um cuidado extra para garantir que a formação não diverge -- e esta é, de facto, a principal ressalva de Model-Averaging SGD. Pode utilizar asAutoAdjustdefinições para recarregar o melhor modelo anterior se for observado um aumento do critério de treino.início quente. Constata-se que Model-Averaging SGD geralmente converge melhor se for iniciado a partir de um modelo de sementes que é treinado pelo algoritmo SGD padrão (sem paralelização). Nas nossas tarefas de reconhecimento de voz, é alcançada uma convergência razoável quando partimos de modelos de sementes treinados em 24 horas (8,6 milhões de amostras) para 120 horas (43,2 milhões de amostras) dados utilizando dados padrão da SGD.
Segue-se um exemplo da secção de ModelAveragingSGD configuração:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Utilização de Model-Averaging SGD em Python
Este é um trabalho em curso.
8 Data-Parallel Treino com Servidor de Parâmetros
O servidor de parâmetros é uma estrutura amplamente utilizada na aprendizagem automática distribuída [5][6][7]. O benefício mais importante que traz é a formação paralela assíncronea com muitos trabalhadores. Introduz o servidor de parâmetros como uma loja de modelos distribuída. Em vez de aproveitar diretamente os primitivos AllReduce para sincronizar atualizações de parâmetros entre os trabalhadores, a estrutura do servidor de parâmetros fornece aos utilizadores as interfaces como "Add" e "Get" para permitir que os trabalhadores locais atualizem e recuperem parâmetros globais a partir do servidor de parâmetros. Desta forma, os trabalhadores locais não precisam de esperar uns pelos outros durante o processo de formação, o que poupa muito tempo, especialmente quando o número de trabalhadores é grande.
Além disso, como os servidores de parâmetros são uma estrutura distribuída que armazenam parâmetros de modelo, os trabalhadores só podem recuperar os parâmetros de que necessitam durante o processo de treino do mini-lote, isso traz uma flexibilidade muito boa no método de formação distribuído por design e também aumenta a eficiência ao realizar a formação com atualizações de modelos escassos. Nesta versão, vamos focar-nos primeiro na formação paralela assíncronea, mais tarde daremos mais introdução sobre como alavancar a estrutura do servidor de parâmetros para uma formação de modelo eficiente com atualizações escassas.
8.1 Utilização de Data-Parallel ASGD
- Para utilizar servidores de parâmetros para o SGD Assíncronos (abbr. como ASGD), deve construir CNTK com suporte Multiverso , o Multiverso é uma estrutura geral do servidor de parâmetros para a tarefa de aprendizagem automática distribuída desenvolvida pela equipa da Microsoft Research Asia.
Clone Code: por favor clone o código sob a pasta raiz da CNTK utilizando:
git submodule update --init Source/Multiverso
Linux: por favor, construa com--asgd=yeso processo de configuração.Windows: por favor, adicioneCNTK_ENABLE_ASGDao ambiente do seu sistema e desemote o valortrue
- início quente. Em alguns casos, é melhor ter o treino de modelo assíncronos iniciado a partir de um modelo de sementes (que é treinado pelo algoritmo SGD padrão). Em certo sentido, a Asynchronous SGD traz mais ruído para a formação devido às atualizações atrasadas do assíncromo entre os trabalhadores. Alguns modelos são muito sensíveis a este ruído no início, o que pode resultar em divergências de formação de modelos. Nestas circunstâncias, é necessário um início caloroso .
8.2 Configuração Data-Parallel ASGD no BrainScript
Para utilizar Data-Parallel ASGD na CNTK, é necessário ter um sub-bloco DataParallelASGD no bloco SGD com as seguintes opções
-
syncPeriodPerWorkers. Especifica o número de amostras que cada trabalhador precisa de processar antes de comunicar com os servidores de parâmetros. O valor predefinido é de 256. É recomendado como tamanho de minibatch. É óbvio que a sincronização frequente levará a um custo significativo de comunicação. No nosso teste, não é necessário definir o valor para 1 na maioria dos casos.
-
usePipeline. Especifica se liga o gasoduto de recuperação de modelos e a computação local. Ligar o gasoduto aumentará significativamente a produção global da formação, uma vez que esconderá parte ou aumentá-la. No entanto, por vezes, pode abrandar a taxa de convergência, uma vez que será introduzido mais atraso através da adição de gasodutos. No geral, o tempo do relógio será guardado na maioria dos casos com o oleoduto.
