Guia para a linguagem de especificação de rede neural Net# para o Machine Learning Studio (clássico)
APLICA-SE A:  Machine Learning Studio (clássico)
Machine Learning Studio (clássico)  Azure Machine Learning
Azure Machine Learning
Importante
O suporte para o Estúdio de ML (clássico) terminará a 31 de agosto de 2024. Recomendamos a transição para o Azure Machine Learning até essa data.
A partir de 1 de dezembro de 2021, não poderá criar novos recursos do Estúdio de ML (clássico). Até 31 de agosto de 2024, pode continuar a utilizar os recursos existentes do Estúdio de ML (clássico).
- Consulte informações sobre como mover projetos de aprendizado de máquina do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning
A documentação do Estúdio de ML (clássico) está a ser descontinuada e poderá não ser atualizada no futuro.
Net# é uma linguagem desenvolvida pela Microsoft que é usada para definir arquiteturas de redes neurais complexas, como redes neurais profundas ou convoluções de dimensões arbitrárias. Você pode usar estruturas complexas para melhorar o aprendizado em dados como imagem, vídeo ou áudio.
Você pode usar uma especificação de arquitetura Net# em todos os módulos de rede neural no Machine Learning Studio (clássico):
Este artigo descreve os conceitos básicos e a sintaxe necessária para desenvolver uma rede neural personalizada usando Net#:
- Requisitos de rede neural e como definir os componentes primários
- A sintaxe e as palavras-chave da linguagem de especificação Net#
- Exemplos de redes neurais personalizadas criadas usando Net#
Noções básicas de redes neurais
Uma estrutura de rede neural consiste em nós que são organizados em camadas e conexões ponderadas (ou arestas) entre os nós. As conexões são direcionais e cada conexão tem um nó de origem e um nó de destino.
Cada camada treinável (uma camada oculta ou uma camada de saída) tem um ou mais pacotes de conexão. Um pacote de conexão consiste em uma camada de origem e uma especificação das conexões dessa camada de origem. Todas as conexões em um determinado pacote compartilham as camadas de origem e destino. Em Net#, um pacote de conexão é considerado como pertencente à camada de destino do pacote.
O Net# suporta vários tipos de pacotes de conexão, que permitem personalizar a maneira como as entradas são mapeadas para camadas ocultas e mapeadas para as saídas.
O pacote padrão ou padrão é um pacote completo, no qual cada nó na camada de origem é conectado a cada nó na camada de destino.
Além disso, Net# suporta os seguintes quatro tipos de pacotes de conexão avançada:
Pacotes filtrados. Você pode definir um predicado usando os locais do nó da camada de origem e do nó da camada de destino. Os nós são conectados sempre que o predicado é True.
Feixes convolucionais. Você pode definir pequenas vizinhanças de nós na camada de origem. Cada nó na camada de destino é conectado a uma vizinhança de nós na camada de origem.
Agrupando pacotes e pacotes de normalização de resposta. Estes são semelhantes aos bundles convolucionais em que o usuário define pequenas vizinhanças de nós na camada de origem. A diferença é que os pesos das arestas nesses feixes não são treináveis. Em vez disso, uma função predefinida é aplicada aos valores do nó de origem para determinar o valor do nó de destino.
Personalizações suportadas
A arquitetura de modelos de rede neural que você cria no Machine Learning Studio (clássico) pode ser amplamente personalizada usando Net#. Pode:
- Crie camadas ocultas e controle o número de nós em cada camada.
- Especifique como as camadas devem ser conectadas umas às outras.
- Defina estruturas de conectividade especiais, como convoluções e pacotes de compartilhamento de peso.
- Especifique diferentes funções de ativação.
Para obter detalhes da sintaxe da linguagem de especificação, consulte Especificação da estrutura.
Para obter exemplos de definição de redes neurais para algumas tarefas comuns de aprendizado de máquina, de simplex a complexas, consulte Exemplos.
Requisitos gerais
- Deve haver exatamente uma camada de saída, pelo menos uma camada de entrada e zero ou mais camadas ocultas.
- Cada camada tem um número fixo de nós, conceitualmente dispostos em uma matriz retangular de dimensões arbitrárias.
- As camadas de entrada não têm parâmetros treinados associados e representam o ponto onde os dados da instância entram na rede.
- As camadas treináveis (as camadas oculta e de saída) têm parâmetros treinados associados, conhecidos como pesos e vieses.
- Os nós de origem e de destino devem estar em camadas separadas.
- As conexões devem ser acíclicas; Em outras palavras, não pode haver uma cadeia de conexões que levem de volta ao nó de origem inicial.
- A camada de saída não pode ser uma camada de origem de um pacote de conexão.
Especificações da estrutura
Uma especificação de estrutura de rede neural é composta de três seções: a declaração constante, a declaração de camada, a declaração de conexão. Existe também uma secção de declaração de ações facultativa. As seções podem ser especificadas em qualquer ordem.
Declaração constante
Uma declaração constante é opcional. Ele fornece um meio para definir valores usados em outro lugar na definição de rede neural. A instrução de declaração consiste em um identificador seguido por um sinal de igual e uma expressão de valor.
Por exemplo, a instrução a seguir define uma constante x:
Const X = 28;
Para definir duas ou mais constantes simultaneamente, coloque os nomes e valores dos identificadores em chaves e separe-os usando ponto-e-vírgula. Por exemplo:
Const { X = 28; Y = 4; }
O lado direito de cada expressão de atribuição pode ser um número inteiro, um número real, um valor booleano (Verdadeiro ou Falso) ou uma expressão matemática. Por exemplo:
Const { X = 17 * 2; Y = true; }
Declaração de camada
A declaração de camada é necessária. Ele define o tamanho e a origem da camada, incluindo seus pacotes de conexão e atributos. A instrução de declaração começa com o nome da camada (entrada, oculta ou saída), seguido pelas dimensões da camada (uma tupla de inteiros positivos). Por exemplo:
input Data auto;
hidden Hidden[5,20] from Data all;
output Result[2] from Hidden all;
- O produto das dimensões é o número de nós na camada. Neste exemplo, há duas dimensões [5,20], o que significa que há 100 nós na camada.
- As camadas podem ser declaradas em qualquer ordem, com uma exceção: se mais de uma camada de entrada for definida, a ordem em que elas são declaradas deve corresponder à ordem dos recursos nos dados de entrada.
Para especificar que o número de nós em uma camada seja determinado automaticamente, use a auto palavra-chave. A auto palavra-chave tem efeitos diferentes, dependendo da camada:
- Em uma declaração de camada de entrada, o número de nós é o número de recursos nos dados de entrada.
- Em uma declaração de camada oculta, o número de nós é o número especificado pelo valor do parâmetro Number of hidden nodes.
- Em uma declaração de camada de saída, o número de nós é 2 para classificação de duas classes, 1 para regressão e igual ao número de nós de saída para classificação de várias classes.
Por exemplo, a seguinte definição de rede permite que o tamanho de todas as camadas seja determinado automaticamente:
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
Uma declaração de camada para uma camada treinável (as camadas ocultas ou de saída) pode opcionalmente incluir a função de saída (também chamada de função de ativação), que assume como padrão sigmoide para modelos de classificação e linear para modelos de regressão. Mesmo se você usar o padrão, você pode declarar explicitamente a função de ativação, se desejado para clareza.
As seguintes funções de saída são suportadas:
- sigmoide
- Linear
- SoftMax
- rlinear
- quadrado
- SQRT
- srlinear
- ABS
- Tanh
- Brlinear
Por exemplo, a seguinte declaração usa a função softmax :
output Result [100] softmax from Hidden all;
Declaração de ligação
Imediatamente após definir a camada treinável, você deve declarar conexões entre as camadas que você definiu. A declaração do pacote de conexão começa com a palavra-chave from, seguida pelo nome da camada de origem do pacote e o tipo de pacote de conexão a ser criado.
Atualmente, cinco tipos de pacotes de conexão são suportados:
- Pacotes completos , indicados pela palavra-chave
all - Pacotes filtrados , indicados pela palavra-chave
where, seguidos por uma expressão de predicado - Bundles convolucionais , indicados pela palavra-chave
convolve, seguidos pelos atributos de convolução - Pooling bundles, indicados pelas palavras-chave max pool ou mean pool
- Pacotes de normalização de resposta, indicados pela norma de resposta de palavra-chave
Pacotes completos
Um pacote de conexão completo inclui uma conexão de cada nó na camada de origem para cada nó na camada de destino. Este é o tipo de conexão de rede padrão.