-
AdjustLearningRateAtBeginning. De acordo com o artigo recentemente publicado [5], a formação asGD é menos estável, e exigiu a utilização de uma taxa de aprendizagem muito menor para evitar explosões ocasionais da perda de treino, pelo que o processo de aprendizagem torna-se menos eficiente. No entanto, constatamos que a utilização de uma taxa de aprendizagem mais baixa não é necessária para todas as tarefas. E para essas tarefas sensíveis no início, iniciamos a formação com uma pequena taxa de aprendizagem, e gradualmente alargamo-la na fase inicial do processo de formação até atingir a taxa de aprendizagem inicial utilizada na SGD normal. Desta forma, a precisão final corresponderá ao SGD enquanto com a velocidade do ASGD. Assim, fornecemos esta opção para os utilizadores asgd alavancarem este truque. É um sub-bloco em DataParallelASGD com dois parâmetros: ajustar o Coefficiente e ajustar oNBMiniBatch. A lógica é que a taxa de aprendizagem começa a partir do ajusteCoficiente da taxa de aprendizagem inicial SGD, e aumentando ajustandoCoficiente da taxa de aprendizagem inicial SGD cada mini-lotes de ajusteNBMiniBatch .
Segue-se um exemplo da secção de DataParallelASGD configuração:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Configuração Data-Parallel ASGD em Python
Este é um trabalho em curso.
8.4 Experiências
O seguinte número mostra as experiências para testar o ASGD com o conjunto de dados CIFAR-10. O modelo usado nesta experiência é um ResNet de 20 camadas. O algoritmo assíncronos reduz o custo de esperar por todos os nós dos trabalhadores. O ASGD, neste caso, é claramente mais rápido do que os algoritmos sincronizados, como o MA e o SSGD. *Nas experiências, todos os modos paralelos sincronizam os parâmetros de cada iteração (atualização de mini-lote). E para o SSGD, usamos atualizações de parâmetros de 32 bits. O algoritmo assíncronos ganha uma vantagem significativa em termos de produção de treino medido pela velocidade de processamento da amostra, especialmente quando o número do nó de trabalho sobe para 16.
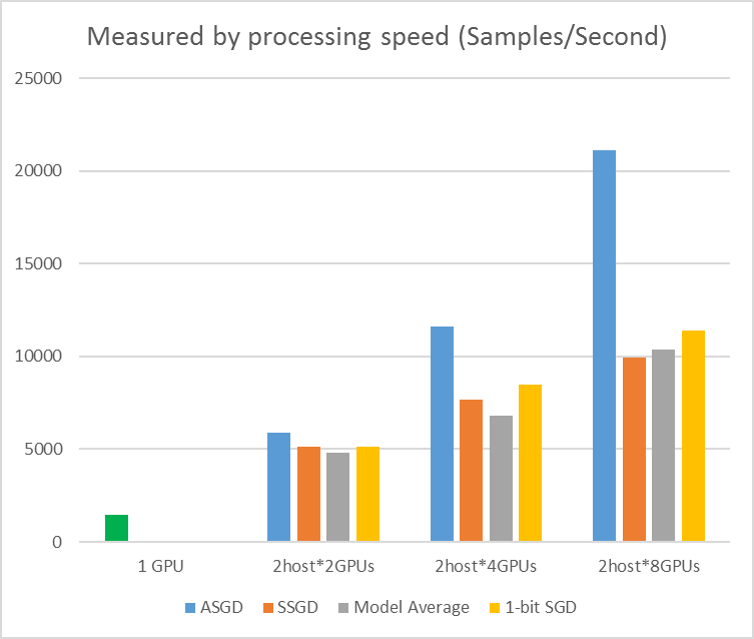 Figura 2.4 a aceleração para diferentes métodos de treino
Figura 2.4 a aceleração para diferentes métodos de treino
Referências
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li e Dong Yu, "descida de gradiente estocástico de 1 bit e sua aplicação à formação distribuída de dados-paralelos de DNNs da fala", em Proceedings of Interspeech, 2014.
[2] K. Chen e Q. Huo, "Treino escalável de máquinas de aprendizagem profunda através de treino de bloco incremental com otimização paralela intra-bloco e filtragem de atualização de modelos de bloqueio", em Proceedings of ICASSP, 2016.
[3] M. Zinkevich, M. Weimer, L. Li, e A. J. Smola, "Descida de gradiente estocástico paralelo", em Proceedings of Advances in NIPS, 2010, pp. 2595-2603.
[4] D. Povey, X. Zhang e S. Khudanpur, "Formação paralela de DNNs com gradiente natural e média de parâmetros", em Proceedings of the International Conference on Learning Representations, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Redes profundas distribuídas em larga escala. Em Avanços nos sistemas de processamento de informação neural, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen e Alexander Smola. "Servidor de parâmetros para aprendizagem de máquinas distribuídas." No Workshop BIG Learning NIPS, vol. 6, p. 2. 2013.