Pacotes filtrados
Uma especificação de pacote de conexão filtrada inclui um predicado, expresso sintaticamente, muito parecido com uma expressão lambda em C#. O exemplo a seguir define dois pacotes filtrados:
input Pixels [10, 20];
hidden ByRow[10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol[5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
No predicado para
ByRow,sé um parâmetro que representa um índice na matriz retangular de nós da camada de entrada,Pixelsedé um parâmetro que representa um índice na matriz de nós da camada oculta,ByRow. O tipo de ambossedé uma tupla de inteiros de comprimento dois. Conceitualmente,svaria em todos os pares de inteiros com0 <= s[0] < 10e0 <= s[1] < 20, edvaria em todos os pares de inteiros, com0 <= d[0] < 10e0 <= d[1] < 12.No lado direito da expressão do predicado, há uma condição. Neste exemplo, para cada valor de
sedtal que a condição é True, há uma borda do nó da camada de origem para o nó da camada de destino. Assim, essa expressão de filtro indica que o bundle inclui uma conexão do nó definido porspara o nó definido pordem todos os casos em que s[0] é igual a d[0].
Opcionalmente, você pode especificar um conjunto de pesos para um pacote filtrado. O valor para o atributo Weights deve ser uma tupla de valores de ponto flutuante com um comprimento que corresponda ao número de conexões definidas pelo pacote. Por padrão, os pesos são gerados aleatoriamente.
Os valores de peso são agrupados pelo índice do nó de destino. Ou seja, se o primeiro nó de destino estiver conectado aos nós de origem K, os primeiros K elementos da tupla Weights serão os pesos para o primeiro nó de destino, na ordem do índice de origem. O mesmo se aplica aos nós de destino restantes.
É possível especificar pesos diretamente como valores constantes. Por exemplo, se você aprendeu os pesos anteriormente, pode especificá-los como constantes usando esta sintaxe:
const Weights_1 = [0.0188045055, 0.130500451, ...]
Feixes convolucionais
Quando os dados de treinamento têm uma estrutura homogênea, conexões convolucionais são comumente usadas para aprender recursos de alto nível dos dados. Por exemplo, em dados de imagem, áudio ou vídeo, a dimensionalidade espacial ou temporal pode ser bastante uniforme.
Os feixes convolucionais empregam núcleos retangulares que são deslizados através das dimensões. Essencialmente, cada kernel define um conjunto de pesos aplicados em bairros locais, referidos como aplicativos kernel. Cada aplicação do kernel corresponde a um nó na camada de origem, que é referido como o nó central. Os pesos de um kernel são compartilhados entre muitas conexões. Em um bundle convolucional, cada kernel é retangular e todos os aplicativos do kernel são do mesmo tamanho.
Os pacotes convolucionais suportam os seguintes atributos:
InputShape define a dimensionalidade da camada de origem para os fins deste pacote convolucional. O valor deve ser uma tupla de inteiros positivos. O produto dos inteiros deve ser igual ao número de nós na camada de origem, mas, caso contrário, não precisa corresponder à dimensionalidade declarada para a camada de origem. O comprimento desta tupla torna-se o valor de aridade para o feixe convolucional. Normalmente, aridade refere-se ao número de argumentos ou operandos que uma função pode ter.
Para definir a forma e os locais dos kernels, use os atributos KernelShape, Stride, Padding, LowerPad e UpperPad:
KernelShape: (obrigatório) Define a dimensionalidade de cada kernel para o bundle convolucional. O valor deve ser uma tupla de inteiros positivos com um comprimento igual à aridade do feixe. Cada componente desta tupla não deve ser maior do que o componente correspondente de InputShape.
Stride: (opcional) Define os tamanhos dos degraus deslizantes da convolução (um tamanho de passo para cada dimensão), ou seja, a distância entre os nós centrais. O valor deve ser uma tupla de inteiros positivos com um comprimento que é a aridade do feixe. Cada componente desta tupla não deve ser maior do que o componente correspondente do KernelShape. O valor padrão é uma tupla com todos os componentes iguais a um.
Partilha: (opcional) Define a partilha de peso para cada dimensão da convolução. O valor pode ser um único valor booleano ou uma tupla de valores booleanos com um comprimento que é a aridade do feixe. Um único valor booleano é estendido para ser uma tupla do comprimento correto com todos os componentes iguais ao valor especificado. O valor padrão é uma tupla que consiste em todos os valores True.
MapCount: (opcional) Define o número de mapas de feição para o pacote convolucional. O valor pode ser um único inteiro positivo ou uma tupla de inteiros positivos com um comprimento que é a aridade do feixe. Um único valor inteiro é estendido para ser uma tupla do comprimento correto com os primeiros componentes iguais ao valor especificado e todos os componentes restantes iguais a um. O valor predefinido é um. O número total de mapas de feição é o produto dos componentes da tupla. A fatoração desse número total entre os componentes determina como os valores do mapa de feição são agrupados nos nós de destino.
Pesos: (opcional) Define os pesos iniciais para o pacote. O valor deve ser uma tupla de valores de ponto flutuante com um comprimento que é o número de kernels vezes o número de pesos por kernel, conforme definido mais adiante neste artigo. Os pesos padrão são gerados aleatoriamente.
Há dois conjuntos de propriedades que controlam o preenchimento, sendo as propriedades mutuamente exclusivas:
Preenchimento: (opcional) Determina se a entrada deve ser preenchida usando um esquema de preenchimento padrão. O valor pode ser um único valor booleano, ou pode ser uma tupla de valores booleanos com um comprimento que é a aridade do pacote.
Um único valor booleano é estendido para ser uma tupla do comprimento correto com todos os componentes iguais ao valor especificado.
Se o valor de uma dimensão for True, a fonte será logicamente acolchoada nessa dimensão com células de valor zero para suportar aplicações de kernel adicionais, de modo que os nós centrais do primeiro e do último kernels nessa dimensão sejam o primeiro e o último nós nessa dimensão na camada de origem. Assim, o número de nós "fictícios" em cada dimensão é determinado automaticamente, para encaixar exatamente
(InputShape[d] - 1) / Stride[d] + 1kernels na camada de fonte acolchoada.Se o valor de uma dimensão for False, os kernels são definidos de modo que o número de nós de cada lado que ficam de fora seja o mesmo (até uma diferença de 1). O valor padrão desse atributo é uma tupla com todos os componentes iguais a False.
UpperPad e LowerPad: (opcional) Proporcionam um maior controlo sobre a quantidade de preenchimento a utilizar. Importante: Esses atributos podem ser definidos se e somente se a propriedade Padding acima não estiver definida. Os valores devem ser tuplas com valor inteiro com comprimentos que são a aridade do feixe. Quando esses atributos são especificados, nós "fictícios" são adicionados às extremidades inferior e superior de cada dimensão da camada de entrada. O número de nós adicionados às extremidades inferior e superior em cada dimensão é determinado por LowerPad[i] e UpperPad[i], respectivamente.
Para garantir que os kernels correspondam apenas a nós "reais" e não a nós "fictícios", as seguintes condições devem ser atendidas:
Cada componente do LowerPad deve ser estritamente inferior a
KernelShape[d]/2.Cada componente do UpperPad não deve ser maior que
KernelShape[d]/2.O valor padrão desses atributos é uma tupla com todos os componentes iguais a 0.
A configuração Padding = true permite tanto preenchimento quanto for necessário para manter o "centro" do kernel dentro da entrada "real". Isso muda um pouco a matemática para calcular o tamanho da saída. Geralmente, o tamanho de saída D é calculado como
D = (I - K) / S + 1, ondeIé o tamanho da entrada,Ké o tamanho do kernel,Sé o passo e/é a divisão inteira (arredondada para zero). Se você definir UpperPad = [1, 1], o tamanhoIda entrada é efetivamente 29 e, portantoD = (29 - 5) / 2 + 1 = 13, . No entanto, quando Padding = true, essencialmenteIé esbarrado porK - 1; daíD = ((28 + 4) - 5) / 2 + 1 = 27 / 2 + 1 = 13 + 1 = 14. Ao especificar valores para UpperPad e LowerPad , você obtém muito mais controle sobre o preenchimento do que se apenas definisse Padding = true.
Para obter mais informações sobre redes convolucionais e suas aplicações, consulte estes artigos:
- http://d2l.ai/chapter_convolutional-neural-networks/lenet.html
- https://research.microsoft.com/pubs/68920/icdar03.pdf
Pacotes de pooling
Um pacote de pool aplica geometria semelhante à conectividade convolucional, mas usa funções predefinidas para originar valores de nó para derivar o valor do nó de destino. Assim, os pacotes de pool não têm estado treinável (pesos ou vieses). Os pacotes de pool suportam todos os atributos convolucionais, exceto Sharing, MapCount e Weights.
Normalmente, os kernels resumidos por unidades de pool adjacentes não se sobrepõem. Se Stride[d] é igual a KernelShape[d] em cada dimensão, a camada obtida é a camada de pool local tradicional, que é comumente empregada em redes neurais convolucionais. Cada nó de destino calcula o máximo ou a média das atividades de seu kernel na camada de origem.
O exemplo a seguir ilustra um pacote de pooling:
hidden P1 [5, 12, 12]
from C1 max pool {
InputShape = [ 5, 24, 24];
KernelShape = [ 1, 2, 2];
Stride = [ 1, 2, 2];
}
- A aridade do feixe é 3: isto é, o comprimento das tuplas
InputShape,KernelShapeeStride. - O número de nós na camada de origem é
5 * 24 * 24 = 2880. - Esta é uma camada de pool local tradicional porque KernelShape e Stride são iguais.
- O número de nós na camada de destino é
5 * 12 * 12 = 1440.
Para obter mais informações sobre camadas de pooling, consulte estes artigos:
- https://www.cs.toronto.edu/~hinton/absps/imagenet.pdf (Ponto 3.4)
- https://cs.nyu.edu/~koray/publis/lecun-iscas-10.pdf
- https://cs.nyu.edu/~koray/publis/jarrett-iccv-09.pdf
Pacotes de normalização de resposta
A normalização da resposta é um esquema de normalização local que foi introduzido pela primeira vez por Geoffrey Hinton, et al, no artigo ImageNet Classification with Deep Convolutional Neural Networks.
A normalização da resposta é usada para auxiliar a generalização em redes neurais. Quando um neurônio está disparando em um nível de ativação muito alto, uma camada de normalização de resposta local suprime o nível de ativação dos neurônios circundantes. Isso é feito usando três parâmetros (α, β, e k) e uma estrutura convolucional (ou forma de vizinhança). Cada neurônio na camada de destino y corresponde a um neurônio x na camada de origem. O nível de ativação de y é dado pela seguinte fórmula, onde f é o nível de ativação de um neurônio, e Nx é o núcleo (ou o conjunto que contém os neurônios na vizinhança de x), conforme definido pela seguinte estrutura convolucional:
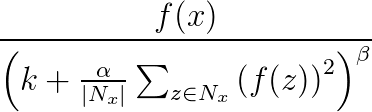
Os pacotes de normalização de resposta suportam todos os atributos convolucionais, exceto Sharing, MapCount e Weights.
Se o kernel contém neurônios no mesmo mapa que x, o esquema de normalização é referido como normalização do mesmo mapa. Para definir a mesma normalização de mapa, a primeira coordenada em InputShape deve ter o valor 1.
Se o kernel contém neurônios na mesma posição espacial que x, mas os neurônios estão em outros mapas, o esquema de normalização é chamado de normalização através de mapas. Este tipo de normalização de resposta implementa uma forma de inibição lateral inspirada no tipo encontrado em neurónios reais, criando competição por grandes níveis de ativação entre saídas de neurónios computadas em diferentes mapas. Para definir a normalização entre mapas, a primeira coordenada deve ser um inteiro maior que um e não maior que o número de mapas, e o restante das coordenadas deve ter o valor 1.
Como os pacotes de normalização de resposta aplicam uma função predefinida aos valores do nó de origem para determinar o valor do nó de destino, eles não têm estado treinável (pesos ou vieses).
Nota
Os nós na camada de destino correspondem aos neurônios que são os nós centrais dos núcleos. Por exemplo, se KernelShape[d] é ímpar, então KernelShape[d]/2 corresponde ao nó central do kernel. Se KernelShape[d] for par, o nó central está em KernelShape[d]/2 - 1. Portanto, se Padding[d] for False, o primeiro e o último KernelShape[d]/2 nós não terão nós correspondentes na camada de destino. Para evitar essa situação, defina Padding como [true, true, ..., true].
Além dos quatro atributos descritos anteriormente, os pacotes de normalização de resposta também suportam os seguintes atributos:
- Alfa: (obrigatório) Especifica um valor de vírgula flutuante que corresponde à
αfórmula anterior. - Beta: (obrigatório) Especifica um valor de vírgula flutuante que corresponde à
βfórmula anterior. - Deslocamento: (opcional) Especifica um valor de ponto flutuante que corresponde à
kfórmula anterior. O padrão é 1.
O exemplo a seguir define um pacote de normalização de resposta usando esses atributos:
hidden RN1 [5, 10, 10]
from P1 response norm {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 3, 3];
Alpha = 0.001;
Beta = 0.75;
}
- A camada de origem inclui cinco mapas, cada um com uma dimensão de 12x12, totalizando 1440 nós.
- O valor de KernelShape indica que esta é uma mesma camada de normalização de mapa, onde a vizinhança é um retângulo 3x3.
- O valor padrão de Padding é False, portanto, a camada de destino tem apenas 10 nós em cada dimensão. Para incluir um nó na camada de destino que corresponde a cada nó na camada de origem, adicione Padding = [true, true, true]; e alterar o tamanho do RN1 para [5, 12, 12].
Declaração de partilha
Net# opcionalmente suporta a definição de vários pacotes com pesos compartilhados. Os pesos de quaisquer dois feixes podem ser partilhados se as suas estruturas forem as mesmas. A sintaxe a seguir define pacotes com pesos compartilhados:
share-declaration:
share { layer-list }
share { bundle-list }
share { bias-list }
layer-list:
layer-name , layer-name
layer-list , layer-name
bundle-list:
bundle-spec , bundle-spec
bundle-list , bundle-spec
bundle-spec:
layer-name => layer-name
bias-list:
bias-spec , bias-spec
bias-list , bias-spec
bias-spec:
1 => layer-name
layer-name:
identifier
Por exemplo, a seguinte declaração de compartilhamento especifica os nomes das camadas, indicando que os pesos e vieses devem ser compartilhados:
Const {
InputSize = 37;
HiddenSize = 50;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [2] {
from H1 all;
from H2 all;
}
share { H1, H2 } // share both weights and biases
- Os recursos de entrada são particionados em duas camadas de entrada de tamanho igual.
- As camadas ocultas então computam recursos de nível mais alto nas duas camadas de entrada.
- A declaração de compartilhamento especifica que H1 e H2 devem ser calculados da mesma forma a partir de suas respetivas entradas.
Alternativamente, isso pode ser especificado com duas declarações de compartilhamento separadas, da seguinte forma:
share { Data1 => H1, Data2 => H2 } // share weights
<!-- -->
share { 1 => H1, 1 => H2 } // share biases
Você pode usar o formulário curto somente quando as camadas contiverem um único pacote. Em geral, o compartilhamento só é possível quando a estrutura relevante é idêntica, o que significa que eles têm o mesmo tamanho, a mesma geometria convolucional e assim por diante.
Exemplos de uso do Net#
Esta seção fornece alguns exemplos de como você pode usar Net# para adicionar camadas ocultas, definir a maneira como as camadas ocultas interagem com outras camadas e criar redes convolucionais.
Defina uma rede neural personalizada simples: exemplo "Hello World"
Este exemplo simples demonstra como criar um modelo de rede neural que tem uma única camada oculta.
input Data auto;
hidden H [200] from Data all;
output Out [10] sigmoid from H all;
O exemplo ilustra alguns comandos básicos da seguinte maneira:
- A primeira linha define a camada de entrada (chamada
Data). Quando você usa aautopalavra-chave, a rede neural inclui automaticamente todas as colunas de feição nos exemplos de entrada. - A segunda linha cria a camada oculta. O nome
Hé atribuído à camada oculta, que tem 200 nós. Esta camada está totalmente conectada à camada de entrada. - A terceira linha define a camada de saída (chamada
Out), que contém 10 nós de saída. Se a rede neural for usada para classificação, há um nó de saída por classe. A palavra-chave sigmoid indica que a função de saída é aplicada à camada de saída.
Definir várias camadas ocultas: exemplo de visão computacional
O exemplo a seguir demonstra como definir uma rede neural um pouco mais complexa, com várias camadas ocultas personalizadas.
// Define the input layers
input Pixels [10, 20];
input MetaData [7];
// Define the first two hidden layers, using data only from the Pixels input
hidden ByRow [10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol [5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
// Define the third hidden layer, which uses as source the hidden layers ByRow and ByCol
hidden Gather [100]
{
from ByRow all;
from ByCol all;
}
// Define the output layer and its sources
output Result [10]
{
from Gather all;
from MetaData all;
}
Este exemplo ilustra vários recursos da linguagem de especificação de redes neurais:
- A estrutura tem duas camadas de entrada,
PixelseMetaData. - A
Pixelscamada é uma camada de origem para dois pacotes de conexão, com camadasByRowde destino eByCol. - As camadas
GathereResultsão camadas de destino em vários pacotes de conexão. - A camada de saída,
Result, é uma camada de destino em dois pacotes de conexão: um com a camadaGatheroculta de segundo nível como uma camada de destino e outro com a camadaMetaDatade entrada como uma camada de destino. - As camadas ocultas
ByRoweByCol, especificam a conectividade filtrada usando expressões de predicados. Mais precisamente, o nó emByRow[x, y] está conectado aos nós emPixelsque têm a primeira coordenada de índice igual à primeira coordenada do nó, x. Da mesma forma, o nó emByCol[x, y] é conectado aos nós emPixelsque têm a segunda coordenada de índice dentro de uma das segundas coordenadas do nó, y.
Definir uma rede convolucional para classificação multiclasse: exemplo de reconhecimento de dígitos
A definição da rede a seguir é projetada para reconhecer números e ilustra algumas técnicas avançadas para personalizar uma rede neural.
input Image [29, 29];
hidden Conv1 [5, 13, 13] from Image convolve
{
InputShape = [29, 29];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden Conv2 [50, 5, 5]
from Conv1 convolve
{
InputShape = [ 5, 13, 13];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [false, true, true];
MapCount = 10;
}
hidden Hid3 [100] from Conv2 all;
output Digit [10] from Hid3 all;
A estrutura tem uma única camada de entrada,
Image.A palavra-chave
convolveindica que as camadas nomeadasConv1eConv2são camadas convolucionais. Cada uma dessas declarações de camada é seguida por uma lista dos atributos de convolução.A rede tem uma terceira camada oculta,
Hid3que está totalmente conectada à segunda camada oculta,Conv2.A camada de saída,
Digit, está conectada apenas à terceira camada oculta,Hid3. A palavra-chaveallindica que a camada de saída está totalmente conectada aoHid3.A aridade da convolução é três: o comprimento das tuplas
InputShape,KernelShape,Stride, eSharing.O número de pesos por kernel é
1 + KernelShape\[0] * KernelShape\[1] * KernelShape\[2] = 1 + 1 * 5 * 5 = 26. Ou26 * 50 = 1300.Você pode calcular os nós em cada camada oculta da seguinte maneira:
NodeCount\[0] = (5 - 1) / 1 + 1 = 5NodeCount\[1] = (13 - 5) / 2 + 1 = 5NodeCount\[2] = (13 - 5) / 2 + 1 = 5O número total de nós pode ser calculado usando a dimensionalidade declarada da camada, [50, 5, 5], da seguinte forma:
MapCount * NodeCount\[0] * NodeCount\[1] * NodeCount\[2] = 10 * 5 * 5 * 5Porque
Sharing[d]é Falso apenas parad == 0, o número de kernels éMapCount * NodeCount\[0] = 10 * 5 = 50.
Agradecimentos
A linguagem Net# para personalizar a arquitetura de redes neurais foi desenvolvida na Microsoft por Shon Katzenberger (Arquiteto, Machine Learning) e Alexey Kamenev (Engenheiro de Software, Microsoft Research). Ele é usado internamente para projetos de aprendizado de máquina e aplicações que vão desde a deteção de imagens até a análise de texto. Para obter mais informações, consulte Redes neurais no estúdio de aprendizado de máquina - Introdução à rede#